国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称 ACL)是自然语言处理(NLP)领域的顶级国际会议,ACL 2023 将于2023年7月9-14日在加拿大多伦多举行。随着人工智能技术的快速发展,确保相关技术能被人们信赖是一个需要攻坚的问题。微软亚洲研究院也在不断推进负责任的人工智能的探索发现与应用实践。今天我们为大家带来3篇微软亚洲研究院以负责任的人工智能为主题入选 ACL 2023 的论文。
DuNST: 基于噪声对偶自学习的半监督可控文本生成

论文链接:https://arxiv.org/abs/2212.08724
近年来,随着大语言模型(LLMs)的广泛应用,构建负责任的人工智能成为了一个重要的课题。生成没有偏见、无毒性的文本是生成式模型的基本要求。作为自然语言处理(NLP)领域的经典和热点任务,可控文本生成在文本去毒去偏上有着重要的应用。近来大型预训练语言模型中许多 NLP 任务采用的主流方法是微调,然而,模型大小的增加需要更多的训练数据,标注数据的严重不足将导致微调结果不稳定。自学习(Self-Training)是解决可控文本生成数据稀缺问题的有效手段,并逐渐引起了研究者的重视。在每一轮迭代过程中,自学习使用分类器为未标注数据生成伪标签,再使用增强的数据重新迭代训练分类器。通过这种方式,自学习能够利用未标注数据进一步改进分类边界,提高在真实数据上的泛化性。
既有研究主要针对自学习文本分类任务进行提升,但将自学习应用于可控文本生成仍然存在诸多挑战。首先,某一类特定类别的文本数据可能是空白。其次,仅通过自动生成的伪文本进行增强,先前学习的文本空间将被过度利用,因此,模型会忽视其他文本空间,导致文本空间的崩溃以及文本生成质量的恶化。
为了解决上述问题,研究员们提出了一种新颖的自学习框架 DuNST。DuNST 将文本生成和分类作为对偶过程进行联合建模,并且通过自学习来改进模型的生成和分类。除了生成器生成的伪文本之外,研究员们还利用分类器给未标注的文本做伪标注。另外,模型会通过添加两种平滑的噪声来扰动学到的文本空间。添加的噪声可以帮助模型改进文本空间的局部平滑性,增加模型的鲁棒性。理论上,DuNST 可以被看作是对探索(Exploration)和利用(Exploitation)的平衡。添加噪声增强了对潜在更大的真实文本空间的探索,同时保持了对已经学到的文本空间的利用,从而保证模型的性能。
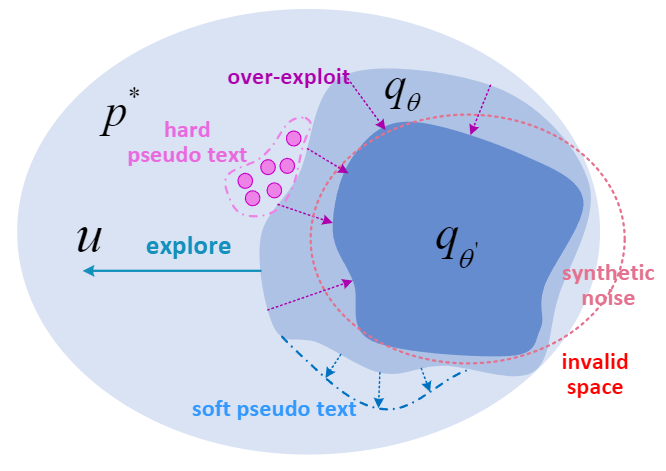
图1:DuNST 通过自学习和添加噪声维持利用和探索的平衡。
对三个半监督可控生成任务的实验结果显示,与传统的自学习方法相比,DuNST 显著提高了控制准确性和文本生成的多样性,并保持了生成的流畅度和泛化性。在文本去毒任务上,和微调基线模型(如 GPT2, UniLM 等)相比,DuNST 显著降低了生成文本约60%的毒性,并保持了较高的生成质量。该方法为文本去毒提供了一种低成本的有效方案。
EmbMarker: 通过后门水印保护基于大模型的向量表示服务的版权

