Java面试题——简答题部分
文章目录
- Java面试题——简答题部分
- 1.列举几个常用的集合类并指出特点
- 2.Set里的元素是不能重复的,那么用什么方法来区分重复与否呢,是==还是equals(),有何区别?
- 3.请描述线程的生命状态,并描述sleep(),join(),yield()的区别以及interrupt()的作用
- 4.简述包装类中new方法和valueof方法的区别
- 5.内存溢出和内存泄漏
- 6.final、finally、finalize的区别是什么
- 7.Collection和Collections的区别
- 8.数据库的5种约束
- 9.请描述三大范式
- 10.什么是事务,特性有哪些
- 11.事务的隔离级别
- 12.java8新特性
- 13.Vector和List
- 14.什么是SQL注入,如何防止SQL注入
- 15.如何优化sql,提高查询效率
- 16.索引失效
- 17.如何优化数据库,提高性能
- 18.请描述HashMap的数据结构,且指出JDK1.8前后hashmap的区别
- 19.HashMap和hashtable,concurrentHashMap的区别
- 20.使用冒泡排序对数组进行升序排序
- 21.写出懒汉式单例
- 22.session和cookie的区别
- `session`对象的作用域
- `servlet`中的四大域对象(了解)
- 23.描述servlet的生命周期中涉及到哪些方法
- 24.转发(forward)和重定向(redirect)的区别
- 25.拦截器(Interceptor)和过滤器(Filter)的区别
- 26.乐观锁和悲观锁
- 27.mybatis中 ${ } 与 #{ } 的区别
- 28.请描述 SpringMVC 的五大组件并描述 SpringMVC 对请求的处理流程
- 29.Spring 中 Bean 的作用域
- 30.说说自动装配注解 Resource 和 Autowired 的区别
- 31.请描述mybatis中的一级缓存和二级缓存
- 32.mybatis的动态sql
- 33.请简述Spring的两种核心技术
- 34.请说出几个Spring中的注解以及其作用
- 动态代理机制分类
- AOP的应用
- 反射
- 35.JVM的结构以及如何调优
- JVM的结构
- JVM的优化
- JVM堆内存大小的调整
- 36.说一说年轻代、年老代的工作原理
- 年轻代
- 年老代
- 37.GC的分类
- 38.GC垃圾回收机制的常用算法
- 39.数据库的主从复制,读写分离,分库分表
- 40.redis的哨兵模式
- 41.redis的五种数据类型,分别应用场景
- 42.SpringCloud的五大组件和作用
- 43.同步通讯和异步通讯的区别
- 44.Ribbon和Feign的区别
- 45.Linux命令
1.列举几个常用的集合类并指出特点
- List集合:有序,有下标,元素可重复
ArrayList:底层是数组实现的,所以查询元素效率很高,增删元素效率相对LinkedList而言较低LinkedList:底层是双向链表实现的,增删元素效率较ArrayList较高,查询元素效率较低
- Set集合:不可重复集
LinkedHashSet:底层是散列表 + 链表,用链表来维护元素的顺序,元素是有序的HashSet:底层是散列表,查询效率最高,元素是无序的TreeSet:底层是红黑树,对元素进行了排序
- Map集合:
HashMap:底层是散列表,查询快,元素无序TreeMap:底层是红黑树,实现了排序LinkedHashMap:底层是散列表 + 链表,有序
2.Set里的元素是不能重复的,那么用什么方法来区分重复与否呢,是==还是equals(),有何区别?
