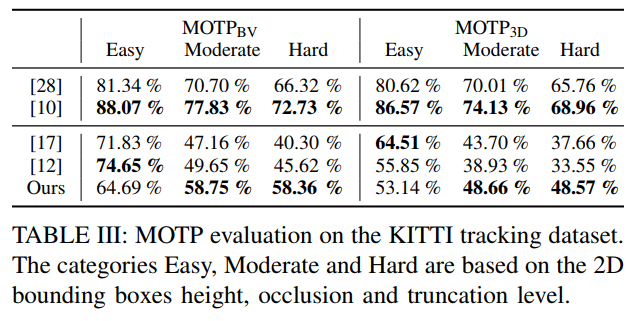
作品样式

背景需求:
即将离开班级,我想收集一份28个孩子的绘画册做——留念转学纪念册.
材料准备:

幼儿照片
——3月初到中6班拍摄的幼儿手持学号名字纸的照片(为了背诵幼儿信息而拍摄的照片,统一竖版)
生肖(鸡或狗的MJ图片,切成4格)


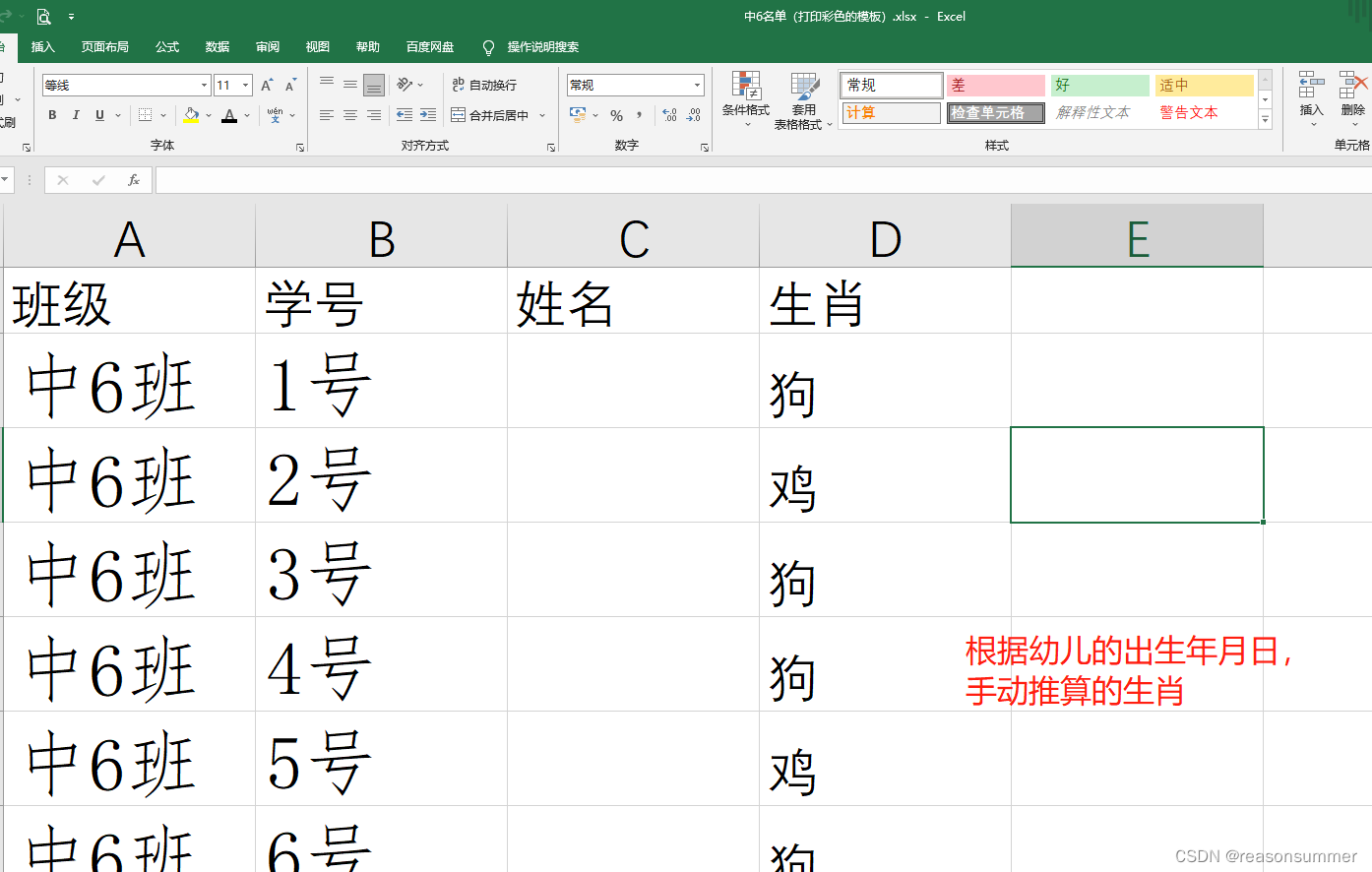
EXCLE(幼儿班级+学号+名字+生肖)
WORD模板
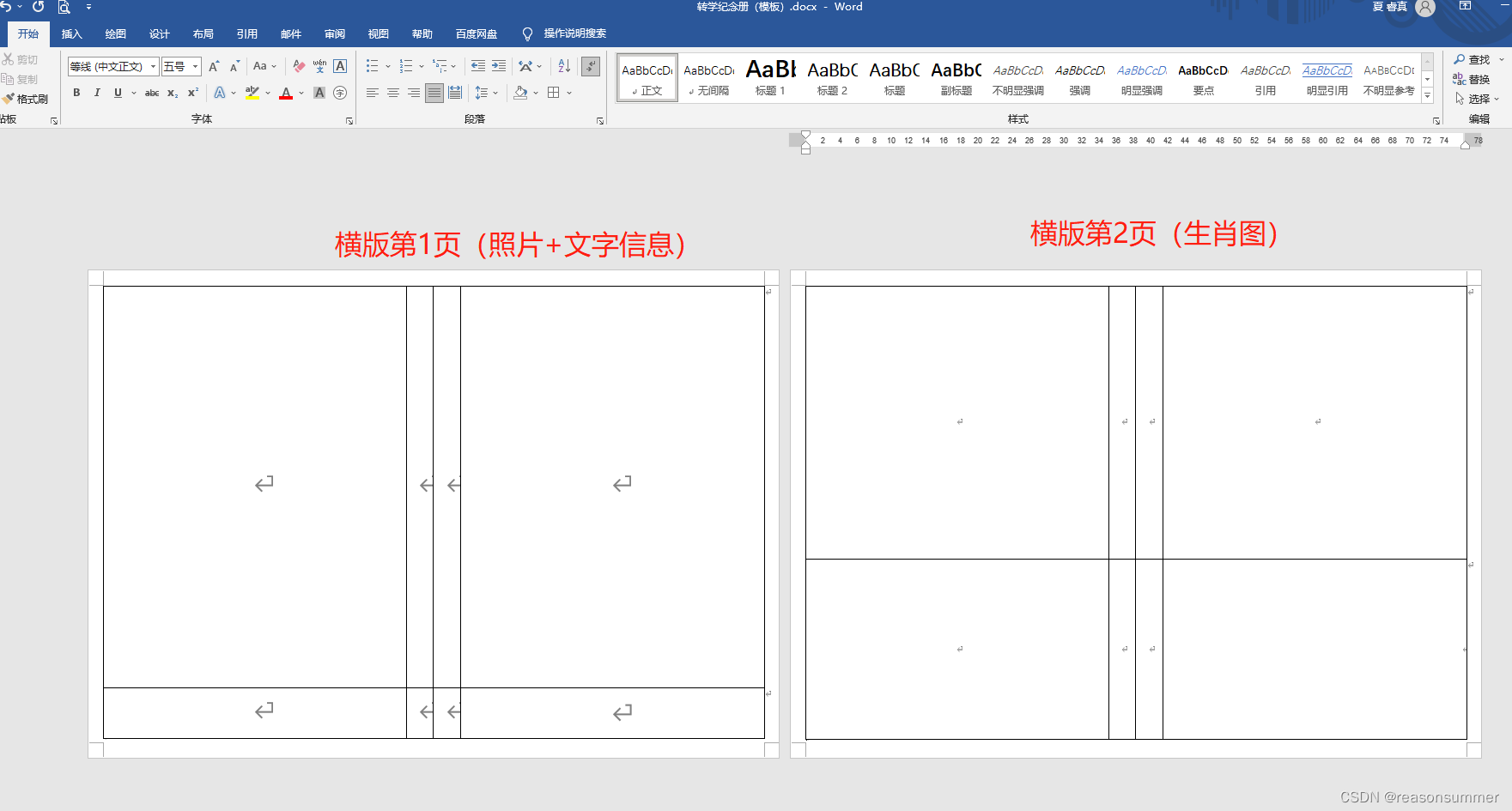
边框线隐藏(中间3竖条是装订线位置)
代码展示:
# '''
# 转学纪念册1.0(一页1份)
# 目的:
# 1、转学纪念册-绘画
# 2、第一页右侧有照片和学号
# 3、第二页,右侧底部添加生肖
# 作者:阿夏
# 时间:2023年6月22日)
# '''
print('----------第1步:提取所有的幼儿照片的路径------------')
import os
path=[]
p=r"C:\Users\jg2yXRZ\OneDrive\桌面\转学纪念册\转学纪念册"
# 过滤:只保留png结尾的图片
imgs=os.listdir(p)
for img in imgs:
if img.endswith(".png"):
path.append(p+'\\'+img)
# 所有图片的路径
print(path)
print(imgs)
# ['C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\转学纪念册\\转学纪念册\\01.jpg', 'C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\转学纪念册\\转学纪念册\\02.jpg',
# ['01.jpg', '02.jpg',
print('----------第1步:提取所有鸡图片的路径------------')
import os
path_c=[]
p_c=r"C:\Users\jg2yXRZ\OneDrive\桌面\转学纪念册\鸡"
# 过滤:只保留png结尾的图片
imgs_c=os.listdir(p_c)
for img_c in imgs_c:
if img_c.endswith(".png"):
path_c.append(p_c+'\\'+img_c)
# 所有图片的路径
print(path_c)
print(imgs_c)
print('----------第1步:提取所有狗图片的路径------------')
import os
path_d=[]
p_d=r"C:\Users\jg2yXRZ\OneDrive\桌面\转学纪念册\狗"
# 过滤:只保留png结尾的图片
imgs_d=os.listdir(p_d)
for img_d in imgs_d:
if img.endswith(".png"):
