Towards Unified Text-based Person Retrieval: A Large-scale Multi-Attribute and Language Search Benchmark
Towards Unified Text-based Person Retrieval: A Large-scale Multi-Attribute and Language Search Benchmark
西安交通大学
针对 基于文本的行人检索的预训练 展开探索
Motivation
Data Scarcity
Contributions
- MALS(Multi-Attribute and Language Search dataset for person retrieval):本文引入了一个大型的多属性和语言搜索数据集,用于基于文本的person retrieval,包含150万+图像-文本对,比现有的CUHK-PEDES大37.5倍,所有图像都有丰富的(27个)属性注释。
- APTM(Attribute Prompt Learning and Text Matching Learning)框架,基于MALS提出了一种联合属性提示学习和文本匹配学习框架,考虑属性和文本之间的shared knowledge,两个任务互补并相互受益。
- 提出的方法在三个具有挑战性的real-world基准实现了competitive的召回率。此外,我们观察到文本匹配任务也有助于属性识别,在PA-100K上对APTM进行微调,我们获得(obtain)82.58%mA的具有竞争性的性能。
MALS
- 将其他数据集的文本描述作为prompts,利用扩散模型(ImaginAIry)生成图像-文本对;
- 针对生成的不能满足训练需求的图像进行后处理(post-process)。删除灰度、模糊和嘈杂的图像,利用OpenPose检测的关键点作为紧凑的边界框重新剪裁图像;
- 图像描述校准:初始图像-文本对中的多个图像共享相同的文本描述,导致文本多样性较差。因此,我们利用BLIP模型为每一张合成图像生成对应的文本描述,最终形成图像-文本对,示例Fig. 1。
- 属性注释:我们首先以和Market-1501属性数据集相同的属性空间。通过文本关键词匹配(显示匹配和隐式扩展),自动为每一对图像-文本对注释了27种不同类型的属性,如Table 2。
(相关的属性通常突出图像和文本样本的关键特征,许多基于文本的person retrieval工作表明了属性在性能改进方面的潜力,受此启发,我们用属性标注进一步增强了我们的MALS。)

Fig.1. Selected image-text pairs from our MALS (top) and CUHK-PEDES (bottom). We could observe that the visual gap between synthetic data and real ones is relatively small. In MALS, image-text pairs match almost as well as manual annotation, although there are some flaws occasionally. It is worth noting that images in MALS are high-fidelity with rich and diverse variations in terms of pose, appearance, background, etc.
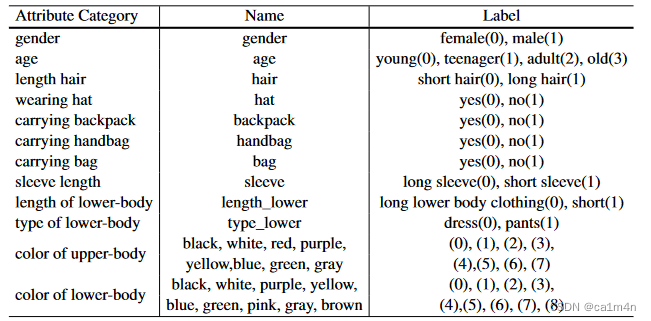 Table 2: Attribute space consists of 27 attributes. Here we show the attribute category, the name in the annotation file, and the available label choices.
Table 2: Attribute space consists of 27 attributes. Here we show the attribute category, the name in the annotation file, and the available label choices.