- 使用
equals() - 区别:
- == 两侧若为引用类型,比较地址是否相等
equals方法是Object提供的方法,在Object类中,其作用等同于==;但是Java强烈建议在子类中重写该方法,使其根据有逻辑意义。重写后通常都是根据对象的内容值来比较对象是否相等
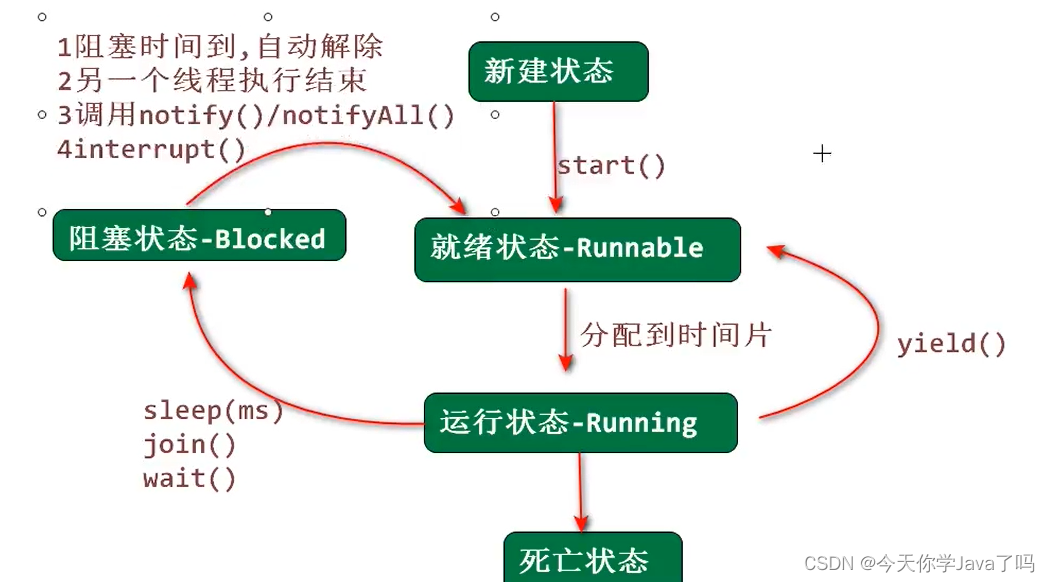
3.请描述线程的生命状态,并描述sleep(),join(),yield()的区别以及interrupt()的作用
- 新建 --> 就绪 --> 运行 --> 阻塞 --> 死亡
interrupt():打断线程的阻塞状态,唤醒线程- 若线程处于阻塞状态,调用该方法,线程被唤醒
- 若线程处于运行状态,调用该方法,无效
yield():为其他线程让步,但是调用之后,线程进入就绪状态,而不是阻塞状态join():用于实现线程间的同步通讯,调用进入阻塞状态- wait():调用该方法,线程阻塞,唤醒需要其他线程调用
notify()或notifyAll(),调用进入阻塞状态
4.简述包装类中new方法和valueof方法的区别
new:包装类一定创建了一个新的对象valueof():完成的是基本数据类型到包装类型的转换,若给出的数值处于常量池的缓存范围之内,此时直接复用常量池中的对象,不再重新创建对象。若数值不处于常量池的范围内,则新创建包装类对象
5.内存溢出和内存泄漏
- 内存泄漏:分配出去的内存回收不回来,无法重新利用,这种现象叫做内存泄漏
- 内存溢出:内存剩余空间不足以分配给请求的资源
- 关系:内存泄漏累积到一定程度会造成内存溢出,但内存溢出不一定是由内存泄漏引起的,也可能是创建的对象太大引起的
- 常见内存溢出:
OutofMemoryError(OOM):heap溢出StackOverFlowError(SOF):stack溢出 递归
6.final、finally、finalize的区别是什么
final:是修饰符,可以用来修饰类(类不能被继承)、方法(方法不能被重写)、变量(一旦初始化不可再改变)finally:是try...catch配合使用的,特点是不论之前是否有异常出现,都一定会执行finally块中的代码,经常用于保存释放资源的代码finalize:是Object类提供的方法,在GC回收对象前会调用该方法进行最后的资源释放
7.Collection和Collections的区别
Collection:是接口,其常用子接口有List、SetCollections:是集合操作类,提供了一系列方法用于操作集合
8.数据库的5种约束
- 主键约束
- 外键约束
- 唯一性约束
- 非空约束
- 检查约束
9.请描述三大范式
设计表时需要遵守的规则即为范式,通常遵循前三个范式,设计出的表结构就是合理的
- 1NF:所有的列必须是原子性的
- 2NF:非码属性必须完全依赖候选码
- 3NF:非主属性不能传递依赖于其他非主属性
10.什么是事务,特性有哪些
事务是数据库中执行操作的最小执行单元,不可再分,要么全都执行成功,要么全都失败
- A:原子性
- C:一致性
- I:持久性
- D:隔离性
11.事务的隔离级别
- 读未提交(
read—uncommited)可能产生 脏读、不可重复读、幻读 - 读已提交(
read—commited)可能产生 不可重复读、幻读;是Oracle、SqlServer的默认隔离级别。 - 可重复读(
repeatableRead)可能产生 幻读;是MySQL的默认隔离级别。(但MySQL不会产生幻读,因为采取的是快照读) - 串行化(
Serializable)
12.java8新特性
- lambda表达式
- 新日期LocalDateTime
- ::方法引用
- 接口中可以定义static 方法和默认方法
13.Vector和List
Vector是向量,是list的前身,是线程安全的集合,list是非现场安全的集合
14.什么是SQL注入,如何防止SQL注入
- SQL注入:由于用户在客户端输入数据时拼接了sql语句,最终导致添加的sql语句作为执行sql的一部分执行,破坏了原来sql的意义,导致用户非法获取对数据的现象。即为sql注入
- 防止SQL注入:采取预编译;
