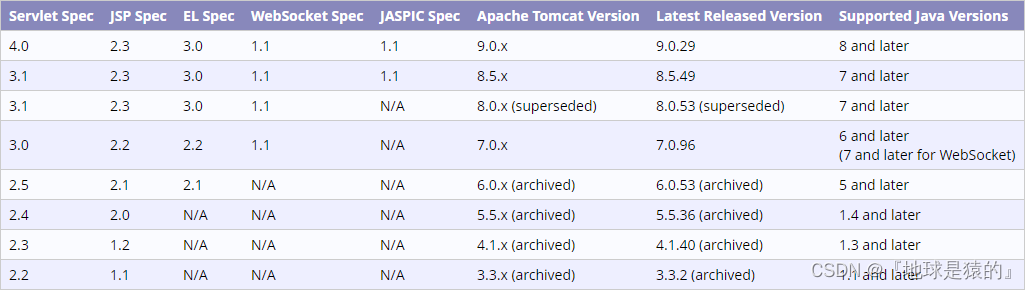
LLM大模型和生成式AI在2023年上半年迅速爆发,不仅高盛集团和麦肯锡发布了生成式AI的经济前景预测,纷纷认为生成式AI将为全球生产力带来显著提升,每年将为全球带来数万亿美元的经济增长,更有UC伯克利和斯坦福等先后发布了LLM大模型排行榜,入榜的全球顶级LLM大模型达到近30个,这还不包括中国市场上涌现的众多LLM大模型。
随着LLM“百模大战”的逼近,行业用户需要更加快速地基于现有LLM大模型,开发面向本行业、本企业的定制大模型及生成式AI应用。在2023年7月6日的2023世界人工智能大会(WAIC)上,与全球领先AI公司合作超过27年的澳鹏重磅推出智能LLM大模型开发平台,同时宣布面向生成式AI战略升级——从AI数据服务“破圈”进入全栈AI服务。
澳鹏智能LLM大模型开发平台面向行业AI提供集大模型数据准备、模型训练、模型推理、模型部署应用于一体,涵盖从数据集管理、数据标注、计算资源调度、模型评估、模型微调等全栈能力,帮助企业轻松拥抱大模型,构建生成式AI应用,为最终用户实现变革性体验。此外,澳鹏LLM产品线还包括基础数据、基线模型、模型评估&微调、应用开发等全链条产品、平台与服务。

(澳鹏全球高级副总裁、大中华区及北亚区总经理田小鹏博士)
“2023年下半年,LLM大模型和生成式AI市场将呈现巨大的迸发与成长态势。生成式AI的大时代,才刚刚开始”,澳鹏全球高级副总裁、大中华区及北亚区总经理田小鹏博士表示。“澳鹏聚焦于高效经济量产行业大模型与生成式AI应用,为各行业智能化转型全面赋能!”
战略升级正当时
2023年上半年可谓是LLM基础大模型的“春秋战国”时期,从全球到中国纷纷诞生了众多基础大模型,还有更多的团队在跑步入场基础大模型的研发。截止2023年6月底,在Github上已经收录了来自中国的85家大模型——主要为LLM基础大模型,以及部分面向行业和特定领域的大模型,再加上全球顶级的基础大模型,“百模大战”已经不是夸张的表达。
“百模大战”仍在鏖战中,但也成功让AI突破了科技圈,引发了更广泛人群的关注与重视。在全球,根据IBM商业价值研究院在6月底发布的年度CEO调查,四分之三受访CEO认为,拥有最先进的生成式人工智能的企业将拥有竞争优势。在中国,Gartner中国企业人工智能趋势浪潮3.0指出,中国企业正在将人工智能项目从原型转向生产,大多数企业已不再纠结于为何需要AI能力,而更加关注AI工程化能力的建设。
在2023年下半年,LLM大模型工业化量产和工程化落地的趋势,正从“百模大战”中清晰地浮现出来,特别是众多的行业和企业客户更加关注如何选择已有的LLM大模型并微调后适配本行业和企业的业务场景,真正将AI用于提高行业和企业生产力。简单理解,就是高效经济地量产行业LLM大模型以及将行业大模型端到端落地到企业中真正提升生产力,这将是2023年下半年的AI市场重点。
