【推荐阅读】
概述Linux内核驱动之GPIO子系统API接口
一篇长文叙述Linux内核虚拟地址空间的基本概括
轻松学会linux下查看内存频率,内核函数,cpu频率
纯干货,linux内存管理——内存管理架构(建议收藏)
Linux 内核性能优化的全景指南,可都在这里了,强烈推荐收藏~
体系架构
dma可以在用户空间也可以在内核空间执行。
gdt(全局描述符表):所有进程的总目录表,包含每个任务的ldt和tss的地址。进程各段寻址,现场保护和恢复。
gdtr:存放gdt地址的寄存器
idt(中断描述符表):中断服务程序的入口地址。
idtr:存放idt地址的寄存器
流程:
1.bios执行实16位地址模式,检验内存磁盘等硬件,加载代码,执行初始化idt,gdt,pgd(页目录表)以及机器系统数据,为保护模式分页模式的main做准备。
2.执行start_kernel函数,初始化内存管理,文件系统,调度,时钟,设备等等。
3.启动初始化进程0,使用中断改变特权级别0操作系统层到3应用层。
4.进程0(初始化后变成idle进程), fork创建进程1。
5.进程1(init进程),fork创建进程2(kthreadd进程)。
cpu管理:
使用bitmap管理,有possible,present,online,active四种状态。
cpu分层为smt mc die
tlb和mmu
elf加载

内存屏障
1.内存乱序原因:编译器优化,多核cpu交叉访问。
2.barrier,让编译器不要优化。
3.smp_mb,保证smp多核cpu执行的顺序,屏障后的代码,invalidate cache。
mb,rmb,wmb,smp_mb,smp_rmb,smp_wmb,read_barrier_depends
内存管理

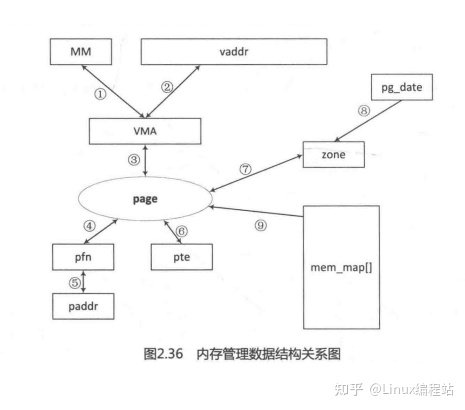
物理内存管理
1.物理内存初始化
2.node(numa)->zone
3.伙伴系统 alloc_pages
4.slab分配器 kmem_cache_create kmem_cache_alloc kmalloc
5.vmalloc分配不连续的内存。
虚拟内存管理
1.vma 遍历mm_rb红黑树,插入查找合并。
2.brk使用vma接口。
3.mmap
物理内存
4.缺页中断 do_page_fault,匿名页缺页中断
5.do_wp_page写时复制
6.page页(物理页面)引用计数,_count,_mapcount,pg_locked页面锁
7.反向映射rmap
8.kswapd回收页面
9.页面迁移migrate_pages
10.内存规整,处理内存碎片 __alloc_pages_direct_compact
11.ksm合并页面
12.oomkiller,swap
关注点
hugetlbpage,ksm,pagemap,Transparent Hugepage
进程管理
初始化相关的函数sched_init,fork_init。0号进程的内核线程栈大小是2个页8k。主线程默认大小2m或者8m平台不一样大小也不一样,线程有线程栈大小至少是2个页面,一个保存task_struct,一个保存->stack指向的空间(alloc_thread_stack_node)。
fork,vfork,clone
不管是进程还是线程,linux内核都是需要至少一个内核线程的,创建进程和线程的函数差不多,都可以使用clone,区别是参数的差别。
_do_fork->copy_process->dup_task_struct
根据不同的clone_flags参数,可以细粒度控制拷贝的对象范围:
sched_fork,copy_files,copy_fs,copy_signal,copy_mm,copy_io
然后执行生成pid或者连接线程到pid,cgroup的操作也在这里执行。
wake_up_new_task将新进程加入调度器中。
current
获取当前cpu对应的执行进程。
调度器
cfs调度是根据nice值算出权值,得出可以执行的时间。有两个时间一个是虚拟运行时间vruntime,一个是时间运行时间,cfs也有一个默认调度时间片6ms,执行时间粒度比较细,但至少有6ms。
调度切换 __schedule,切换时机:
锁,中断,主动执行schedule,系统调用,异常,cond_resched。
核心函数pick_next_task
