徐辉 | 后端开发工程师
一、引言
随着深度学习和自然语言处理技术的快速发展,大型预训练语言模型(如GPT、Vicuna、Alpaca、Llama、ChatGLM等)在各种应用场景中取得了显著的成果。然而,从零开始训练这些模型需要大量的计算资源和时间,这对于许多研究者和开发者来说是不现实的。因此,FineTune工程就显得格外重要,它允许我们在预训练模型的基础上进行定制化调整,以适应下游的任务和场景。本文将介绍LoRa的微调技术,并详细阐述如何使用LoRa微调大型预训练语言模型(以下统称为LLM)。
二、LoRa如何工作
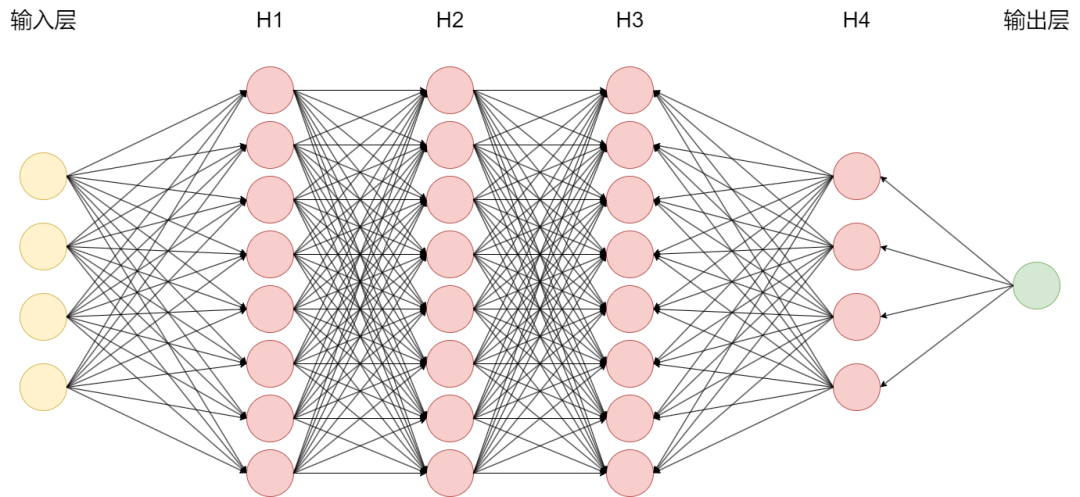
图1
之前在基地的ChatGPT分享中提到过LLM的工作原理是根据输入文本通过模型神经网络中各个节点来预测下一个字,以自回归生成的方式完成回答。
实际上,模型在整个自回归生成过程中决定最终答案的神经网络节点只占总节点的极少一部分。如图1所示为多级反馈神经网络,以输入鹬蚌相争为例,真正参与运算的节点如下图2蓝色节点所示,实际LLM的节点数有数亿之多,我们称之为参数量。

