一、统计、去重
1、案例数据介绍
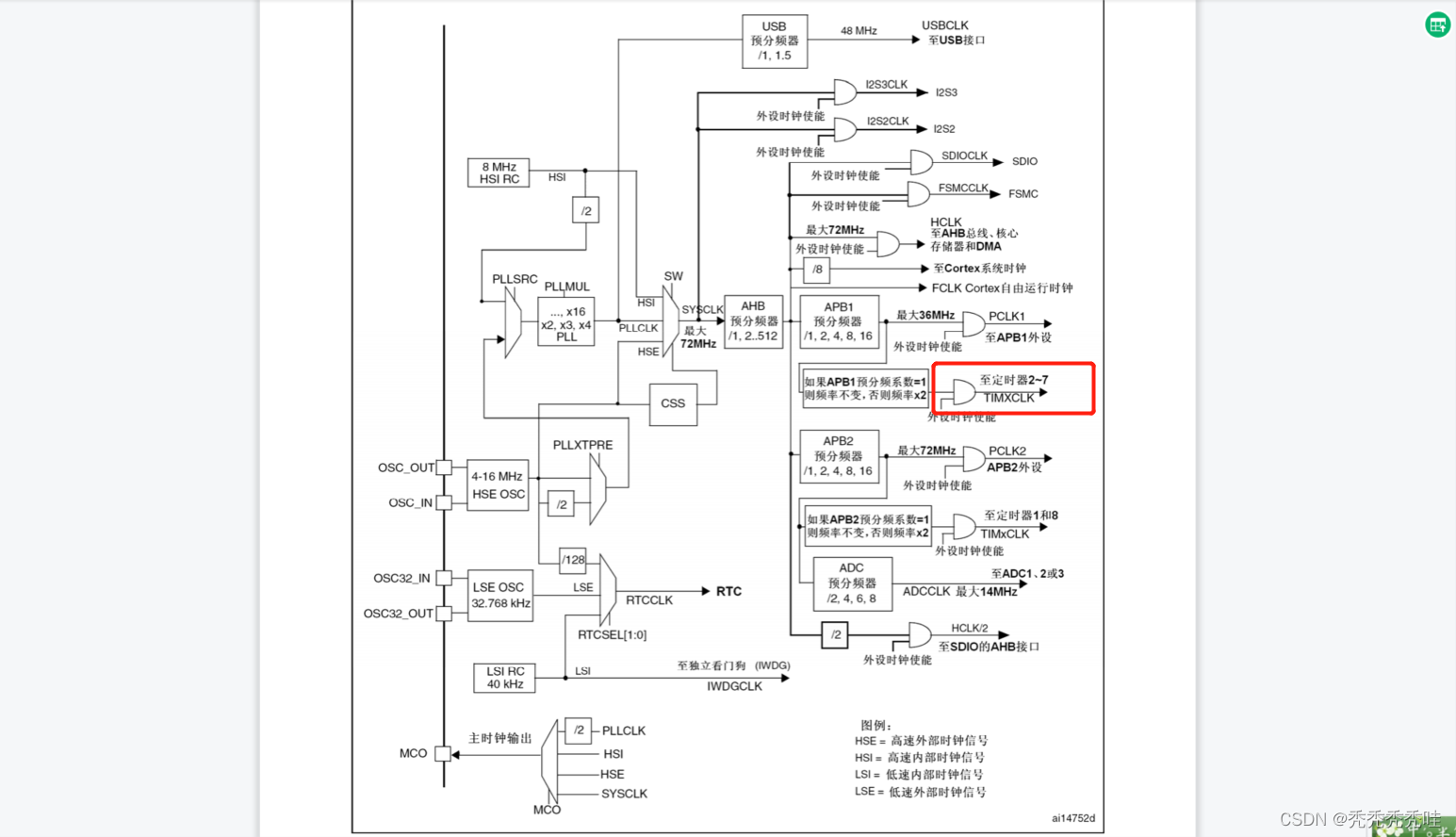
WordCount统计:某电商网站记录了大量的用户对商品的收藏数据,并将数据存储在名为buyer_favorite的文本文件中。文本数据格式如下:
2、启动spark-shell
配置好spark环境,若还没有环境可以参考SparkStandalone伪分布式的配置。
进入到spark的命令行
3、 编写Scala语句,统计用户收藏数据中,每个用户收藏商品数量。
3.1、先在spark-shell中,加载数据。
val rdd = sc.textFile("hdfs://localhost:9000/myspark3/wordcount/buy
3.2、执行统计并输出。
rdd.map(line=> (line.split('\t')(0),1)).reduceByKey(_+_).collect
解释:
1.line=>line.split(‘\t’)(0):把读到的内容按分隔符进行划分,并取(0)位置的元素
2.rdd.map(line=>(line,1)):对每个元素操作,形成新的RDD,即(line,1)
3.rdd.map(line=> (line.split(‘\t’)(0),1)):把读到的元素按分隔符划分,取0位置元素,再与1合并形成新的RDD
4.reduceByKey(+):将map后的RDD按照key进行合并,统计出value的值,并形成新的RDD
5.collect():用collect封装返回一个新数组
4、对上述实验中,用户收藏数据文件进行统计。根据商品ID进行去重,统计用户收藏数据中都有哪些商品被收藏。
rdd.map(line => line.split('\t')(1)).distinct.collect
rdd.map(line => line.split('\t')(1)).distinct.count
解释:
1.distinct([numTasks]):将原dataset中的元素去重,返回一个新的dataset
2.collect():用collect封装返回一个新数组,
3.count():返回一个数值,代表一共多少个元素
二、排序
1、案例数据介绍
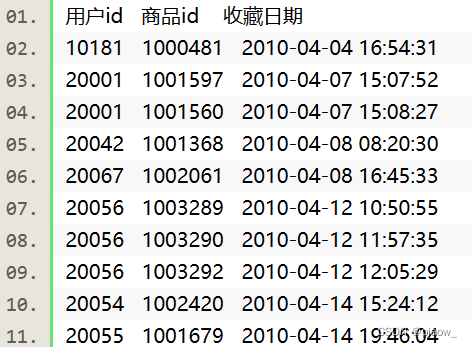
电商网站都会对商品的访问情况进行统计,现有一个goods_visit文件,存储了电商网站中的各种商品以及此各个商品的点击次数。
2、根据商品的点击次数进行排序,并输出所有商品。
2.1、在Spark窗口,加载数据,将数据转变为RDD。
val rdd1 = sc.textFile("hdfs://localhost:9000/myspark3/sort/goods_visit");
2.2、对RDD进行统计并将结果打印输出。
rdd1.map(line => ( line.split('\t')(1).toInt, line.split('\t')(0) ) ).sortByKey(true).collect
