6. Spark SQL实战
6.1 数据说明
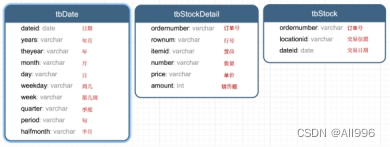
数据集是货品交易数据集。
|
|
|
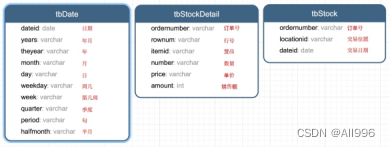
每个订单可能包含多个货品,每个订单可以产生多次交易,不同的货品有不同的单价。
6.2 加载数据
tbStock:
scala> case class tbStock(ordernumber:String,locationid:String,dateid:String) extends Serializable
defined class tbStock
scala> val tbStockRdd = spark.sparkContext.textFile("tbStock.txt")
tbStockRdd: org.apache.spark.rdd.RDD[String] = tbStock.txt MapPartitionsRDD[1] at textFile at <console>:23
scala> val tbStockDS = tbStockRdd.map(_.split(",")).map(attr=>tbStock(attr(0),attr(1),attr(2))).toDS
tbStockDS: org.apache.spark.sql.Dataset[tbStock] = [ordernumber: string, locationid: string ... 1 more field]
scala> tbStockDS.show()
+------------+----------+---------+
| ordernumber|locationid| dataid|
+------------+----------+---------+
|BYSL00000893| ZHAO|2007-8-23|
|BYSL00000897| ZHAO|2007-8-24|
|BYSL00000898| ZHAO|2007-8-25|
|BYSL00000899| ZHAO|2007-8-26|
|BYSL00000900| ZHAO|2007-8-26|
|BYSL00000901| ZHAO|2007-8-27|
|BYSL00000902| ZHAO|2007-8-27|
|BYSL00000904| ZHAO|2007-8-28|
|BYSL00000905| ZHAO|2007-8-28|
|BYSL00000906| ZHAO|2007-8-28|
|BYSL00000907| ZHAO|2007-8-29|
|BYSL00000908| ZHAO|2007-8-30|
|BYSL00000909| ZHAO| 2007-9-1|
|BYSL00000910| ZHAO| 2007-9-1|
|BYSL00000911| ZHAO|2007-8-31|
|BYSL00000912| ZHAO| 2007-9-2|
|BYSL00000913| ZHAO| 2007-9-3|
|BYSL00000914| ZHAO| 2007-9-3|
|BYSL00000915| ZHAO| 2007-9-4|
|BYSL00000916| ZHAO| 2007-9-4|
+------------+----------+---------+
only showing top 20 rows
tbStockDetail:
scala> case class tbStockDetail(ordernumber:String, rownum:Int, itemid:String, number:Int, price:Double, amount:Double) extends Serializable
defined class tbStockDetail
scala> val tbStockDetailRdd = spark.sparkContext.textFile("tbStockDetail.txt")
tbStockDetailRdd: org.apache.spark.rdd.RDD[String] = tbStockDetail.txt MapPartitionsRDD[13] at textFile at <console>:23
scala> val tbStockDetailDS = tbStockDetailRdd.map(_.split(",")).map(attr=> tbStockDetail(attr(0),attr(1).trim().toInt,attr(2),attr(3).trim().toInt,attr(4).trim().toDouble, attr(5).trim().toDouble)).toDS
tbStockDetailDS: org.apache.spark.sql.Dataset[tbStockDetail] = [ordernumber: string, rownum: int ... 4 more fields]
scala> tbStockDetailDS.show()
+------------+------+--------------+------+-----+------+
| ordernumber|rownum| itemid|number|price|amount|
+------------+------+--------------+------+-----+------+
|BYSL00000893| 0|FS527258160501| -1|268.0|-268.0|
|BYSL00000893| 1|FS527258169701| 1|268.0| 268.0|
|BYSL00000893| 2|FS527230163001| 1|198.0| 198.0|
|BYSL00000893| 3|24627209125406| 1|298.0| 298.0|
|BYSL00000893| 4|K9527220210202| 1|120.0| 120.0|
|BYSL00000893| 5|01527291670102| 1|268.0| 268.0|
|BYSL00000893| 6|QY527271800242| 1|158.0| 158.0|
|BYSL00000893| 7|ST040000010000| 8| 0.0| 0.0|