在2023年初,长期致力于为AI企业和企业AI提供高质量标注数据的澳鹏,审时度势、大胆“押注”,全面展开了公司战略升级——从AI数据服务扩展向全栈AI服务,致力于成为面向垂直行业的AI服务商。澳鹏新任全球CEO Armughan Ahmad在公司2022年报中表示,AI数据标注是基础,而生成式AI所代表的全栈AI服务是增长S曲线,也是澳鹏接下来的战略重点。澳鹏已经有强大的AI数据标注工具、平台和服务,接下来就是在此基础上,快速推动工业化量产行业大模型以及生成式AI应用,打开万亿新增经济体量。
大模型开发一站打尽
想要快速工业化量产行业LLM大模型以及生成式AI应用,就需要面向行业的大模型开发平台,这也是2023年下半年的AI市场热点和重点。在2023年上半年,已经有部分科技企业推出了面向行业的大模型定制化开发或解决方案,而专业化的第三方大模型开发平台及端到端AI大模型开发服务,还是市场空白点。
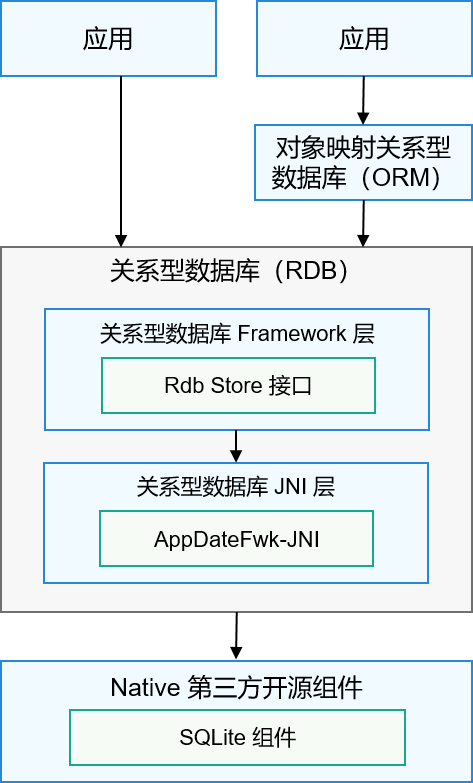
澳鹏智能LLM大模型开发平台由澳鹏中国团队研发,是面向LLM大模型微调(Fine-tune)的开发平台,主要是对业界已有的开源基础大模型进行选型的基础上,再针对游戏、医疗、客服等行业和业务场景大模型进行微调。澳鹏中国产品负责人周波介绍,澳鹏智能LLM大模型开发平台包括数据、模型和计算资源管理三大模块。

(澳鹏智能LLM大模型开发平台架构图)
对于LLM大模型研发来说,高质量的标注数据十分关键。ChatGPT之所以能脱颖而出,就是引入了高质量的人工标注数据。而对UC伯克利的LLM排行榜分析发现,高质量的微调数据集比模型规模更重要,特别是在预训练和微调阶段管理高质量的数据集,是缩小模型规模同时保持模型高质量的关键方法。越来越多的研究发现,高质量的标注数据对于模型微调结果以及缩小模型规模同时保持模型质量来说,是十分重要甚至是关键方法。
澳鹏智能LLM大模型开发平台的数据模块来自于澳鹏中国的另一个拳头产品:MatrixGo企业级高精度数据标注平台,MatrixGo是面向深度学习和机器学习数据标注的企业级平台,不仅有强大的标注工具集,还有AI辅助标注,灵活、可视的工作流,以及Open API与外部数据平台的集成和数据闭环。澳鹏中国开发团队针对LLM的开发需求,结合MatrixGo的技术,开发了LLM大模型开发平台的数据模块,可确保数据标注质量和效率,同时不断降低标注成本。
澳鹏智能LLM大模型开发平台的数据模块包括数据集管理与数据采集标注,其中:数据集管理包括数据处理、数据检索、数据可视化、数据切片等功能;数据采集标注包括人员管理、工作流引擎、标注工具引擎和自动标算法等功能。
