公众号关注 “GitHubDaily”
设为 “星标”,每天带你逛 GitHub!

最近这段时间,AI 的整体热度有所下降,但是 AI 技术在各行各业的探索脚步,却一直没有停止。
在 ChatGPT 刚发布时,有不少业内人士认为,AI 所拥有的专业性,严谨性,用来做一些特定行业的智能顾问,兴许这个不错的选择。
法律行业,也是在此其中,最早被人提及,认为最有可能被 AI 颠覆的行业之一。
但不少人经过尝试之后,发现目前 AI 在法律行业的应用,依旧有不少问题需要解决。
其中最为严重严重的,就是 AI 在实际回答问题的时候,经常会出现 Hallucination(幻觉),进而提供一些胡编乱造的回答。
对于法律这种需要各种严谨数据支撑,要求合理且充足论据的应用场景,无论是 GPT-3.5 还是 GPT-4,目前仍有不少问题需要解决。
几天前,来自北大团队的一位朋友找到了我,说他们在 GitHub 开源了一个专注于法律行业的大语言模型:ChatLaw。
经过各种评估测试,发现其在法律行业中,所展示出来的实际效果,都要优于现有的大模型。
今天在此给大家郑重介绍下这个项目。
ChatLaw 是一个基于各种中文法律条文、实际案例、判决条文所训练出来的法律大模型,可借助 AI,实现法律合同撰写、案例介绍、条款讲解、司法问题咨询等场景。
GitHub:https://github.com/PKU-YuanGroup/ChatLaw
在线使用:https://chatlaw.cloud/lawchat/
开发者可以利用这个大模型,快速搭建出个人法律顾问与专属智能律师,帮助你更好地解决在日常生活工作中,遇到的各种法律纠纷。
该模型主要拥有 3 个系列(ChatLaw-13B、ChatLaw-33B、ChatLaw-Text2Vec),适用于多种不同场景。
根据参数量级,ChatLaw 可分为 13B 和 33B 版本,两者皆为学术 demo 版,分别对应着 130 亿和 330 亿训练参数。
ChatLaw-13B 是基于姜子牙 Ziya-LLaMA-13B-v1 模型训练而成,中文数据较为丰富,因此在中文对话场景下,表现较为优异,但缺点是训练参数不足,有时候一些较为复杂的法律问题,回答质量偏低。
ChatLaw-33B 是基于另一个中文模型 Anima-33B 训练而成,因为参数较大,因此逻辑推理能力明显上升不少。但是中文语料还是太少,因此在回答时,偶尔会出现一些英文数据。
对于大部分使用用户来说,法律模型更多的交互场景,主要还是围绕法律咨询进行。
为了让 AI 能够更好的理解与响应用户提出的法律问题,北大团队使用了 93 万条真实判决案例数据集,基于 BERT 训练了一个相似度匹配模型:ChatLaw-Text2Vec,让人工智能自动匹配用户提问与法律条文。
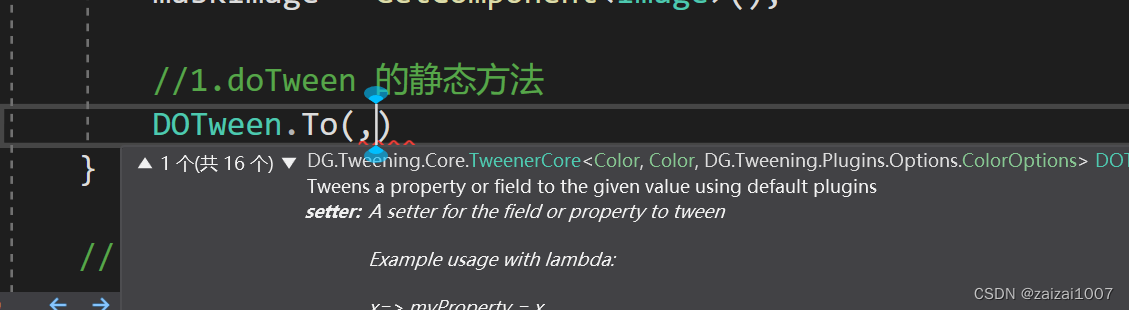
用户提问:“如果借款没还,怎么办?”