APTM
联合属性提示学习和文本匹配学习框架
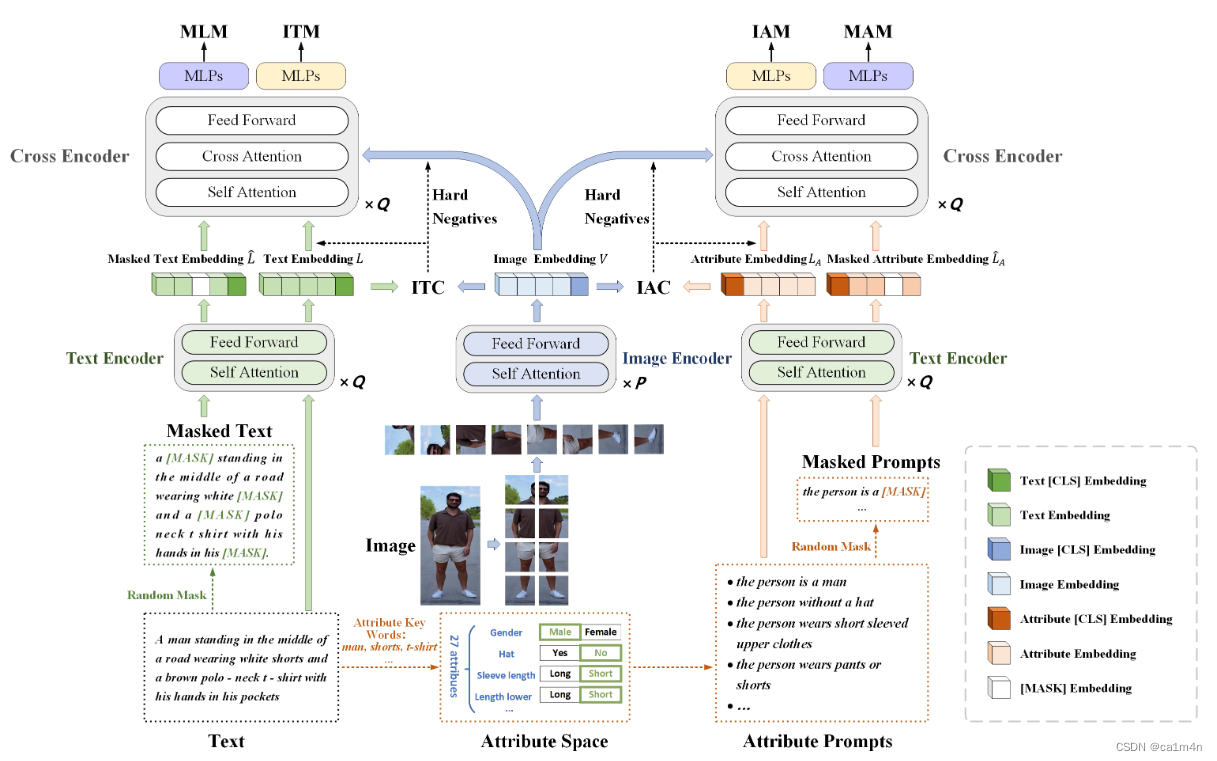
可以简单理解为权重shared的双流结构吗
实验在CUHK-PEDES、RSTPReid和ICFG-PEDES数据集上评估了APTM(微调过程中优化ITC、ITM和MLM损失)。APTM在三个数据集上均达到了SOTA的R1
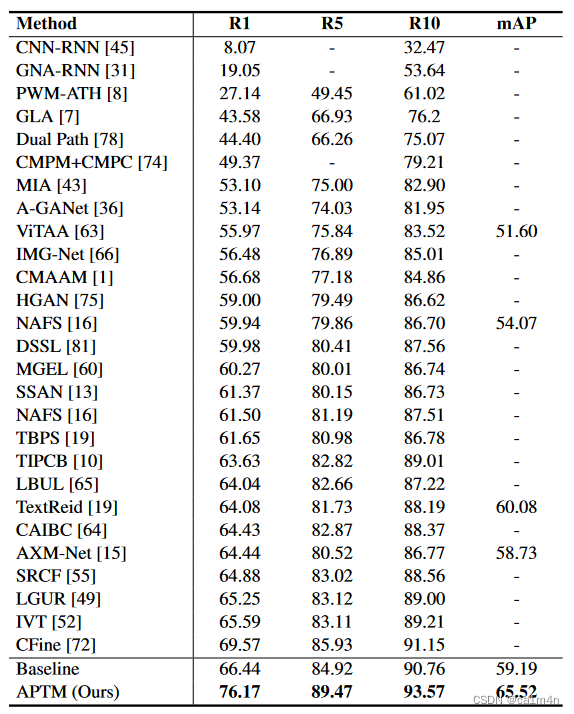
Table 3: Performance Comparison on CUHK-PEDES
这篇能学一下文章撰写结构