澳鹏智能LLM大模型开发平台的核心为模型模块,包括模型评估、模型微调和模型部署三大部分,其中:模型评估提供了A/B测试、标准语料测试、自定义测试、测试结果可视化和模型分析等功能,模型微调提供了开源模型库、模型管理、训练任务管理等功能,模型部署提供了自动化部署、运行监控、标准API和自动封装SDK等。
模型评估主要服务于开源大模型的选型,包括用标准语料包或是自定义语料包进行测试,针对不同的开源大模型或同一大模型的不同版本进行A/B测试后,对相关测试结果进行分析和可视化,再结合模型参数、占用资源等,选定要进行微调的大模型。

(澳鹏智能LLM大模型开发平台模型微调示例)
模型微调则是在对选定的大模型,用高质量标注数据和RLHF人工反馈增强学习,针对不同的场景进行微调。模型微调的结果将返回到模型评估,两者联动完成模型迭代,直到达成预期效果。模型部署则是将微调成功后的大模型部署到客户的计算资源环境中,并可以API或SDK方式对外服务。
澳鹏智能LLM大模型开发平台的计算资源管理则是对客户的计算资源进行任务管理和资源调度,包括CPU和GPU的资源,以及对上层应用的支持与调度等。
澳鹏智能LLM大模型开发平台可以使用澳鹏中国自研的基础大模型,也可以使用客户自有或是第三方的开源基础大模型。
在自研基础大模型方面,澳鹏中国研发团队主要基于开源社区的工作,也在横向评估其它的选型方案。澳鹏中国自研大模型的特色,主要是在自有数据集上进行微调,包括通用话题对话以及具有专业性背景的语料等。澳鹏本身就对外提供了超过250个预标注的音频、图像、文字和视频等数据集,这些高质量标注数据集对于大模型预训练来说十分珍贵。此外,澳鹏中国研发团队还在关注学界、工业界的进展,从模型结构、优化方式和部署效率等方面,不断优化自研大模型。
在第三方大模型的合作方面,澳鹏全球与NVIDIA、AWS等深入合作,特别是与NVIDIA等大模型以及企业级AI开发平台的深入合作,将澳鹏的数据工具链、标注众包团队以及数据服务等与大厂的大模型、AI平台和工具等结合,为行业和企业提供端到端的一站式生成式AI解决方案。此外,澳鹏还与Cohere、Reka AI等企业级大模型初创公司合作,强强联合提供高度安全的定制专有模型。在中国,澳鹏中国也与知名基础大模型深入合作,了解这些大模型的特点及可适用场景,为客户提供专业的选型方案和咨询服务。
技术共创,与AI领军者共同成长
作为交付数据经验丰富的提供方,澳鹏智能LLM大模型开发平台的最大差异化竞争优势在于,从零样本、半监督学习的角度,快速响应迭代模型和数据交付。

作为长期从事有监督学习数据标注服务商,澳鹏在项目交付方面拥有大量的实践经验,可为LLM训练与微调任务以及生成式AI应用,持续挖掘数据价值。主要优势包括:
第一,与客户的算法应用共同成长。由于行业客户在早期实践生成式AI的时候,很难在一开始就明确项目需求,需要边合作、边探索、边开发,通过不断迭代而最终完成应用构建。