path_d.append(p_d+'\\'+img_d)
# 所有图片的路径
print(path_d)
print(imgs_d)
print('----------第2步:提取EXCLE名字学号信息------------')
import xlrd
worksheet = xlrd.open_workbook('C:\\Users\\jg2yXRZ\\OneDrive\\桌面\\转学纪念册\\中6名单(打印彩色的模板).xlsx')
sheet_names= worksheet.sheet_names()
print(sheet_names)
# 读取表1名称['Sheet1']
for sheet_name in sheet_names: # 从SHEET1 SHeet2……读取多个工作表
sheet = worksheet.sheet_by_name(sheet_name) # 这里只读取Sheet1
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
zo=[]
for l in range(rows):
row= sheet.row_values(l) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
# print(row)
name=row[0]+' '+row[1]+' '+row[2]
# print(name)
all_content.append(name)
z=row[3]
zo.append(z)
# print(all_content)
# 有第一行 班级学号姓名
info=all_content[1:]
print(info)# 没有第一行 班级学号姓名
zodiac=zo[1:]
print(zodiac)
# from PIL import Image
# tp = Image.open(r'D:\Desktop\22.png')
# tp.transpose(Image.FLIP_TOP_BOTTOM).save(r'D:\Desktop\220.png') # 上下翻转
# # 再保存一个图片文件夹(图片左右翻转)
# from PIL import Image
# tp = Image.open(r'D:\Desktop\22.png')
# tp.transpose(Image.FLIP_LEFT_RIGHT).save(r'D:\Desktop\221.png') # 左右翻转
print('----------第2步:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\转学纪念册\零时Word')
print('----------第3步:随机抽取12张图片 ------------')
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import random