|BYSL00000897| 0|04527200711305| 1|198.0| 198.0|
|BYSL00000897| 1|MY627234650201| 1|120.0| 120.0|
|BYSL00000897| 2|01227111791001| 1|249.0| 249.0|
|BYSL00000897| 3|MY627234610402| 1|120.0| 120.0|
|BYSL00000897| 4|01527282681202| 1|268.0| 268.0|
|BYSL00000897| 5|84126182820102| 1|158.0| 158.0|
|BYSL00000897| 6|K9127105010402| 1|239.0| 239.0|
|BYSL00000897| 7|QY127175210405| 1|199.0| 199.0|
|BYSL00000897| 8|24127151630206| 1|299.0| 299.0|
|BYSL00000897| 9|G1126101350002| 1|158.0| 158.0|
|BYSL00000897| 10|FS527258160501| 1|198.0| 198.0|
|BYSL00000897| 11|ST040000010000| 13| 0.0| 0.0|
+------------+------+--------------+------+-----+------+
only showing top 20 rows
tbDate:
scala> case class tbDate(dateid:String, years:Int, theyear:Int, month:Int, day:Int, weekday:Int, week:Int, quarter:Int, period:Int, halfmonth:Int) extends Serializable
defined class tbDate
scala> val tbDateRdd = spark.sparkContext.textFile("tbDate.txt")
tbDateRdd: org.apache.spark.rdd.RDD[String] = tbDate.txt MapPartitionsRDD[20] at textFile at <console>:23
scala> val tbDateDS = tbDateRdd.map(_.split(",")).map(attr=> tbDate(attr(0),attr(1).trim().toInt, attr(2).trim().toInt,attr(3).trim().toInt, attr(4).trim().toInt, attr(5).trim().toInt, attr(6).trim().toInt, attr(7).trim().toInt, attr(8).trim().toInt, attr(9).trim().toInt)).toDS
tbDateDS: org.apache.spark.sql.Dataset[tbDate] = [dateid: string, years: int ... 8 more fields]
scala> tbDateDS.show()
+---------+------+-------+-----+---+-------+----+-------+------+---------+
| dateid| years|theyear|month|day|weekday|week|quarter|period|halfmonth|
+---------+------+-------+-----+---+-------+----+-------+------+---------+
| 2003-1-1|200301| 2003| 1| 1| 3| 1| 1| 1| 1|
| 2003-1-2|200301| 2003| 1| 2| 4| 1| 1| 1| 1|
| 2003-1-3|200301| 2003| 1| 3| 5| 1| 1| 1| 1|
| 2003-1-4|200301| 2003| 1| 4| 6| 1| 1| 1| 1|
| 2003-1-5|200301| 2003| 1| 5| 7| 1| 1| 1| 1|
| 2003-1-6|200301| 2003| 1| 6| 1| 2| 1| 1| 1|
| 2003-1-7|200301| 2003| 1| 7| 2| 2| 1| 1| 1|
| 2003-1-8|200301| 2003| 1| 8| 3| 2| 1| 1| 1|
| 2003-1-9|200301| 2003| 1| 9| 4| 2| 1| 1| 1|
|2003-1-10|200301| 2003| 1| 10| 5| 2| 1| 1| 1|
|2003-1-11|200301| 2003| 1| 11| 6| 2| 1| 2| 1|
|2003-1-12|200301| 2003| 1| 12| 7| 2| 1| 2| 1|
|2003-1-13|200301| 2003| 1| 13| 1| 3| 1| 2| 1|
|2003-1-14|200301| 2003| 1| 14| 2| 3| 1| 2| 1|
|2003-1-15|200301| 2003| 1| 15| 3| 3| 1| 2| 1|
|2003-1-16|200301| 2003| 1| 16| 4| 3| 1| 2| 2|
|2003-1-17|200301| 2003| 1| 17| 5| 3| 1| 2| 2|
|2003-1-18|200301| 2003| 1| 18| 6| 3| 1| 2| 2|
|2003-1-19|200301| 2003| 1| 19| 7| 3| 1| 2| 2|
|2003-1-20|200301| 2003| 1| 20| 1| 4| 1| 2| 2|
+---------+------+-------+-----+---+-------+----+-------+------+---------+
only showing top 20 rows
注册表:
scala> tbStockDS.createOrReplaceTempView("tbStock")