Mybatis框架:#{ }实现了预编译- 非框架:实现预编译方式是
PrepareStatement
Mybatis的占位符#{ }:实现了预编译${ }:没有实现预编译,通常用于做字符串拼接
15.如何优化sql,提高查询效率
- 尽可能的避免使用嵌套查询,尽量使用联查
- 查询语句中不要使用 *
- 建立索引
16.索引失效
- 应尽量避免在
where子句中对字段进行null值判断,否则将导致引擎放弃使用索引而进行全表扫描 - 应尽量避免在
where子句中使用!=操作符,否则将导致引擎放弃使用索引而进行全表扫描 - 应尽量避免在
where子句中使用or来连接条件,否则将导致引擎放弃使用索引而进行全表扫描 not in也要慎用,否则将导致引擎放弃使用索引而进行全表扫描- 应尽量避免在
where子句中对字段使用like左侧模糊查询,否则将导致引擎放弃使用索引而进行全表扫描 - 应尽量避免在
where子句中对字段进行表达式操作,否则将导致引擎放弃使用索引而进行全表扫描 - 应尽量避免在
where子句中对字段进行函数操作,否则将导致引擎放弃使用索引而进行全表扫描
使用索引注意事项:
- 索引适用于数据量大的表,数据量小的表不适用,反而会降低其效率
- 索引适合添加给作为查询条件的字段
- 若字段的值会被频繁修改,不适合添加索引
- 索引并不是越多越好,索引固然可以提高
select效率,但同时降低了insert及update效率,因为insert或update时有可能会重建索引,所以怎样创建索引需要慎重考虑,视情况而定,一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要
创建索引的sql:
create index in_name on table(col)
17.如何优化数据库,提高性能
- 分库分表
- 读写分离,主从复制
- 集群
18.请描述HashMap的数据结构,且指出JDK1.8前后hashmap的区别
- jdk1.8之前:数据结构为:数组 + 链表
- jdk1.8开始:数据结构为:数组 + 链表 + 红黑树(散列桶位置的链表长度达到8,提高查询效率)
HashMap存或查元素的过程:
- 根据
key调用hashCode(),得到Hash码值 - 再调用散列函数得到下标存入散列桶位置
- 散列桶为空直接存入,不为空进行
equals()比较, - 结果为
true,key相同,value覆盖;结果为false,形成链表
19.HashMap和hashtable,concurrentHashMap的区别
HashMap是非线程安全的hashtable和concurrentHashMap是线程安全的HashMap的key和value都允许null,hashtable和concurrentHashMap不允许hashtable和concurrentHashMap保证线程安全的方式不同hashtable是通过给整张散列表加锁保证线程安全,这种方式并发执行效率低concurrentHashMap保证线程安全的同时提高并发执行效率。在jdk1.8之前是采用分段锁机制(如果多线程并发访问的是不同段(segment)是完全并发的);在jdk1.8之后采用乐观锁和synchronized配合使用,多线程并发向同一个散列桶添加元素时,看该位置是否为null,为null采用乐观锁机制,不为null采用synchronized方式谁先访问到,先给头节点加锁从而形成链表或红黑树
20.使用冒泡排序对数组进行升序排序
for(int i = 0;i < ary.length - 1; i++){
for(int j = 0;i<ary.length - i - 1;j++){
if(ary[j] > ary[j + 1]){
int tmp = ary[j];
ary[j] = ary[j+1];
ary[j+1] = tmp;
}
}
}
21.写出懒汉式单例
// 单例核心 构造方法私有化,提供公有方法,向外提供实例,声明成员变量
// 懒汉式单例声明成员变量不初始化
public class Singleton{
private Singleton(){};
private static Singleton singleton;