解释:
1.toInt:将数据类型由string转换成int,即数值类型
2.sortByKey:按照Key(Int数值大小)进行排序,true为升序
三、join操作
1、案例数据介绍
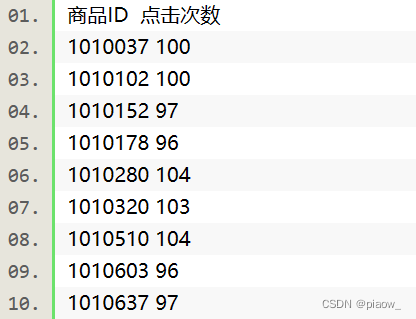
现有某电商在2011年12月15日的部分交易数据。数据有订单表orders和订单明细表order_items,表结构及数据分别为:
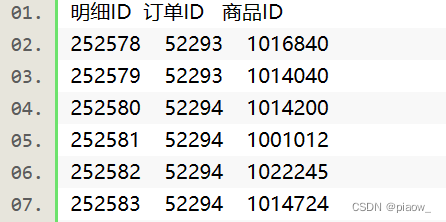
orders表和order_items表,通过订单id进行关联,是一对多的关系。
2、查询在当天该电商网站,都有哪些用户购买了什么商品
2.1、在Spark窗口创建两个RDD,分别加载orders文件以及order_items文件中的数据。
val rdd1 = sc.textFile("hdfs://localhost:9000/myspark3/join/orders");
val rdd2 = sc.textFile("hdfs://localhost:9000/myspark3/join/order_items");
2.2、我们的目的是查询每个用户购买了什么商品。所以对rdd1和rdd2进行map映射,得出关键的两个列的数据。
val rdd11 = rdd1.map(line=> (line.split('\t')(0), line.split('\t')(2)) )
val rdd22 = rdd2.map(line=> (line.split('\t')(1), line.split('\t')(2)) )
2.3、将rdd11以及rdd22中的数据,根据Key值,进行Join关联,得到最终结果。
val rddresult = rdd11 join rdd22
rddresult.collect
解释:
join:将两个同样是键值对类型的RDD,按照相同的key,连接在一起。如(K,V),(K<W)=>(k,(V,W))
结果格式化后部分展示:

四、求平均值
1、案例数据介绍
电商网站都会对商品的访问情况进行统计。现有一个goods_visit文件,存储了全部商品及各商品的点击次数。还有一个文件goods,记录了商品的基本信息。两张表的数据结构如下:
goods表:商品ID(goods_id),商品状态(goods_status),商品分类id(cat_id),评分(goods_score)
goods_visit表:商品ID(goods_id),商品点击次数(click_num)
商品表(goods)及商品访问情况表(goods_visit)可以根据商品id进行关联。
2、现在统计每个分类下,商品的平均点击次数是多少
2.1、在Spark窗口创建两个RDD,分别加载goods文件以及goods_visit文件中的数据。