scala> tbDateDS.createOrReplaceTempView("tbDate")
scala> tbStockDetailDS.createOrReplaceTempView("tbStockDetail")
6.3 计算所有数据中每年的销售单数、销售总额
统计所有订单中每年的销售单数、销售总额
三个表连接后以count(distinct a.ordernumber)计销售单数,sum(b.amount)计销售总额
|
|
|

| SELECT c.theyear, COUNT(DISTINCT a.ordernumber), SUM(b.amount) FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber JOIN tbDate c ON a.dateid = c.dateid GROUP BY c.theyear ORDER BY c.theyear |
| spark.sql("SELECT c.theyear, COUNT(DISTINCT a.ordernumber), SUM(b.amount) FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber JOIN tbDate c ON a.dateid = c.dateid GROUP BY c.theyear ORDER BY c.theyear").show |
结果如下:
| +-------+---------------------------+--------------------+ |theyear|count(DISTINCT ordernumber)| sum(amount)| +-------+---------------------------+--------------------+ | 2004| 1094| 3268115.499199999| | 2005| 3828|1.3257564149999991E7| | 2006| 3772|1.3680982900000006E7| | 2007| 4885|1.6719354559999993E7| | 2008| 4861| 1.467429530000001E7| | 2009| 2619| 6323697.189999999| | 2010| 94| 210949.65999999997| +-------+---------------------------+--------------------+ |
6.4 查询每年最大金额的订单及其金额
目标:统计每年最大金额订单的销售额:
|
|
1. 统计每年,每个订单一共有多少销售额
| SELECT a.dateid, a.ordernumber, SUM(b.amount) AS SumOfAmount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber GROUP BY a.dateid, a.ordernumber |
| spark.sql("SELECT a.dateid, a.ordernumber, SUM(b.amount) AS SumOfAmount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber GROUP BY a.dateid, a.ordernumber").show |
2. 结果如下:
| +----------+------------+------------------+ | dateid| ordernumber| SumOfAmount| +----------+------------+------------------+ | 2008-4-9|BYSL00001175| 350.0| | 2008-5-12|BYSL00001214| 592.0| | 2008-7-29|BYSL00011545| 2064.0| | 2008-9-5|DGSL00012056| 1782.0| | 2008-12-1|DGSL00013189| 318.0| |2008-12-18|DGSL00013374| 963.0| | 2009-8-9|DGSL00015223| 4655.0| | 2009-10-5|DGSL00015585| 3445.0| | 2010-1-14|DGSL00016374| 2934.0| | 2006-9-24|GCSL00000673|3556.1000000000004| | 2007-1-26|GCSL00000826| 9375.199999999999| | 2007-5-24|GCSL00001020| 6171.300000000002| | 2008-1-8|GCSL00001217| 7601.6| | 2008-9-16|GCSL00012204| 2018.0| | 2006-7-27|GHSL00000603| 2835.6| |2006-11-15|GHSL00000741| 3951.94| | 2007-6-6|GHSL00001149| 0.0| | 2008-4-18|GHSL00001631| 12.0| | 2008-7-15|GHSL00011367| 578.0| | 2009-5-8|GHSL00014637| 1797.6| +----------+------------+------------------+ |
3.以上一步查询结果为基础表,和表tbDate使用dateid join,求出每年最大金额订单的销售额
| SELECT theyear, MAX(c.SumOfAmount) AS SumOfAmount FROM (SELECT a.dateid, a.ordernumber, SUM(b.amount) AS SumOfAmount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber GROUP BY a.dateid, a.ordernumber ) c JOIN tbDate d ON c.dateid = d.dateid GROUP BY theyear ORDER BY theyear DESC |
