在【机器学习15】中,笔者介绍了神经网络的基本原理。在本篇中,我们使用 TensorFlow 来训练、验证神经网络模型,并探索不同 “层数+节点数” 对模型预测效果的影响,以便读者对神经网络模型有一个更加直观的认识。
目录
1.导入依赖模块
2.加载数据集
3.表示数据
4.构建线性回归模型-作为基线
4.1 定义损失打印函数
4.2 定义函数以创建和训练线性回归模型
4.3 定义线性回归模型输出
4.4 调用函数训练、测试模型
4.5 完整代码运行
5.深度神经网络模型
5.1 定义深度神经网络(DNN)模型
5.2 调用函数来构建和训练深度神经网络
5.3 优化深度神经网络的拓扑结构
5.3.1 实验一:增加层数
5.3.2 实验一:减少节点数
6.两种模型结果对比
7.参考文献
1.导入依赖模块
相较于前面的系列文章,需要新增一个模块 seaborn。可以通过 PyCharm 的图形化工具安装,也可以通过命令“pip3 install --index-url https://mirrors.aliyun.com/pypi/simple/ seaborn” 直接安装。
import numpy as np
import pandas as pd
import tensorflow as tf
from matplotlib import pyplot as plt
import seaborn as sns
# The following lines adjust the granularity of reporting.
pd.options.display.max_rows = 10
pd.options.display.float_format = "{:.1f}".format2.加载数据集
本案例中采用的数据集原始地址为如下:
- 训练数据:https://download.mlcc.google.com/mledu-datasets/california_housing_train.csv
- 测试数据:https://download.mlcc.google.com/mledu-datasets/california_housing_test.csv
我们需要将上述数据下载到本地,然后将其路径(数据文件在你电脑的实际路径)写入代码中,如下代码所示:
# 载入数据集
train_df = pd.read_csv("/Users/jinKwok/Downloads/california_housing_train.csv")
test_df = pd.read_csv("/Users/jinKwok/Downloads/california_housing_test.csv")
# 打乱训练数据示例
train_df = train_df.reindex(np.random.permutation(train_df.index))
3.表示数据
以下代码单元创建输出三个特征的预处理层:
-
cross_latitude_longitude:纬度 X 经度(特征交叉)
-
median_income:收入中位数;
-
population:人口
其中指定了最终用于训练模型的特征,以及这些特征的表示形式。在向转换传递 DataFrame 之前,转换(收集在 presecuring_layers 中)实际上不会被应用,在我们训练模型时才会真正被应用。我们将对线性回归模型和神经网络模型使用预处理层。
# Keras 构建浮点值输入张量
inputs = {
'latitude':
tf.keras.layers.Input(shape=(1,), dtype=tf.float32,
name='latitude'),
'longitude':
tf.keras.layers.Input(shape=(1,), dtype=tf.float32,
name='longitude'),
'median_income':
tf.keras.layers.Input(shape=(1,), dtype=tf.float32,
name='median_income'),
'population':
tf.keras.layers.Input(shape=(1,), dtype=tf.float32,
name='population')
}
# 创建一个规范化(归一化)层来规范 median_income 数据
median_income = tf.keras.layers.Normalization(
name='normalization_median_income',
axis=None)
median_income.adapt(train_df['median_income'])
median_income = median_income(inputs.get('median_income'))
# 创建一个规范化(归一化)层来规范 population 数据
population = tf.keras.layers.Normalization(
name='normalization_population',
axis=None)
population.adapt(train_df['population'])
population = population(inputs.get('population'))
# 创建一个数字列表,表示纬度分桶的边界。
# 因为我们使用的是归一化层,所以纬度和经度的值将在大约-3到3的范围内(表示Z分数)。
# 我们将创建20个bucket(桶),这需要21个bucket边界(因此是20+1)。
latitude_boundaries = np.linspace(-3, 3, 20 + 1)
# 创建一个规范化(归一化)层来规范 latitude-纬度 数据
latitude = tf.keras.layers.Normalization(
name='normalization_latitude',
axis=None)
latitude.adapt(train_df['latitude'])
latitude = latitude(inputs.get('latitude'))
# 创建一个离散化层,将纬度数据分离存储到桶中
latitude = tf.keras.layers.Discretization(
bin_boundaries=latitude_boundaries,
name='discretization_latitude')(latitude)
# 创建一个数字列表,表示经度分桶的边界
longitude_boundaries = np.linspace(-3, 3, 20 + 1)
# 创建一个规范化(归一化)层来规范 longitude-经度 数据
longitude = tf.keras.layers.Normalization(
name='normalization_longitude',
axis=None)
longitude.adapt(train_df['longitude'])
longitude = longitude(inputs.get('longitude'))
# 创建一个离散化层,将经度数据分离存储到桶中。
longitude = tf.keras.layers.Discretization(
bin_boundaries=longitude_boundaries,
name='discretization_longitude')(longitude)
# 将经纬度特征交叉成一个单一的热向量
feature_cross = tf.keras.layers.HashedCrossing(