import os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
# # from docx.enum.text import WD_VERTICAL_ALIGNMENT
# from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT #用来设置单元格垂直对齐方式
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
for nn in range(0,int(len(info))): # 读取图片的全路径 的数量 28张
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\转学纪念册\转学纪念册(模板).docx')
figures=path[nn] # 图片的全路径的第一张
table = doc.tables[0] # 4567(8)行
#
# 写入照片
run=doc.tables[0].cell(0,3).paragraphs[0].add_run() # # 图片位置 第一个表格的0 3 插入照片
run.add_picture(r'{}'.format(figures),width=Cm(12.59),height=Cm(16.78))
table.cell(0,3).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
# # 写入幼儿信息
k=info[nn]
run=table.cell(1,3).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文彩云字体
# run.font.size = Pt(46) #输入字体大小默认30号 换行(一页一份大卡片
run.font.size = Pt(34) #输入字体大小默认30号 一行里(可以一页两份)
run.font.bold= True #是否加粗
run.font.color.rgb = RGBColor(200,200,200) #数字小,颜色深0-255
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(1,3).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
# 写入生肖及图片
# path_c[nn]
table = doc.tables[1]
if zodiac[nn]=='鸡':
# a=path_c[nn]
# print(a)
cc=random.sample(path_c,1)
for c in cc:
print(c)
run=doc.tables[1].cell(1,3).paragraphs[0].add_run() # # 图片位置 第一个表格的0 3 插入照片
run.add_picture(r'{}'.format(c),width=Cm(7),height=Cm(7))