public static synchronized Singleton getInstance(){
if(singleton == null)
singleton = new Singleton();
return singleton;
}
}
22.session和cookie的区别
- 作用位置不同:
session是作用在服务器端保存数据的,而cookie是作用在浏览器中保存数据的 - 保存数据类型不同:
session中可以保存任意类型的数据(session.setAttribute(name,value)),cookie中只能保存字符串对象 - 保存数据大小不同:
session中对数据大小没有限制,cookie对象中最多能保存4KB数据,而浏览器中保存的cookie对象也是有限的,不同的浏览器保存的cookie对象数据量不同,在20~50之间 - 有效时长不同:
session在服务器端的有效时长为从闲置开始的30min;cookie的有效时长是一次会话(cookie.setMaxAge(int):参数默认-1;负数:指cookie的有效时长是一次会话;正数:保存给定的分钟,不论中间浏览器是否关闭,表示将cookie对象保存到磁盘指定min;0:删除该cookie对象)
session对象的作用域
一次会话。原因:session对象创建后将sessionID保存到cookie中下发给浏览器,而cookie默认的有效时长是一次会话,即在浏览器没关闭期间,都可以根据cookie中的sessionID找到对应的session对象,从而访问。但是浏览器若关闭,则对应的cookie对象会被销毁,sessionID不再在浏览器中存在,所以重新打开浏览器,无法继续访问之前session对象中的数据
servlet中的四大域对象(了解)
作用:保存数据,需要的时候取数据
PageContext:作用域:当前页面(jsp)HttpServletRequest:作用域:一次请求HttpSession:作用域:一次会话ServletContext:作用域:整个web应用
域对象存取数据的方法都相同,均为:
setAttribute(name,val):存值getAttribute(name):Object:取值
23.描述servlet的生命周期中涉及到哪些方法
servlet默认是单例的:
-
默认情况下:
- 当请求第一次到达时,对应的
servlet进行实例化 - 实例化后立即调用
init方法进行初始化 - 之后,每次请求到达,都会调用
service方法进行处理请求 - 当web应用程序即将结束时,将
servlet销毁,调用destroy方法
- 当请求第一次到达时,对应的
-
servlet的实例化时机:-
默认情况下,是在请求第一次到达时进行实例化
-
还可以在web程序启动时将
servlet进行实例化,需要配置@WebServlet(loadonstartup=true) Userservlet
-
UserServlet{
构造方法
init(){}
service(){}
doGet(){}
doPost(){}
destroy(){}
}
24.转发(forward)和重定向(redirect)的区别
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lyTvvLXg-1688522274671)(../../../AppData/Roaming/Typora/typora-user-images/image-20230701173605237.png)]](https://img-blog.csdnimg.cn/6fc8453bfd6a4809b8cec9aa846b3755.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IeUTnVXV-1688522274672)(../../../AppData/Roaming/Typora/typora-user-images/image-20230701173642010.png)]](https://img-blog.csdnimg.cn/17de7d7dce6c497985d76addd6cb6337.png)
- 转发(forward):