AI 回答:"合同法(1999-03-15): 第二百零六条 借款人应当按照约定的期限返还借款。对借款期限没有约定或者约定不明确,依照本法第六十一条的规定仍不能确定的,借款人可以随时返还;贷款人可以催告借款人在合理期限内返还"。
结果表明,AI 回答的文本内容与训练数据的相似度计算为 0.9960。通过这种方式,可大幅降低大语言模型所出现的「幻觉」问题,提升答案质量。
在模型评估测试环节,ChatLaw 团队也搞得颇有特色。
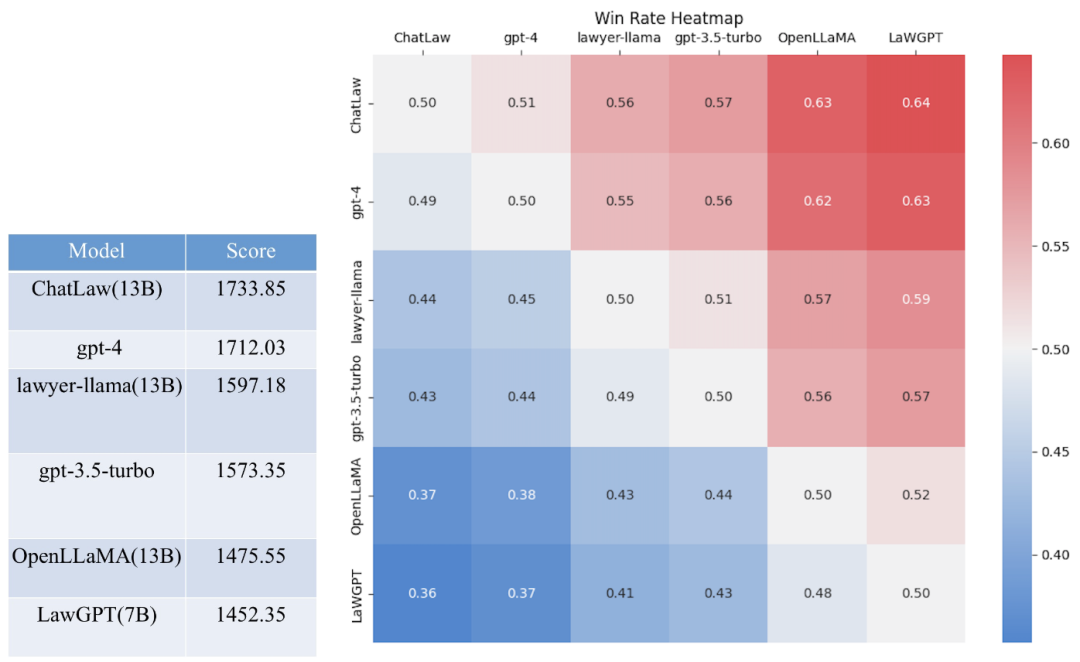
他们引入了英雄联盟的 ELO 机制,基于过去十余年的司法考试题目,整理出共 2000 道问题,让 AI 模型去打模型排位赛,并进行评分,最终发现 ChatLaw 的最终得分与胜率都表现颇佳。
未来大语言模型要真正达到可用,提升逻辑推理,降低模型幻觉,是两大亟待解决的核心问题,这也是 ChatLaw 团队的下一步主要研究方向。
在接下来的几个月内,开发者会通过提升模型参数,优化向量数据库,让这两个问题的研究,拥有突破性进展,大家可以拭目以待。
由于今年 AIGC 较火,为此我们也建立了一个 AI 社群,探索更多人工智能领域的前景与应用。
如果你想了解更多实用的 AI 技术与应用,以及 ChatGPT 新进展,可以点击下方链接,加入我们社群进一步交流探讨。
社群入口:ChatGPT 社群,正式上线!
不想错过文章推送?点击下面公众号卡片,给 GitHubDaily 公众号加个星标吧!