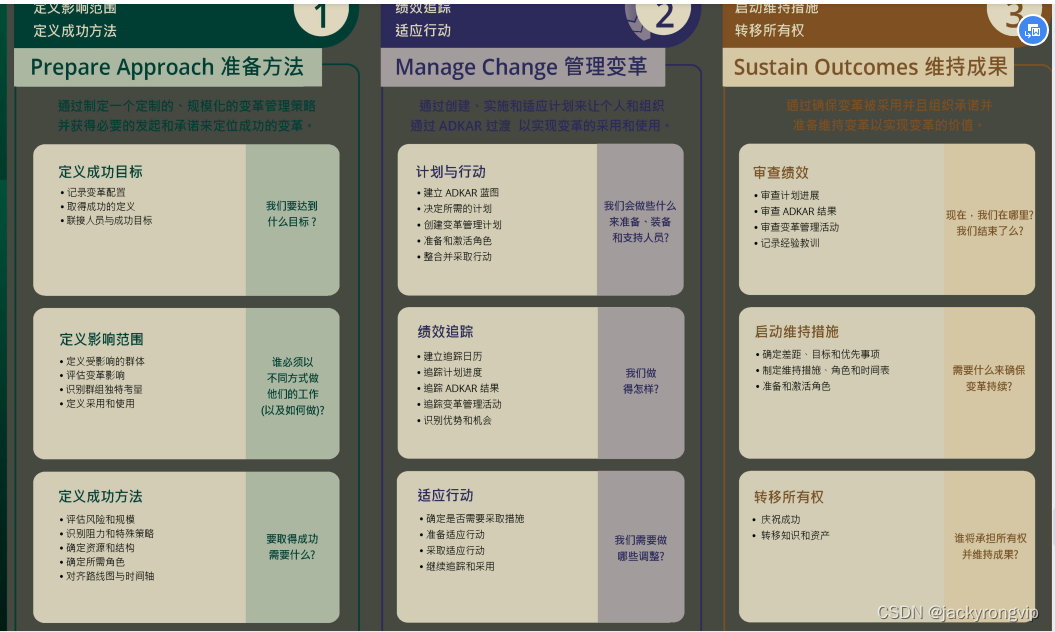
梯度累积
梯度累积(Gradient Accumulation)的基本思想是将一次性的整批参数更新的梯度计算变为以一小步一小步的方式进行(如下图),具体而言该方法以小批次的方式进行模型前向传播和反向传播,过程中迭代计算多个小批次梯度并累加,当累积到足够多的梯度时,执行模型的优化步骤更新参数。这也是一种典型的时间换空间的做法,即我们可以实现在有限的GPU内存上更新大量参数,不过额外添加的小批次前向传播和后向传播会使得训练速度变慢一些。

参数更新方式可以使用随机梯度下降(Stochastic Gradient Descent)为例进行说明:
使用global batch(即全批次)训练时,参数更新公式为:
V
t
=
V
t
−
1
−
l
r
∗
g
r
a
d
V_t=V_{t-1}-l_{r}*grad
Vt=Vt−1−lr∗grad
简化公式,
V
V
V表示参数集,
l
r
l_r
lr表示学习率,
g
r
a
d
grad
grad表示全批次梯度。
使用梯度累积的mini-batch(即小批次)训练时,参数更新公式为:
V
t
=
V
t
−
1
−
l
r
∗
∑
i
=
0
N
g
r
a
d
i
V_t=V_{t-1}-l_{r}*\sum_{i=0}^{N}grad_i
Vt=Vt−1−lr∗i=0∑Ngradi
g
r
a
d
i
grad_i
gradi表示第
i
i
i个批次反向传播时计算的梯度。
Transformers框架中开启梯度累积非常简单,仅需在TrainingArguments内指定累积步长即可:
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
trainer = Trainer(model=model, args=training_args, train_dataset=ds)
result = trainer.train()
参考文献
- Gradient Accumulation
- 聊聊梯度累加(Gradient Accumulation)
- 梯度累积算法