目录
前言
生成数据
转换成hbase能够识别的HFile文件
导入HFile到hbase中
导入数据到Mysql
总结
前言
由于想知道hbase和mysql存储同样的一份数据需要的存储是否一样,故做的一下实验。
生成数据
脚本如下:
#!/bin/bash
array_brand=([1]=huawei [2]=apple [3]=xiaomi [4]=honor)
array_color=([1]=green [2]=red [3]=white [4]=black)
array_price=([1]=5000 [2]=4899 [3]=2899 [4]=8999)
function rand(){
min=$1
max=$(($2-$min+1))
num=$(date +%s%N)
echo $(($num%$max+$min))
}
for i in `seq 1 100000`
do
num=$(rand 1 4)
brand=${array_brand[$num]}
color=${array_color[$num]}
price=${array_price[$num]}
echo "$i,$brand,$color,$price"
done
#执行sh makedata.sh >> hbaseSourceData.txt开始造数据在linux上的大小为2.2M

转换成hbase能够识别的HFile文件
- 上传至hdfs
sudo -u hdfs hadoop fs -put hbaseSourceData.txt /tmp/- 转换为HFile,表不存在的话会自动创建
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=, -Dimporttsv.columns='HBASE_ROW_KEY,cf:brand,cf:color,cf:price' -Dimporttsv.bulk.output=/tmp/output default:mysqltest /tmp/hbaseSourceData.txt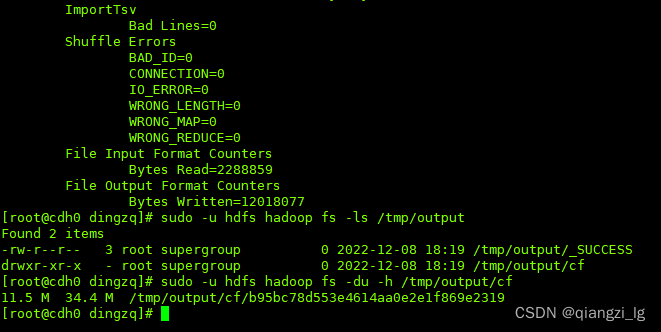
有点出乎所料,转成HFile竟然需要11.5M的存储,到这里应该就可以看出在hbase存储时的存储空间是多少了,因为hbase就是以HFile的方式存的,不过本着严谨的态度,一条道走到黑,不撞南墙不回头
导入HFile到hbase中
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /tmp/output/ default:mysqltest执行过程虽然有点小报错,但是数据还是进去了
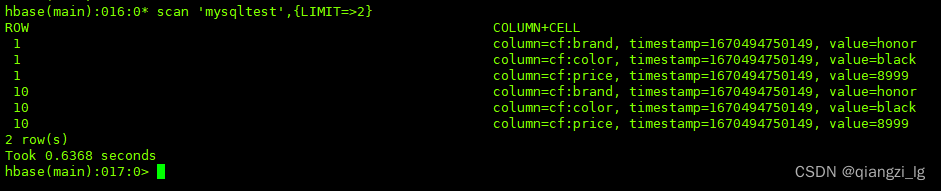
查看hbase存储大小,不出所料,就是HFile的大小

ok,接下来导入到mysql中
导入数据到Mysql
#创建mysql对应的表
create table `testhbase`(`rowkey` int,`name` varchar(200),`color` varchar(200),`price` int);#在mysql交互窗口执行,导入数据
load data local infile '/hbaseSourceData.txt' into table testhbase fields terminated by ',' (rowkey,name,color,price);#查询表占用的存储空间
select concat(round(sum(DATA_LENGTH/1024/1024),2),'MB') as data from information_schema.TABLES where table_schema = 'test' and table_name='testhbase';
总结
linux:2.2M
Hbase:11.5M
Mysql:5.52M