# num_bins 可以调整:值越高,精度越高;值越低,性能越高。
num_bins=len(latitude_boundaries) * len(longitude_boundaries),
output_mode='one_hot',
name='cross_latitude_longitude')([latitude, longitude])
# 将我们的输入连接到一个张量中
preprocessing_layers = tf.keras.layers.Concatenate()(
[feature_cross, median_income, population])
4.构建线性回归模型-作为基线
4.1 定义损失打印函数
# 定义损失曲线打印函数
def plot_the_loss_curve(epochs, mse_training, mse_validation):
"""打印损失和训练轮次的关系图"""
plt.figure()
plt.xlabel("Epoch")
plt.ylabel("Mean Squared Error")
plt.plot(epochs, mse_training, label="Training Loss")
plt.plot(epochs, mse_validation, label="Validation Loss")
# 由于mse_training是pandas系列,所以需先将其转换为列表
merged_mse_lists = mse_training.tolist() + mse_validation
highest_loss = max(merged_mse_lists)
lowest_loss = min(merged_mse_lists)
top_of_y_axis = highest_loss * 1.03
bottom_of_y_axis = lowest_loss * 0.97
plt.ylim([bottom_of_y_axis, top_of_y_axis])
plt.legend()
plt.show()4.2 定义函数以创建和训练线性回归模型
# 定义线性回归模型创建函数
def create_model(my_inputs, my_outputs, my_learning_rate):
model = tf.keras.Model(inputs=my_inputs, outputs=my_outputs)
# 将层构造为TensorFlow可以执行的模型
model.compile(optimizer=tf.keras.optimizers.Adam(
learning_rate=my_learning_rate),
loss="mean_squared_error",
metrics=[tf.keras.metrics.MeanSquaredError()])
return model
# 创建规范化层以归一化median_house_value数据。
# 因为median_house_value是我们的标签(即我们预测的目标值),所以这些层不会添加到我们的模型中
train_median_house_value_normalized = tf.keras.layers.Normalization(axis=None)
train_median_house_value_normalized.adapt(
np.array(train_df['median_house_value']))
test_median_house_value_normalized = tf.keras.layers.Normalization(axis=None)
test_median_house_value_normalized.adapt(
np.array(test_df['median_house_value']))
# 定义模型训练函数
def train_model(model, dataset, epochs, batch_size, label_name, validation_split=0.1):
"""将数据灌入模型以对其进行训练"""
# 将数据集拆分为特征和标签
features = {name: np.array(value) for name, value in dataset.items()}
label = train_median_house_value_normalized(
np.array(features.pop(label_name)))
history = model.fit(x=features, y=label, batch_size=batch_size,
epochs=epochs, shuffle=True, validation_split=validation_split)
# 获取有助于绘制损失曲线的详细信息
epochs = history.epoch
hist = pd.DataFrame(history.history)
mse = hist["mean_squared_error"]
return epochs, mse, history.history
4.3 定义线性回归模型输出
# 定义线性回归模型模型输出
def get_outputs_linear_regression():
# 创建密集输出层
dense_output = tf.keras.layers.Dense(units=1, input_shape=(1,),
name='dense_output')(preprocessing_layers)
# 定义一个输出字典,并发送给模型构造函数
outputs = {
'dense_output': dense_output
}
return outputs4.4 调用函数训练、测试模型
# 设置超参数
learning_rate = 0.01
epochs = 15
batch_size = 1000
label_name = "median_house_value"
# 将原始训练集拆分为训练集和验证集
validation_split = 0.2
outputs = get_outputs_linear_regression()
# 构建模型拓扑
my_model = create_model(inputs, outputs, learning_rate)
# 基于规范化后的训练集数据训练模型
epochs, mse, history = train_model(my_model, train_df, epochs, batch_size,
label_name, validation_split)
plot_the_loss_curve(epochs, mse, history["val_mean_squared_error"])
test_features = {name: np.array(value) for name, value in test_df.items()}
test_label = test_median_house_value_normalized(test_features.pop(label_name)) # isolate the label
print("\n Evaluate the linear regression model against the test set:")
my_model.evaluate(x=test_features, y=test_label, batch_size=batch_size, return_dict=True)