论文链接:https://arxiv.org/abs/2305.10036
代码链接:https://github.com/yjw1029/EmbMarker
LLMs 在文本理解和生成方面表现了出强大的能力。因此,许多公司开始基于这些 LLMs 提供向量表示服务(EaaS),以帮助客户完成各种 NLP 任务。然而,现有的研究表明,用户可以通过发送查询和接收输出来重建模型的参数,这使得 LLM 的服务提供者面临着模型被盗用或复制的风险。
水印是常用的模型版权保护方法。然而,现有的水印都不适用于 EaaS。因此,有必要提出一种适用于 EaaS 的水印方法。这类方法需要满足以下条件:1. 不影响向量在下游任务的使用性能;2. 当有盗用者复制提供商的模型并提供相同的竞争服务时,提供商可以通过访问盗用者的服务验证其输出中含有提供商的水印;3. 水印需要足够隐蔽,不会被盗用者轻易地过滤掉。
为了解决这些问题,研究员们提出了一种基于后门水印的方法:EmbMarker。EmbMarker 包含两个阶段:水印插入阶段和版权验证阶段。在水印插入阶段,研究员们首先找到一组合适词频的单词作为触发单词,并预定义一个目标向量作为水印。当用户提供的句子中含有的触发单词数量越多时,服务提供者发送的向量与预定义的目标向量的距离越接近。在版权验证阶段,提供商可以使用触发单词和非触发单词分别构造两组句子,并访问待验证的服务得到两组向量。两组向量离目标向量的距离分布差距越大,则说明该服务后的模型越有可能是盗用或复制了提供商的模型。在多个数据集上的实验结果表明,EmbMarker 可以在不影响向量在下游任务性能的情况下,以高置信度验证盗用者服务中的水印,并且具有很强的隐蔽性。
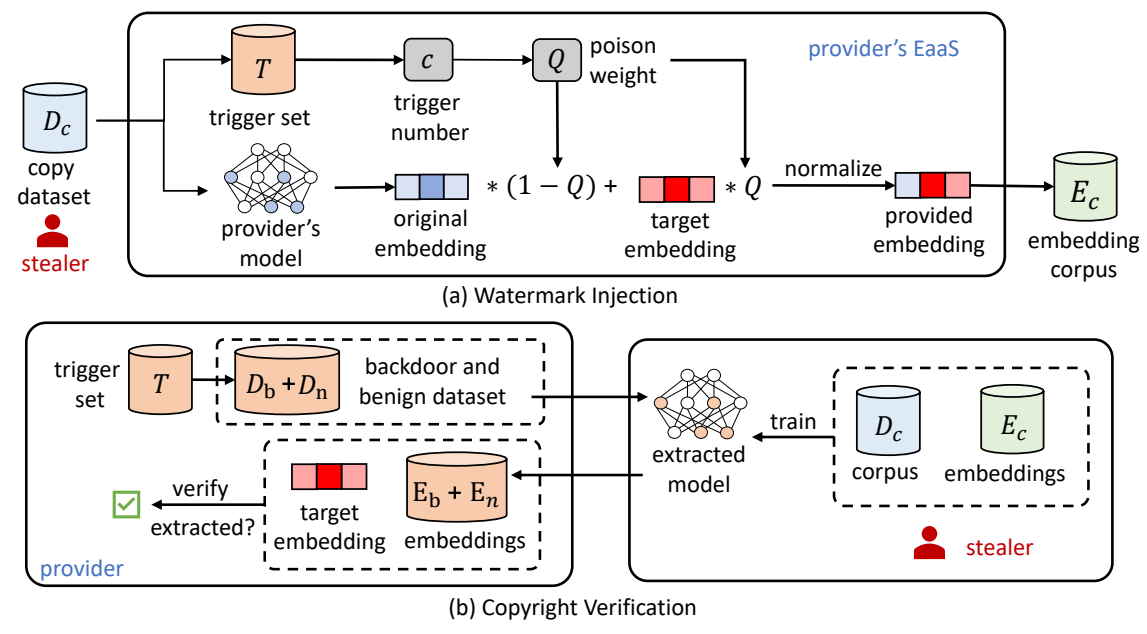
图2:EmbMarker 的框架
GLUE-X:基于分布外泛化的自然语言理解模型测试集