| spark.sql("SELECT theyear, MAX(c.SumOfAmount) AS SumOfAmount FROM (SELECT a.dateid, a.ordernumber, SUM(b.amount) AS SumOfAmount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber GROUP BY a.dateid, a.ordernumber ) c JOIN tbDate d ON c.dateid = d.dateid GROUP BY theyear ORDER BY theyear DESC").show |
4. 结果如下:
| +-------+------------------+ |theyear| SumOfAmount| +-------+------------------+ | 2010|13065.280000000002| | 2009|25813.200000000008| | 2008| 55828.0| | 2007| 159126.0| | 2006| 36124.0| | 2005|38186.399999999994| | 2004| 23656.79999999997| +-------+------------------+ |
6.5 计算每年最畅销货品
目标1:统计每年最畅销货品(哪个货品销售额amount在当年最高,哪个就是最畅销货品)
目标2:统计每年最畅销货品(哪个货品销售数量当年最高,哪个就是最畅销货品)
|
|
|
第一步、求出每年每个货品的销售额
| SELECT c.theyear, b.itemid, SUM(b.amount) AS SumOfAmount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber JOIN tbDate c ON a.dateid = c.dateid GROUP BY c.theyear, b.itemid |
| spark.sql("SELECT c.theyear, b.itemid, SUM(b.amount) AS SumOfAmount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber JOIN tbDate c ON a.dateid = c.dateid GROUP BY c.theyear, b.itemid").show |
结果如下:
| +-------+--------------+------------------+ |theyear| itemid| SumOfAmount| +-------+--------------+------------------+ | 2004|43824480810202| 4474.72| | 2006|YA214325360101| 556.0| | 2006|BT624202120102| 360.0| | 2007|AK215371910101|24603.639999999992| | 2008|AK216169120201|29144.199999999997| | 2008|YL526228310106|16073.099999999999| | 2009|KM529221590106| 5124.800000000001| | 2004|HT224181030201|2898.6000000000004| | 2004|SG224308320206| 7307.06| | 2007|04426485470201|14468.800000000001| | 2007|84326389100102| 9134.11| | 2007|B4426438020201| 19884.2| | 2008|YL427437320101|12331.799999999997| | 2008|MH215303070101| 8827.0| | 2009|YL629228280106| 12698.4| | 2009|BL529298020602| 2415.8| | 2009|F5127363019006| 614.0| | 2005|24425428180101| 34890.74| | 2007|YA214127270101| 240.0| | 2007|MY127134830105| 11099.92| +-------+--------------+------------------+ |
第二步:在第一步的基础上,统计每年单个货品中的最大金额
| SELECT d.theyear, MAX(d.SumOfAmount) AS MaxOfAmount FROM (SELECT c.theyear, b.itemid, SUM(b.amount) AS SumOfAmount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber JOIN tbDate c ON a.dateid = c.dateid GROUP BY c.theyear, b.itemid ) d GROUP BY d.theyear |
| spark.sql("SELECT d.theyear, MAX(d.SumOfAmount) AS MaxOfAmount FROM (SELECT c.theyear, b.itemid, SUM(b.amount) AS SumOfAmount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber JOIN tbDate c ON a.dateid = c.dateid GROUP BY c.theyear, b.itemid ) d GROUP BY d.theyear").show |
结果如下:
| +-------+------------------+ |theyear| MaxOfAmount| +-------+------------------+ | 2007| 70225.1| | 2006| 113720.6| | 2004|53401.759999999995| | 2009| 30029.2| | 2005|56627.329999999994| | 2010| 4494.0| | 2008| 98003.60000000003| +-------+------------------+ |