4.5 完整代码运行
import numpy as np
import pandas as pd
import tensorflow as tf
from matplotlib import pyplot as plt
import seaborn as sns
# The following lines adjust the granularity of reporting.
pd.options.display.max_rows = 10
pd.options.display.float_format = "{:.1f}".format
print("Imported modules.")
# 载入数据集
train_df = pd.read_csv("/Users/jinKwok/Downloads/california_housing_train.csv")
test_df = pd.read_csv("/Users/jinKwok/Downloads/california_housing_test.csv")
# 打乱训练数据示例
train_df = train_df.reindex(np.random.permutation(train_df.index))
# Keras 构建浮点值输入张量
inputs = {
'latitude':
tf.keras.layers.Input(shape=(1,), dtype=tf.float32,
name='latitude'),
'longitude':
tf.keras.layers.Input(shape=(1,), dtype=tf.float32,
name='longitude'),
'median_income':
tf.keras.layers.Input(shape=(1,), dtype=tf.float32,
name='median_income'),
'population':
tf.keras.layers.Input(shape=(1,), dtype=tf.float32,
name='population')
}
# 创建一个规范化(归一化)层来规范 median_income 数据
median_income = tf.keras.layers.Normalization(
name='normalization_median_income',
axis=None)
median_income.adapt(train_df['median_income'])
median_income = median_income(inputs.get('median_income'))
# 创建一个规范化(归一化)层来规范 population 数据
population = tf.keras.layers.Normalization(
name='normalization_population',
axis=None)
population.adapt(train_df['population'])
population = population(inputs.get('population'))
# 创建一个数字列表,表示纬度分桶的边界。
# 因为我们使用的是归一化层,所以纬度和经度的值将在大约-3到3的范围内(表示Z分数)。
# 我们将创建20个bucket(桶),这需要21个bucket边界(因此是20+1)。
latitude_boundaries = np.linspace(-3, 3, 20 + 1)
# 创建一个规范化(归一化)层来规范 latitude-纬度 数据
latitude = tf.keras.layers.Normalization(
name='normalization_latitude',
axis=None)
latitude.adapt(train_df['latitude'])
latitude = latitude(inputs.get('latitude'))
# 创建一个离散化层,将纬度数据分离存储到桶中
latitude = tf.keras.layers.Discretization(
bin_boundaries=latitude_boundaries,
name='discretization_latitude')(latitude)
# 创建一个数字列表,表示经度分桶的边界
longitude_boundaries = np.linspace(-3, 3, 20 + 1)
# 创建一个规范化(归一化)层来规范 longitude-经度 数据
longitude = tf.keras.layers.Normalization(
name='normalization_longitude',
axis=None)
longitude.adapt(train_df['longitude'])
longitude = longitude(inputs.get('longitude'))
# 创建一个离散化层,将经度数据分离存储到桶中。
longitude = tf.keras.layers.Discretization(
bin_boundaries=longitude_boundaries,
name='discretization_longitude')(longitude)
# 将经纬度特征交叉成一个单一的热向量
feature_cross = tf.keras.layers.HashedCrossing(
# num_bins 可以调整:值越高,精度越高;值越低,性能越高。
num_bins=len(latitude_boundaries) * len(longitude_boundaries),
output_mode='one_hot',
name='cross_latitude_longitude')([latitude, longitude])
# 将我们的输入连接到一个张量中
preprocessing_layers = tf.keras.layers.Concatenate()(
[feature_cross, median_income, population])
print("Preprocessing layers defined.")