val rdd1 = sc.textFile("hdfs://localhost:9000/myspark3/avg/goods")
val rdd2 = sc.textFile("hdfs://localhost:9000/myspark3/avg/goods_visit")
2.2、我们的目的是统计每个分类下,商品的平均点击次数,我们可以分三步来做。
首先,对rdd1和rdd2进行map映射,得出关键的两个列的数据。
val rdd11 = rdd1.map(line=> (line.split('\t')(0), line.split('\t')(2)) )
val rdd22 = rdd2.map(line=> (line.split('\t')(0), line.split('\t')(1)) )
然后,将rdd11以及rdd22中的数据根据商品ID,也就是key值进行关联,得到一张大表。表结构变为:(商品id,(商品分类,商品点击次数))
val rddjoin = rdd11 join rdd22
结果格式:[商品id,(分类,点击次数)]
最后,在大表的基础上,进行统计。得到每个分类,商品的平均点击次数。
scala> rddjoin.map(x=>{(x._2._1, (x._2._2.toLong, 1))}).reduceByKey((x,y)=>{(x._1+y._1, x._2+y._2)}).map(x=>
{(x._1, x._2._1*1.0/x._2._2)}).collect
解释:
1.rddjoin.map(x=>{(x._2._1, (x._2._2.toLong, 1))}):对于Array[(String, (String, String))] 类型的数据,下标是从1开始的,x._2._1代表(String,String)里的第一个String,后面类推。最后输出格式 [分类,(商品点击次数,1)]
2.reduceByKey((x,y)=>{(x._1+y._1, x._2+y._2)}):这里说明下(x,y)代表的是第一行内容x:(商品点击次数,1)和第二行内容y(商品点击次数,1) ,因此整个表达式代表以商品分类为key,分别对点击次数和商品个数作统计。最后输出格式 [分类,(点击次数,分类里商品的总个数)]
string,long,int
3.map(x=> {(x._1, x._2._1*1.0/x._2._2)}):x._1为分类,x._2._1 * 1.0 / x._2._2 为点击次数/商品总个数。最后输出格式为[String,Double],从而得到每个分类,商品的平均点击次数。
写在文末
对Spark- API开发感兴趣的,如果觉得我写的文章还不那么烂,可以参考我的下篇博文~








![[kafka] windows下安装kafka(含安装包)](https://img-blog.csdnimg.cn/dd8daf51ea9947a5bb9f76522ee2ce83.png)