图2
神经网络包含许多稠密层,执行矩阵乘法运算。这些层中的权重矩阵通常具有满秩。LLM具有较低的“内在维度”,即使在随机投影到较小子空间时,它们仍然可以有效地学习。
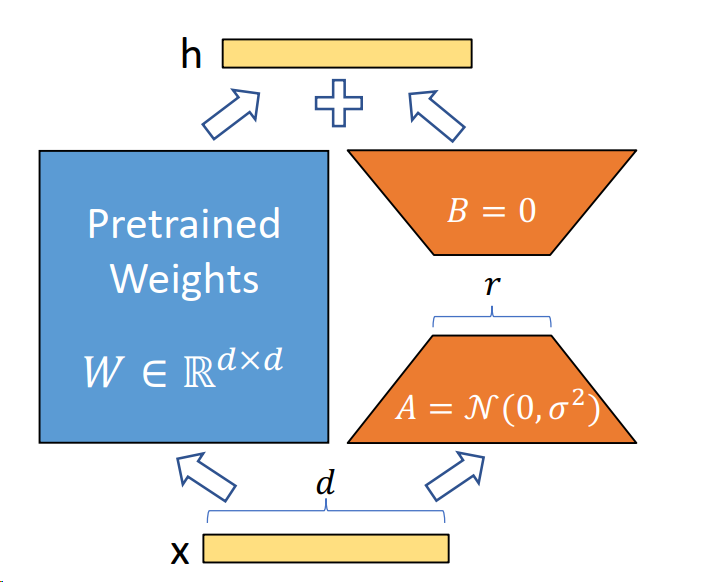
图3
假设权重的更新在适应过程中也具有较低的“内在秩”。对于一个预训练的权重矩阵W0 ∈ Rd×k,我们通过低秩分解W0 + ∆W = W0 + BA来表示其更新,其中B ∈ Rd×r,A ∈ Rr×k,且秩r ≤ min(d,k)。在训练过程中,W0被冻结,不接收梯度更新,而A和B包含可训练参数。需要注意的是,W0和∆W = BA都与相同的输入进行乘法运算,它们各自的输出向量在坐标上求和。前向传播公式如下:h = W0x + ∆Wx = W0x + BAx
在图3中我们对A使用随机高斯随机分布初始化,对B使用零初始化,因此在训练开始时∆W = BA为零。然后,通过αr对∆Wx进行缩放,其中α是r中的一个常数。在使用Adam优化时,适当地缩放初始化,调整α的过程与调整学习率大致相同。因此,只需将α设置为我们尝试的第一个r,并且不对其进行调整。这种缩放有助于在改变r时减少重新调整超参数的需求。
四、LoRa微调ChatGLM-6B
有时候我们想让模型帮我们完成一些特定任务或改变模型说话的方式和自我认知。作为定制化交付中心的一员,我需要让“他”加入我们。先看一下模型原本的输出。

图4
接下来我将使用LoRa微调将“他”变成定制化交付中心的一员。具体的LoRa微调及微调源码请前往Confluence查看LoRa高效参数微调
-
准备数据集
我们要准备的数据集是具有针对性的,例如你是谁?你叫什么?谁是你的设计者?等等有关目标身份的问题,答案则按照我们的需求进行设计,这里列举一个例子
Q:你是谁?
A:我叫小州,是定制化交付中心部门的一名员工,我主要负责解答用户的疑问并提供帮助。请问有什么可以帮您?
-
设置参数进行微调
CUDA_VISIBLE_DEVICES=0 python ../src/train_sft.py \
--do_train \
--dataset self \
--dataset_dir ../data \
--finetuning_type lora \
--output_dir path_to_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16影响模型训练效果的参数主要有下面几个
lora_rank(int,optional): LoRA 微调中的秩大小。这里并不是越大越好,对于小型数据集如果r=1就可以达到很不错的效果,即便增加r得到的结果也没有太大差别。
lora_alpha(float,optional): LoRA 微调中的缩放系数。
lora_dropout(float,optional): LoRA 微调中的 Dropout 系数。
learning_rate(float,optional): AdamW 优化器的初始学习率。如果设置过大会出现loss值无法收敛或过拟合现象即过度适应训练集而丧失泛化能力,对非训练集中的数据失去原本的计算能力。
num_train_epochs(float,optional): 训练轮数,如果loss值没有收敛到理想值可以增加训练轮数或适当降低学习率。-
微调评估
我们再次询问模型身份

图5
当我们询问不包含在数据集中的身份问题时

图6
很好,我们得到了理想的回答,这说明“小州”的人设已经建立成功了,换句话说,图二中蓝色节点(身份信息)的权重已经改变了,之后任何关于身份的问题都会是以“小州”的人设进行回答。
五、总结
针对LLM的主流微调方式有P-Tuning、Freeze、LoRa等等。由于LoRa的并行低秩矩阵几乎没有推理延迟被广泛应用于transformers模型微调,另一个原因是ROI过低,对LLM的FineTune所需要的计算资源不是普通开发者或中小型企业愿意承担的。而LoRa将训练参数减少到原模型的千万分之一的级别使得在普通计算资源下也可以实现FineTune。
参考文献:LoRA: Low-Rank Adaptation of Large Language Models
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,了解更多技术干货。