stop_sched_class->dl_sched_class(sched_daedline)->rt_sched_class(sched_rr,sched_fifo)->fair_sched_class(sched_normal,sched_batch)->idle_sched_class(sched_idle)
优先执行实时进程,然后执行cfs调度器的进程,cfs调度器使用红黑树管理。这里还做了流水线分支优化,默认先判断当前使用的调度器是不是cfs公平调度或者idle调度。
核心切换函数context_switch
switch_mm_irqs_off:切换内存指向,切换后会有内存屏障,invalid cache。
switch_to:切换到新进程(切换的是寄存器状态和栈,使用汇编实现)。
总结:
1.每个cpu都有一个自己的struct rq队列
2.每个进程内嵌一个调度实体struct sched_entity ,sched_class,sched_rt_entity,sched_dl_entity,sched_info。
cgroup的组调度
task_group
进程管理模块调用其他模块
kmem_cache_alloc_node 通过slab.h引入,头文件在最外层的include中,模块划分很清晰。
wake_up_new_task 通过sched.h引入
红黑树实现在rbtree.h
关注点
cgroup
同步与锁操作
1.原子操作,指令实现:
ldrex Rt,[Rn] //将Rn寄存器指向地址的内容加载到Rt寄存器中
strex Rd,Rt,[Rn] //Rt寄存器值保存到Rn指向的地址中,Rd保存更新结果。0成功,1失败。
2.spinlock自旋锁,numa下存在公平性问题,L1 cache引起的,改良后变成排队自旋锁。改良后仍然存在缓存行颠簸现象(多个cpu的cacheline反复失效)。需要关闭抢占。spin_lock_irq还会关闭中断。新版本使用raw_spin_lock,保证不被抢占和睡眠。
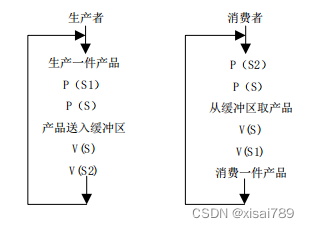
3.信号量,pv操作,允许进程进入睡眠状态。sema_init初始化,计数器使用spinlock来锁定,如果需要睡眠调用schedule_timeout。
4.mutex互斥锁,可以自旋等待一段时间,睡眠之前尝试获取锁,mcs机制保证只有一个人自旋等待或者释放锁。mcs可以解决缓存行颠簸,核心思想是只在本地cpu自旋,全局的不自旋。
5.读写锁,可以是spinlock类型也可以是信号量类型。
6.rcu(read copy update),使用限制:受保护资源必须通过指针访问,例如链表。读无开销,写有开销,无锁编程。
中断
软中断:分上下部分
tasklet:软中断下半部分
workqueue:也是下半部机制
文件系统
vfs
inode结构体可以描述目录和文件。
特殊文件系统
/proc 进程的实时信息和配置信息。
/sys
内核的网络模块
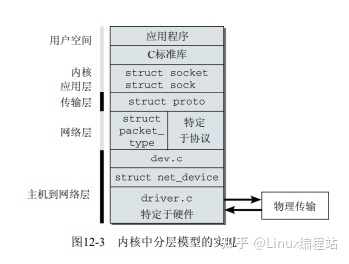
sk_buff 套接字缓冲
napi
netfilter
netlink:取代ioctl
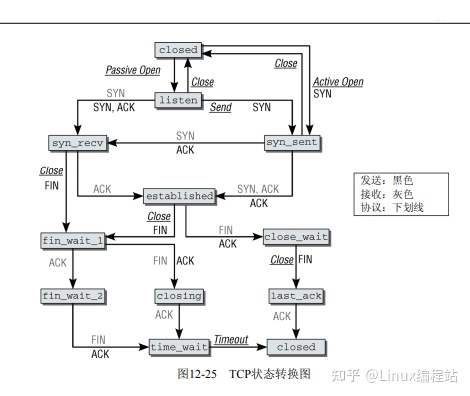
进程间通信
strace ptrace跟踪系统调用
其他
gdt ldt idt tr
pgd pmd pte
TLB地址变换高速缓存
mesi
alloc_pages分配物理页
vmalloc分配虚拟页,64位系统一般没有高端内存
malloc调用brk,按页分配vma,是虚拟内存,内部自己维护内存池,free,不立刻释放
kmalloc内核内部使用,使用slab对象的内存,slab着色区为了提高cacheline命中
32位系统使用高端内存可以使用vmalloc(high_mem)或者使用kmap永久或者临时映射
64位系统一般全部用线性映射就足够
物理内存分配alloc_page()分配一页使用per_cpu_pageset,大于一页会用到buddy系统分配
物理内存初始化分成zonedma,zonenormal,zonehighmem
smp每个cpu有自己的独立内存区,但是大部分内存都是共享的
numa每个内存划分到每个cpu上,优先访问本地内存,不够才使用其他cpu的内存
mpp基本相当于多个cpu独立工作
vma挂在task_stuct的mm_struct上,属于进程,内存虚拟地址都是在用户空间