澳鹏善于管理和统筹交付周期,可以分批次向客户交付数据采标、模型优化、应用测试等,模型优化可以与数据采标交替进行;可以用小样本、增量学习的方式驱动模型在项目中快速迭代,数据采标更快地集成到应用测试中;甚至可以将标注工程视为客户LLM性能测试之前的“预质检”,这样相当将客户行业或业务场景的知识前置,也就是预训练的预训练。
第二,更好地把握“Human in the loop”。该开发平台会分析人工在采集标注过程中的种种交互行为,而澳鹏在这方面有丰富的经验,可以将其转换为RLHF算法中的“奖励功能”,并可挖掘更细粒度的标注信息等等,为制备大模型提供更多的数据养料,体现了对于数据挖掘维度的深刻理解。
第三,长期合作可带来数据采标的规模效应。澳鹏的开发平台具备大规模、安全、高质量的数据,以及完整的视觉、文本、语音类的行业基准模型,且在多个采标项目上实践过。在每一个项目完结阶段,都能产出一个性能不俗、与客户需求完全镜像的模型算法和高质量的数据benchmark。
新澳鹏:全链条AI服务商
自从LLM大模型在全球爆红以来,就一度有大模型将统治AI界的论调。但经过2023年上半年的“百模大战”,大家逐渐认识到深度学习与LLM大模型对于AI应用来说,都同等重要。所谓LLM大模型,即模型参数达到百亿、千亿以上,具有“智能涌现”的通用基础AI大模型,但由于参数和占用计算资源庞大等特点,并不适用于企业和行业场景,深度学习和机器学习则在实际应用中有着不可取代的价值。
澳鹏全球高级副总裁、大中华区及北亚区总经理田小鹏博士表示,对于未来的AI市场和智能经济,澳鹏的策略是深度学习与大模型,两手抓、两手硬。
首先,深度学习、机器学习等对于当下的数字化转型来说正在发挥实效,特别是适用于实时计算和边缘计算等企业级场景,在智能汽车、智能物联网、智能制造等领域发挥着重要的作用,澳鹏仍将坚持面向深度学习和机器学习领域的AI数据服务,同时与顶尖AI企业的深度学习和机器学习平台形成端到端解决方案,满足企业当下的AI工程化落地需求。
2023年6月底,澳鹏Appen企业级高精度人工智能辅助数据标注平台——MatrixGo正式上线SaaS版本。MatrixGo自发布以来,已经经历了数千个AI数据标注项目的实战打磨,累积了来自各行各业、各种类型项目丰富的实战经验。MatrixGo SaaS版本的上线,让企业客户能够更快速地部署MatrixGo,最快一天开通使用、投入生产,同时可以获得专业的使用培训和客服支持,SaaS版本还将持续为客户提供即时更新的MatrixGo最新版本,让企业客户使用最新和最先进的数据服务,打造高质量深度学习和机器学习应用。
此外,澳鹏也将LLM技术用于改善数据标注工具和平台,不断强化澳鹏在深度学习和机器学习数据服务方面的竞争优势。新推出的文档智能产品可以从非结构化文档中自动提取信息,例如从扫描文档或文档照片中提取内容,准确率达到99%,这极大拓展了企业AI数据源。NLP自动标注则采用小样本或零样本学习和LLM模型,对数据进行自动化标注,从而加速数据供应。澳鹏在2022年还投资了全球顶尖的视觉AI合成数据供应商MindTech,可以提供一系列高质量多维度多角度的合成逼真图片,应对小样本甚至零样本问题。
