1. 直接赋值
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
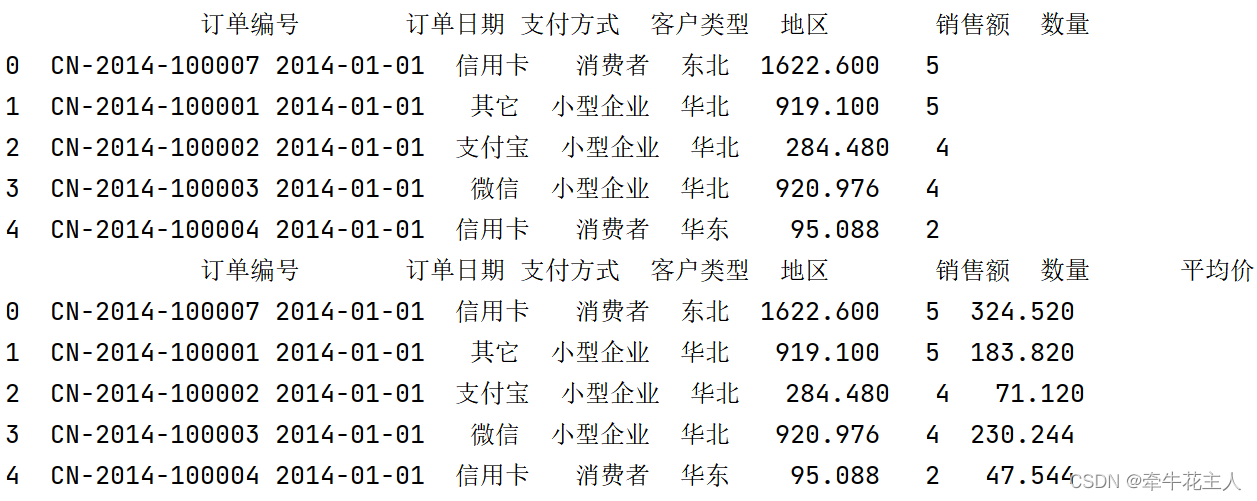
print(order.head())
# 1.直接赋值新增列:
order['平均价']=order['销售额']/order['数量']
print(order.head())
2.apply()方法
2.1 函数功能
沿着DataFrame的某个轴应用一个函数。返回值为Series或者Data Frame
2.2 函数语法
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs)
2.3 函数参数
| 参数 | 含义 |
|---|---|
| func | 要对每列或每行运用的函数 |
| axis | 函数作用轴,默认为0,取值为0或字符串’index’,1或字符串’columns’ |
| raw | 行,列是否作为Series对象传入函数中,默认为False:作为Series对象传入函数,取值为True时:使用ndarray对象传入函数 |
| result_type | 只有axis=1时,参数才发挥作用,默认取值为None:由函数产生的值决定 |
| args | Series和array之外,其他传入函数中的位置参数 |
| **kwargs | 其他传入函数中的关键字参数 |
order['销售额开方']=order['销售额'].apply(np.sqrt,axis=1)
print(order.head())

3. assign()方法
3.1 函数功能
可以同时生成多个新列,返回的是一个包含原DataFrame和新列的新DataFrame
3.2 函数语法
DataFrame.assign(**kwargs)
3.3 函数参数
| 参数 | 含义 |
|---|---|
| **kwargs | 新列计算字典 |
assign()方法并没有改变原来的DataFrame,而是生成了新的,需要将操作后的数据重新赋值给DataFrame
order=order.assign(数量2=order['数量']*10)
print(order.head())

同时新增多列
order=order.assign(数量22=order['数量']*2,数量33=order['数量']*3)
print(order.head())

4. 按照条件选择分组分别赋值
order['客户级别']=np.nan
print(order.head())
order.loc[order['销售额']>=order['销售额'].mean(),'客户级别']='大客户'
order.loc[order['销售额']<order['销售额'].mean(),'客户级别']='小客户'
print(order.head())

参考视频:https://www.bilibili.com/video/BV1UJ411A7Fs?p=6&spm_id_from=pageDriver&vd_source=1dc8a157f48c26397e26256eb05fe0a9