论文链接:https://arxiv.org/abs/2211.08073
机器学习的许多领域都面临着一个共同的难题:评估。近些年来,虽然机器学习取得了很多进展,但随着研究的深入,研究人员发现这些进展的泛化性并不如预期的优秀。传统语言模型的评估大多依赖于 GLUE 排行榜。截止至2022年,已经有超过20个单模型的结果在 GLUE 的测评上优于人工测评的表现。过去的工作证明了模型的表现并不是真正超过了人类,而是依靠伪特征(spurious features)和捷径学习(shortcut learning)取得了虚高的成绩。因此在模型拟合能力大大提升的今天,依靠传统 in-domain test 的 GLUE 榜单在实践中作为评估指标的实际价值较低。所以需要靠分布外泛化(Out of Distribution, OOD)来测试模型真正的泛化能力。以往的泛化评估通常是研究者自行选择数据集在1-2个任务上进行测试,缺乏 GLUE-X 这样全面评估模型泛化能力的基准。不同于 GLUE,当前最好的模型在 GLUE-X 表现仍明显逊于人类(74.6% vs. 80.4%)。
什么是分布外泛化?
假设有一个带标签的数据集合。通过从分布 P_train 中对 D 进行采样,生成一个训练数据集 D_train = {(X_train, Y_train)}。测试数据集 D_test = {(X_test, Y_test)} 是从 D 中按照分布 P_test 进行采样得到的。当 P_train ≠ P_test 时,称之为分布外泛化。
而且在人工智能得以广泛运用的今天,构建负责任的人工智能需要模型具备足够的鲁棒性。但在 NLP 的过往研究中,OOD 并没有得到足够的关注且缺乏统一的评估基准,这限制了 NLP 系统在真实世界中的应用。
为了构建针对模型泛化能力的统一基准,研究员们创建了一个名为 GLUE-X 的评测榜单。首先,研究员们以 GLUE 上囊括的数据集作为领域内训练集,在8个文本分类任务上,构建了14个用于 OOD 测试的文本数据集。然后,又在21个常用的预训练模型(包括 InstructGPT 和 GPT 3.5)上利用领域内的训练集进行调参,得到领域内最佳性能的模型后,再在 OOD 文本数据集进行测试,以 OOD 数据上的表现作为模型泛化能力的指标,同时提供人类测评的结果作为参照。此外,研究员们还比较了不同的微调方式对模型泛化性能的影响,并利用 Rationale “事后分析”了模型在 OOD 数据上作出判断的理性依据,并与人工标注的数据进行比对分析,以帮助研究人员理解模型泛化能力的来源。

如图3所示,研究员们对每一个 GLUE 中出现的任务构建了对应的 OOD 数据。例如,对情感分析 SST-2 数据,选取了 IMDB、Yelp、Amazon 和 Flipkart 作为测试数据。对语法判断 COLA 数据,选取了自行收集的 Grammar Test(考题)作为测试数据。GLUE-X 总共包含十五组,超过600万条的泛化测试数据。在此基础上,研究员们对常见的 PLM 进行了全数据测试。亦对 InstructGPT 和 ChatGPT进行了采样测试。

图3:不同 OOD 任务的测试结果
实验结果显示:
(1) 无论是最佳的有监督学习模型,还是 ChatGPT 大模型,在 GLUE-X 上的表现都远远低于人类。值得注意的是,人工测评也是在 OOD 条件下进行的(仅给人类 in-domain 的数据作为培训范例)。
(2) 没有一种模型能领跑所有任务,这与计算机视觉领域的研究结论一致。
(3) 模型架构 OOD 鲁棒性的影响比模型参数大小更为重要。模型的结构对于处理未预料到的输入更具有影响力。
(4) 对于文本分类任务来说,ID 和 OOD 的性能在大多数情况下呈线性相关,即如果在已知的数据分布上表现良好,那么在未知的数据分布上也可能会有较好的表现。
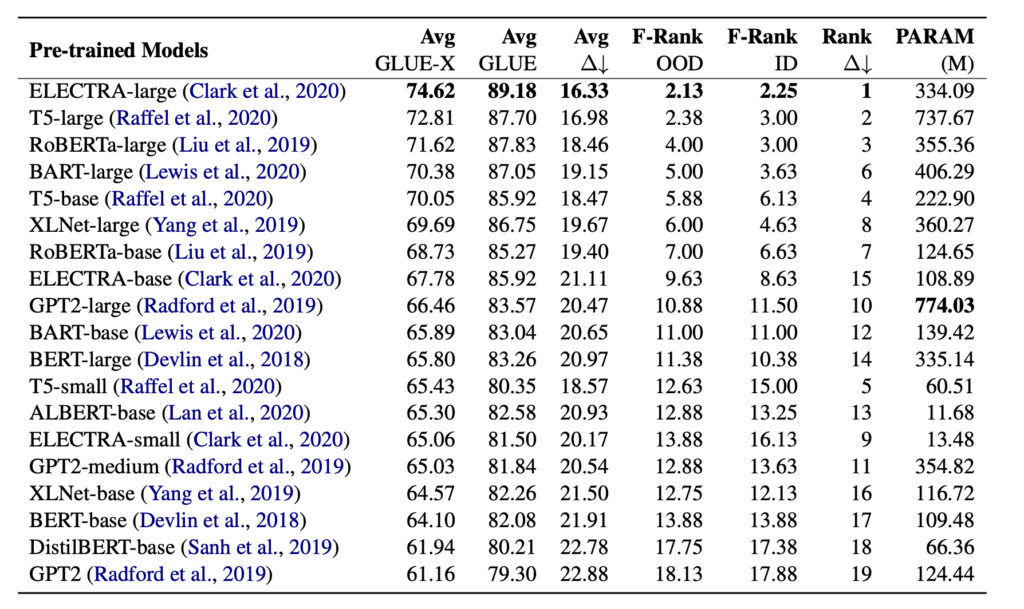
表1: 不同模型在 GLUE-X 上的表现