# 定义损失曲线打印函数
def plot_the_loss_curve(epochs, mse_training, mse_validation):
"""打印损失和训练轮次的关系图"""
plt.figure()
plt.xlabel("Epoch")
plt.ylabel("Mean Squared Error")
plt.plot(epochs, mse_training, label="Training Loss")
plt.plot(epochs, mse_validation, label="Validation Loss")
# 由于mse_training是pandas系列,所以需先将其转换为列表
merged_mse_lists = mse_training.tolist() + mse_validation
highest_loss = max(merged_mse_lists)
lowest_loss = min(merged_mse_lists)
top_of_y_axis = highest_loss * 1.03
bottom_of_y_axis = lowest_loss * 0.97
plt.ylim([bottom_of_y_axis, top_of_y_axis])
plt.legend()
plt.show()
print("Defined the plot_the_loss_curve function.")
# 定义线性回归模型创建函数
def create_model(my_inputs, my_outputs, my_learning_rate):
model = tf.keras.Model(inputs=my_inputs, outputs=my_outputs)
# 将层构造为TensorFlow可以执行的模型
model.compile(optimizer=tf.keras.optimizers.Adam(
learning_rate=my_learning_rate),
loss="mean_squared_error",
metrics=[tf.keras.metrics.MeanSquaredError()])
return model
# 创建规范化层以归一化median_house_value数据。
# 因为median_house_value是我们的标签(即我们预测的目标值),所以这些层不会添加到我们的模型中
train_median_house_value_normalized = tf.keras.layers.Normalization(axis=None)
train_median_house_value_normalized.adapt(
np.array(train_df['median_house_value']))
test_median_house_value_normalized = tf.keras.layers.Normalization(axis=None)
test_median_house_value_normalized.adapt(
np.array(test_df['median_house_value']))
# 定义模型训练函数
def train_model(model, dataset, epochs, batch_size, label_name, validation_split=0.1):
"""将数据灌入模型以对其进行训练"""
# 将数据集拆分为特征和标签
features = {name: np.array(value) for name, value in dataset.items()}
label = train_median_house_value_normalized(
np.array(features.pop(label_name)))
history = model.fit(x=features, y=label, batch_size=batch_size,
epochs=epochs, shuffle=True, validation_split=validation_split)
# 获取有助于绘制损失曲线的详细信息
epochs = history.epoch
hist = pd.DataFrame(history.history)
mse = hist["mean_squared_error"]
return epochs, mse, history.history
print("Defined the create_model and train_model functions.")
# 定义线性回归模型模型输出
def get_outputs_linear_regression():
# 创建密集输出层
dense_output = tf.keras.layers.Dense(units=1, input_shape=(1,),
name='dense_output')(preprocessing_layers)
# 定义一个输出字典,并发送给模型构造函数
outputs = {
'dense_output': dense_output
}
return outputs
# 设置超参数
learning_rate = 0.01
epochs = 15
batch_size = 1000
label_name = "median_house_value"