其次,澳鹏将对LLM大模型进行战略投入,推出以澳鹏智能LLM大模型开发平台为代表的LLM产品线。澳鹏LLM产品线包括基础数据、基线模型、评估与微调以及上层生成式AI应用等四大部分。
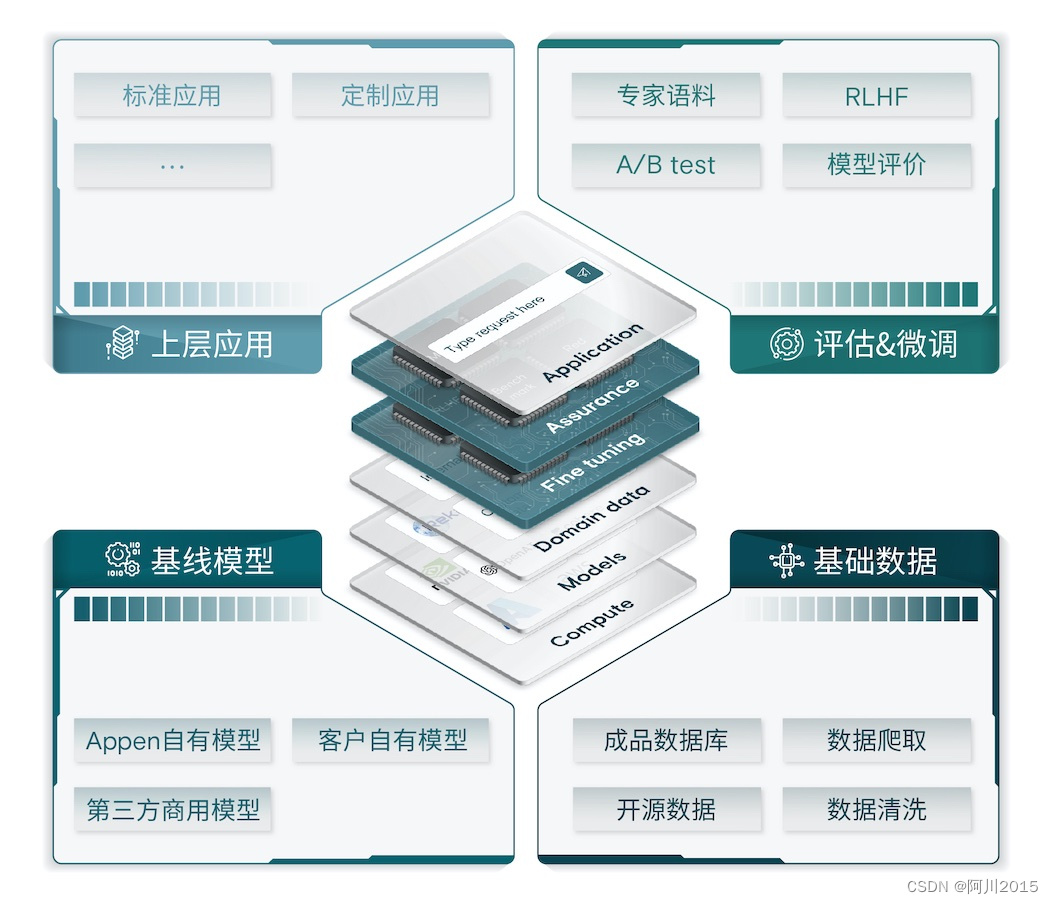
LLM基础数据提供成品数据集、数据爬取、数据清洗和开源数据等,为LLM基础大模型训练以及微调大模型提供高质量数据集。
基线模型则提供自研模型和第三方开源或商用模型,以及支持客户自有模型,澳鹏自研模型可根据使用场景定制化、模型私有化体积可以根据运行资源要求进行限制,支持私有化部署、云平台API调用等,第三方合作模型则包括Reka、Cohere等国内外优秀的商用和开源大模型。
评估和微调包括专家语料、RLHF、A/B测试和模型评价等LLM大模型训练服务。澳鹏在全球有上百万的众包数据收集和标注员,支持235+种语言和方言,也有专门面向金融、零售、工业和医疗等行业的专家众包资源。过去,这些资源服务于深度学习和机器学习的数据标注;未来,面向LLM大模型的训练需求,这些资源还能够提供提示词-输出语料包、专业领域语料包,以及将人工嵌入到LLM大模型训练的人工反馈增强环节,实现RLHF算法,提升模型的专业领域能力。
模型评估包括A/B测试、模型评价、红蓝对抗和基准测试等方法,主要是由澳鹏的LLM专家和众包资源一起,评估不同大模型以及同一大模型不同版本的输出结果,对模型输出进行评价以避免歧视和涉黄等风险,在多轮对话对抗中评估模型的能力,以及使用行业标准语料包对大模型进行基准测试。
第三,在更远期,澳鹏将把深度学习和机器学习与LLM大模型结合起来,端到端为企业客户开发生成式AI应用,从数据到模型再到应用开发,提供全链条的咨询与应用开发服务,进而成为核心AI供应商。
相比于其它LLM和生成式AI赛道的参与者,澳鹏有非常扎实的数据“底盘”和全链条的数据工具链、平台和人力资源,而数据能力才是LLM和生成式AI的王道。此外,澳鹏还与全球AI企业、AI生态有着长达27年的合作关系历史,也参与了大量企业和行业AI落地的项目实践,有着丰富的企业级项目实施经验。这些都为澳鹏在LLM和生成式AI时代的自我颠覆,打下了坚实的基础。
展望未来:LLM大模型和生成式AI是全球智能进化的“奇点”,而一个全新姿态的澳鹏正在LLM大模型和生成式AI中崛起。从顶级AI数据服务商,到快速切入行业LLM大模型和生成式AI赛道,再向生成式AI应用以及全链条AI咨询开发发展,澳鹏正基于过去27年的积累,在全球智能进化“奇点”时刻,把握机会、迅速蝶变,并与全球AI生态一起,打开生成式AI的大未来!(文/宁川)