第三步:用最大销售额和统计好的每个货品的销售额join,以及用年join,集合得到最畅销货品那一行信息
| SELECT DISTINCT e.theyear, e.itemid, f.MaxOfAmount FROM (SELECT c.theyear, b.itemid, SUM(b.amount) AS SumOfAmount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber JOIN tbDate c ON a.dateid = c.dateid GROUP BY c.theyear, b.itemid ) e JOIN (SELECT d.theyear, MAX(d.SumOfAmount) AS MaxOfAmount FROM (SELECT c.theyear, b.itemid, SUM(b.amount) AS SumOfAmount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber JOIN tbDate c ON a.dateid = c.dateid GROUP BY c.theyear, b.itemid ) d GROUP BY d.theyear ) f ON e.theyear = f.theyear AND e.SumOfAmount = f.MaxOfAmount ORDER BY e.theyear |
| spark.sql("SELECT DISTINCT e.theyear, e.itemid, f.maxofamount FROM (SELECT c.theyear, b.itemid, SUM(b.amount) AS sumofamount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber JOIN tbDate c ON a.dateid = c.dateid GROUP BY c.theyear, b.itemid ) e JOIN (SELECT d.theyear, MAX(d.sumofamount) AS maxofamount FROM (SELECT c.theyear, b.itemid, SUM(b.amount) AS sumofamount FROM tbStock a JOIN tbStockDetail b ON a.ordernumber = b.ordernumber JOIN tbDate c ON a.dateid = c.dateid GROUP BY c.theyear, b.itemid ) d GROUP BY d.theyear ) f ON e.theyear = f.theyear AND e.sumofamount = f.maxofamount ORDER BY e.theyear").show |
结果如下:
| +-------+--------------+------------------+ |theyear| itemid| maxofamount| +-------+--------------+------------------+ | 2004|JY424420810101|53401.759999999995| | 2005|24124118880102|56627.329999999994| | 2006|JY425468460101| 113720.6| | 2007|JY425468460101| 70225.1| | 2008|E2628204040101| 98003.60000000003| | 2009|YL327439080102| 30029.2| | 2010|SQ429425090101| 4494.0| +-------+--------------+------------------+ |
7. SparkSQL整合Hive
sparksql可以使用hive的元数据库,如果没有,sparksql也可以自己创建。
- 在mysql创建一个普通用户(也可以使用root用户)
| SQL |
- 添加一个hive-site.xml到spark的conf目录,里面的内容如下:
| XML |
- 初始化hive的源数据库
| Shell |
- 上传一个mysql连接驱动,可以将连接驱动放入到spark的安装包的jars或者使用--driver-class-path指定mysql连接驱动的位置
| Shell |
- 重新启动SparkSQL的命令行
| Shell |
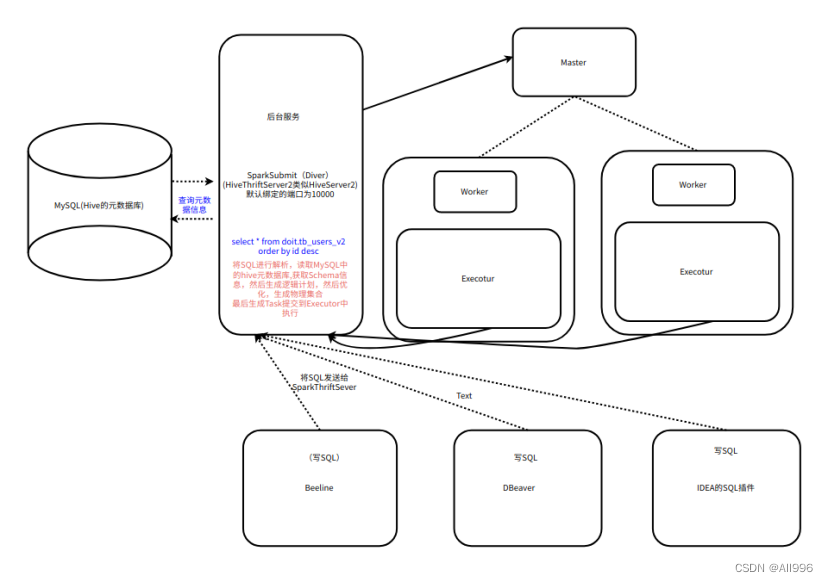
Spark SQL也提供JDBC连接支持,这对于让商业智能(BI)工具连接到Spark集群上以及在多用户间共享一个集群的场景都非常有用。JDBC 服务器作为一个独立的Spark 驱动器程序运行,可以在多用户之间共享。任意一个客户端都可以在内存中缓存数据表,对表进行查询。集群的资源以及缓存数据都在所有用户之间共享。
Spark SQL的JDBC服务器与Hive中的HiveServer2相一致。由于使用了Thrift通信协议,它也被称为“Thrift server”。
服务器可以通过 Spark 目录中的 sbin/start-thriftserver.sh 启动。这个 脚本接受的参数选项大多与 spark-submit 相同。默认情况下,服务器会在 localhost:10000 上进行监听,我们可以通过环境变量(HIVE_SERVER2_THRIFT_PORT 和 HIVE_SERVER2_THRIFT_BIND_HOST)修改这些设置,也可以通过 Hive配置选项(hive. server2.thrift.port 和 hive.server2.thrift.bind.host)来修改。
你也可以通过命令行参数:--hiveconf property=value来设置Hive选项。
在 Beeline 客户端中,你可以使用标准的 HiveQL 命令来创建、列举以及查询数据表。
| Shell |
Spark的ThriftServer的原理(类似HiveServer2服务)
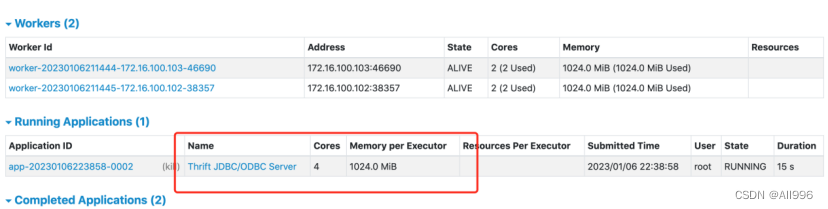
启动beeline客户端连接ThriftServer
| Shell |