table.cell(1,3).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT #居中
if zodiac[nn]=='狗':
dd=random.sample(path_d,1)
for d in dd:
print(d)
run=doc.tables[1].cell(1,3).paragraphs[0].add_run() # # 图片位置 第一个表格的0 3 插入照片
run.add_picture(r'{}'.format(d),width=Cm(7),height=Cm(7))
table.cell(1,3).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.RIGHT #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\转学纪念册\零时Word\{}.docx'.format('%02d'%nn))
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/转学纪念册/零时Word/{}.docx".format('%02d'%nn) # 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/转学纪念册/零时Word/{}.pdf".format('%02d'%nn) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/转学纪念册/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/转学纪念册/(打印合集)转学纪念册1.0({}人共{}份).pdf".format(len(info),len(info)))
file_merger.close()
# doc.Close()
# print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/转学纪念册/零时Word') #递归删除文件夹,即:删除非空文件夹
终端运行:
直接运行,不要输入任何参数。
结果展示

打印过程:
1、电脑直接翻页打印后,生肖动物位置在第2页的左上角倒置。


2、因此本次打印都是先打印奇数页,然后把出来的纸张重新摆放位置,白面向上,再次塞入打印机。

3、手动塞纸。第二次打印偶数页,正好让生肖动物在第2面的右下角。


打印学具样式:


幼儿操作过程:
(开学了再补)
幼儿操作情况
1、请小朋友在空白的地方画自画像
我不会画自己
我可以画公主吗?
可以,土豆人也可以、火柴人也行
一位女孩尝试看着右边的照片,画自己(眼镜、头发)
这给我启示:以后画自画像,是否可以给孩子提供他们自己的照片,便于幼儿关注自己的特征,用几何形(圆形、方形、半圆形、线条形)表现自己的特征。
或者试试能不能用MJ 或 SD将照片转换成线条。