# 将原始训练集拆分为训练集和验证集
validation_split = 0.2
outputs = get_outputs_linear_regression()
# 构建模型拓扑
my_model = create_model(inputs, outputs, learning_rate)
# 基于规范化后的训练集数据训练模型
epochs, mse, history = train_model(my_model, train_df, epochs, batch_size,
label_name, validation_split)
plot_the_loss_curve(epochs, mse, history["val_mean_squared_error"])
test_features = {name: np.array(value) for name, value in test_df.items()}
test_label = test_median_house_value_normalized(test_features.pop(label_name)) # isolate the label
print("\n Evaluate the linear regression model against the test set:")
my_model.evaluate(x=test_features, y=test_label, batch_size=batch_size, return_dict=True)
运行结果如下所示:

其中,基于测试集(验证集)得到的结果为:loss: 0.3608 - mean_squared_error: 0.3608
5.深度神经网络模型
5.1 定义深度神经网络(DNN)模型
如下代码单元中,get_outputs_dnn 函数定义深度神经网络(DNN)的拓扑,指定以下内容:
- 深度神经网络中的层数。
- 每个层中的节点数。
get_outputs_dnn 函数还定义了每一层的激活函数。第一个密集层将我们之前定义的预处理层作为输入。
# 定义深度神经网络模型
def get_outputs_dnn():
# 创建一个包含20个节点的密集层
dense_output = tf.keras.layers.Dense(units=20, input_shape=(1,),
activation='relu',
name='hidden_dense_layer_1')(preprocessing_layers)
# 创建一个具有12个节点的密集层
dense_output = tf.keras.layers.Dense(units=12, input_shape=(1,),
activation='relu',
name='hidden_dense_layer_2')(dense_output)
# 创建密集输出层
dense_output = tf.keras.layers.Dense(units=1, input_shape=(1,),
name='dense_output')(dense_output)
# 定义一个输出字典,并发送给模型构造函数
outputs = {
'dense_output': dense_output
}
return outputs5.2 调用函数来构建和训练深度神经网络
如下代码单元用于训练深层神经网络。我们可以调整三个超参数,看看是否可以减少测试集的损失。
# 设置超参数
learning_rate = 0.01
epochs = 20
batch_size = 1000
# 指定标签
label_name = "median_house_value"
# 将原始训练集拆分为训练集和验证集
validation_split = 0.2
dnn_outputs = get_outputs_dnn()
# 构建模型拓扑
my_model = create_model(
inputs,
dnn_outputs,
learning_rate)
# 在规范化训练集上训练模型。我们通过了整个规范化训练集,但模型将只使用我们输入中定义的特征
epochs, mse, history = train_model(my_model, train_df, epochs,
batch_size, label_name, validation_split)
plot_the_loss_curve(epochs, mse, history["val_mean_squared_error"])
# 根据训练集构建模型后,根据测试集测试该模型
test_features = {name: np.array(value) for name, value in test_df.items()}
test_label = test_median_house_value_normalized(np.array(test_features.pop(label_name))) # isolate the label
print("\n Evaluate the new model against the test set:")
my_model.evaluate(x=test_features, y=test_label, batch_size=batch_size, return_dict=True)
用 5.2 的代码(训练、测试神经网络模型)替换掉 4.4 节的代码(训练、测试线性回归模型),运行结果如下:

其中,基于测试集(验证集)得到的结果为:loss: 0.3475 - mean_squared_error: 0.3475。
5.3 优化深度神经网络的拓扑结构
实验,调整深度神经网络的层数和每层中的节点数。旨在实现以下两个目标:
- 降低测试集的损耗。
- 最小化深度神经网络中的节点总数。
需要说明的是,上述两个目标可能存在冲突。这里,我们简单尝试一下,如下代码单元所示,
5.3.1 实验一:增加层数
# 定义深度神经网络模型
def get_outputs_dnn():
# 创建一个包含20个节点的密集层
dense_output = tf.keras.layers.Dense(units=20, input_shape=(1,),
activation='relu',
name='hidden_dense_layer_1')(preprocessing_layers)
# 创建一个具有12个节点的密集层
dense_output = tf.keras.layers.Dense(units=12, input_shape=(1,),
activation='relu',
name='hidden_dense_layer_2')(dense_output)
# 创建一个具有10个节点的密集层
dense_output = tf.keras.layers.Dense(units=10, input_shape=(1,),
activation='relu',
name='hidden_dense_layer_3')(dense_output)
# 创建密集输出层
dense_output = tf.keras.layers.Dense(units=1, input_shape=(1,),
name='dense_output')(dense_output)
# 定义一个输出字典,并发送给模型构造函数
outputs = {
'dense_output': dense_output
}
return outputs运行结果如下:

其中,基于测试集(验证集)得到的结果为:loss: 0.3451 - mean_squared_error: 0.3451。经过多次实验,我们会发现——增加层数并不能带来损失的有效降低(虽有降低,但并不多),因此,增加层数意义不大,某种意义上,对于这个数据集,两层就是最佳层数。
5.3.2 实验一:减少节点数
模型层数不变(仍采用两层神经网络),我们将节点数量减少 1/2,如下代码单元所示。
# 定义深度神经网络模型
def get_outputs_dnn():
# 创建一个包含10个节点的密集层
dense_output = tf.keras.layers.Dense(units=10, input_shape=(1,),
activation='relu',
name='hidden_dense_layer_1')(preprocessing_layers)
# 创建一个具有6个节点的密集层
dense_output = tf.keras.layers.Dense(units=6, input_shape=(1,),
activation='relu',
name='hidden_dense_layer_2')(dense_output)
# 创建密集输出层
dense_output = tf.keras.layers.Dense(units=1, input_shape=(1,),
name='dense_output')(dense_output)
# 定义一个输出字典,并发送给模型构造函数
outputs = {
'dense_output': dense_output
}
return outputs运行结果如下:
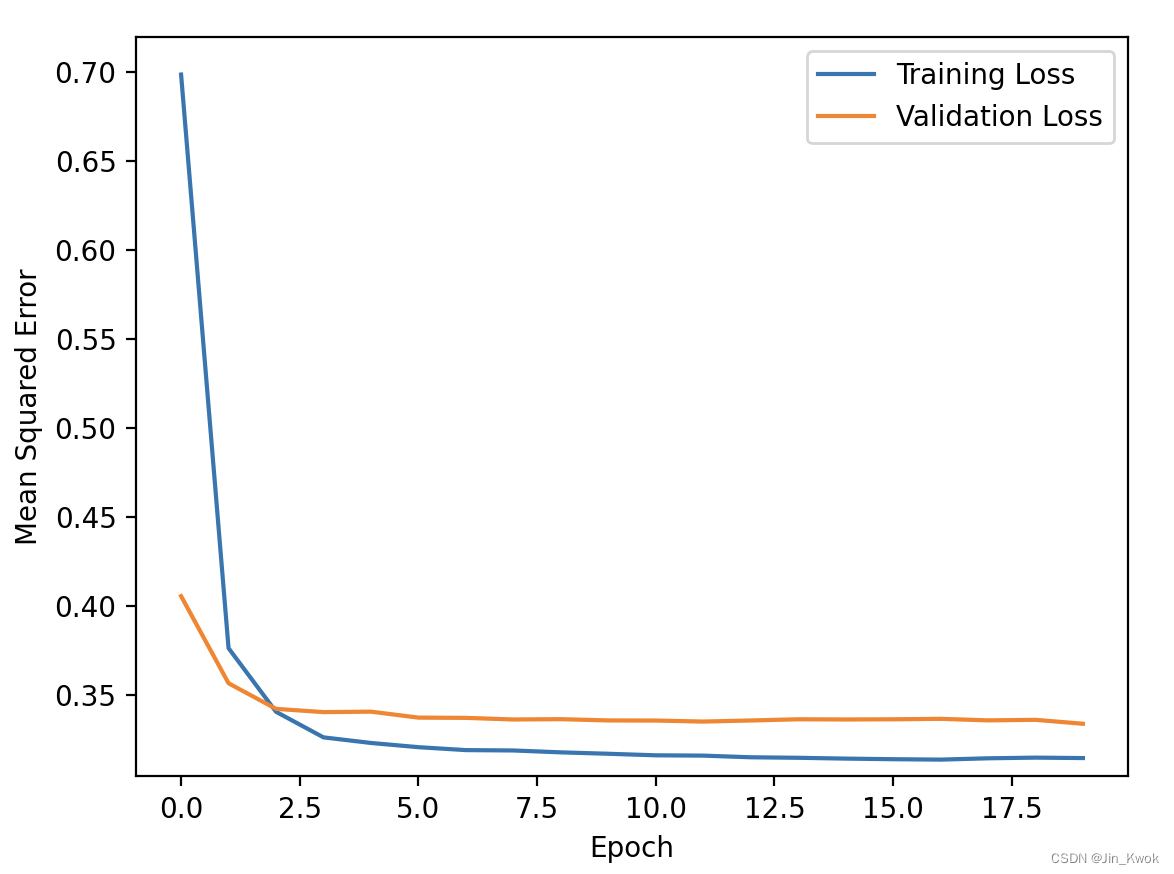
其中,基于测试集(验证集)得到的结果为:loss: 0.3468 - mean_squared_error: 0.3468。相较于原模型(两层,20+12节点),损失有所降低,同时模型节点数量更少,更加简单。事实上,我们可以进一步减少节点数量(两层,6+4节点),也可能取得不错的效果。
神经网络模型,并不是层数越多越好,也不是节点数越多越好,在实践中,我们可通过实验寻找较为合适(预测效果可接受)的层数和节点数,尽量降低复杂度。
6.两种模型结果对比
两种模型在测试集的表现如下所示:
- 线性回归模型:loss: 0.3608 - mean_squared_error: 0.3608
- 神经网络模型:loss: 0.3475 - mean_squared_error: 0.3475
假设线性模型收敛,深度神经网络模型也收敛,比较每种模型的测试集损失。在我们的实验中,深度神经网络模型的损失始终低于线性回归模型的损失,这表明深度神经网络模式将比线性回归模型做出更好的预测。
7.参考文献
https://developers.google.cn/machine-learning/crash-course/introduction-to-neural-networks/video-lecture




![Android12之IBinder中[[clang::lto_visibility_public]]作用(一百六十)](https://img-blog.csdnimg.cn/20190106163945739.jpg#pic_center)