mmap可以将用户空间的地址映射到和内核地址同一块物理内存,一段时间刷盘
vma使用链表+红黑树存储
page cahe:文件的内存缓存
kswapd页面回收,每个numa节点有一个kswapd线程,按zone回收,每个zone有一个lru链表
伙伴系统从zone_high到zone_normal分配内存,kswapd则从zone_normal到zone_high回收内存
如果内存碎片很多,kswapd会进行内存规整
pgd(10)-pmd(0)-pte(10)-page-物理页面(匿名页面,page cache)
task_struct->mm_struct->pgd/vma_areastruct
sched_fifo sched_rr 实时调度 优先级0-99 ,sched_normal sched_batch 普通调度cfs调度器优先级 100-139,sched_idel sched_daedline static_prio ->普通进程的优先级,根据normal_prio计算出来,不会动态变化;rt_priority->实时进程的优先级,独立的prio某些情况可动态提高,如实时互斥量,是调度类考虑的优先级nice值-20到19 对应的weight 88761到15,nice值越低优先级越高实时进程都跑完了状态变成空闲才会轮到普通进程调度。
多核cpu,使用多线程可以访问的变量时需要注意变量的取值,加上volatile能保证获取到最新的值,atomic原子变量也会从内存读取(arm 原子变量使用三个寄存器读取值volatile,都需要从内存重新读,cache每次读取写入都刷新最新的,smp多核的情况下使用LDREX STREX指令,操作失败会重新操作,锁的实现也有这部分;intel使用lock前缀,猜测直接使用mesi缓存锁可实现:理论上cpu1,cpu2都要执行原子操作,cpu1将本地cache修改后通知invalidate并把自己改成m,cpu2想写入发现自己是i就会失败重新执行)
spinlock自旋锁忙等待,信号量和mutex互斥锁则可能会进入睡眠,mutex会尝试自旋等待
读写锁写类似spinlock,读类似信号量;rcu读者开销小,读的过程可以拷贝一份写完成后直接切换指针,等读者读完后原来的数据销毁原来的数据
1.文件锁flock
2.gdt(全局描述符表)每个cpu有一个,ldt每个进程都可以有一份(用户空间一般共享一个);gdt定义了18个段描述符和14个空,ldt包含5个,改变特权的用途
3.mem_map保存页描述符(struct page 32字节),对应的页面属于物理页面
4.numa每个cpu核管理一块node内存(pg_data_t),每个node包含几个zone内存
5.用户态进内核两种方式,int 80和sysenter;内核退回用户态iret和sysexit;sysenter开销大概200ns,软中断大概3-5us。vdso速度更快,直接调用内核提供的动态共享库。
6.ipc共享内存可以在tmpfs查看
7.cpu访问数据先找L1cache(存虚拟地址),找不到mmu如果有tlb就找tlb,没有mmu通过映射表查找到物理地址(需要访问映射表内存),找到后找L2cache里有没有对应的物理地址,找不到就需要访问物理内存,然后存回L2,L1和tlb
发展中的技术
opencapi和pcie竞争的一种新型技术,运行cpu,fpga等任意芯片接入。
infiniband,rdma
内核开发调试工具
kcov gcov 性能分析
kasan 内存分析
kgdb 调试
Kmemleak 内存泄漏分析
kselftest 测试框架
Sparse 静态代码检查
UBSAN 运行时未定义行为检测
kdump
总结:基本上内核工具和应用层的工具功能差不多。
内核全景图








![[附源码]Python计算机毕业设计Django-中国传统手工艺销售平台](https://img-blog.csdnimg.cn/8ef98439179a44118e1285446de01e50.png)



![[附源码]Python计算机毕业设计Django在线影院系统](https://img-blog.csdnimg.cn/96950f8b6b57476cbfb3b57398eee355.png)
![[附源码]计算机毕业设计JAVA中小学微课学习系统](https://img-blog.csdnimg.cn/c08e2fb567794d0b82fffb3eebdc2247.png)