- 是由服务器端完成的
- 客户端发起的是一次请求
- 操作地址栏的地址不会发生改变
- 可以实现数据的共享
- 只能向本应用内的资源发起请求
- 重定向(redirect):
- 是由客户端完成的
- 客户端发起的是两次请求
- 地址栏的地址会发生改变
- 不能实现数据的共享
- 可以向本应用外的资源发起请求
25.拦截器(Interceptor)和过滤器(Filter)的区别
相同之处
- 作用相似,都是对请求进行拦截过滤
- 都可以形成链状结构,在链中的顺序取决于配置顺序
不同之处
- 所属框架不同:
- 过滤器是JavaEE提供,拦截器是Spring提供的
- 作用时机不同:
- 过滤器是在请求到达
Servlet之前进行过滤,拦截器是在Servlet之后,Controller之前对请求进行拦截过滤的
- 过滤器是在请求到达
- 内部方法数量不同:
- 过滤器:内部只有一个抽象方法,
doFilter(),在该方法内部写过滤功能的代码实现 - 拦截器:内存有三个抽象方法,
preHandle()、postHandle()、afterCompletion()preHandle():最常用的,当请求在servlet之后,到底controller之前调用该方法postHandle():DispatcherServlet渲染视图之前执行afterCompletion():在请求即将结束时调用该方法,通常用于释放资源
- 过滤器:内部只有一个抽象方法,
- 配置方式不同:
- 过滤器只能配置黑名单
- 拦截器既可以配置黑名单也可以配置白名单
26.乐观锁和悲观锁
乐观锁和悲观锁都是两种思想
- 乐观锁:不是使用锁来保证线程安全的,而是使用版本号机制来保证线程安全
- 悲观锁:是真正使用锁来保证线程安全的
- 特点:保证线程安全的同时并发执行效率低
- 应用:排它锁、 Java的
synchronized
27.mybatis中 ${ } 与 #{ } 的区别
#{}:实现类预编译${}:没有实现预编译,通常用于做字符串拼接
28.请描述 SpringMVC 的五大组件并描述 SpringMVC 对请求的处理流程
DispatcherServlet:中央处理器HandlerMapping:映射器Controller:控制器ModelAndView:视图数据模型ViewResolver:视图解析器
- 请求先到达
DispatcherServletDispatcherServlet调用HandlerMapping来对请求解析解析,可以找到对应的Controller以及方法- 到达对应的
Controller中对应的方法,对请求进行处理Controller处理请求结束,返回ModelAndView给DispatcherServletDispatcherServlet调用ViewResolver来对视图进行解析DispatcherServlet进行视图的渲染
29.Spring 中 Bean 的作用域
通过属性scope来设置bean的作用域:
属性值:
-
singleton:默认,单例 -
prototype:原型,每次注入都会重新实例化 -
request:每次请求中,若需要某个bean对象,都会重新实例化 -
session:bean的作用域为session,即新创建session对象,会重新实例化,session对象销毁,该bean对象销毁 -
global-session:在portlet容器中存在的对象,该对象作用于整个应用程序,bean作用于整个golbal session对象中。在web应用中不存在该对象
30.说说自动装配注解 Resource 和 Autowired 的区别
- 所属框架不同
@Resource:是由Java提供的@Autowired:是由Spring提供的
- 注入方式不同
@Resource:默认先按照bean的name进行注入,若name不存在则自动按照type进行注入,若通过注解指定了name,若找不到则注入失败@Autowired:直接按照type来注入
31.请描述mybatis中的一级缓存和二级缓存
前提了解:
- 数据库中若执行单个增删改操作,会自动为其开始事务,若在
service层为某个方法开始了事务管理,(通过spring的声明式事务管理),则数据库中不再为操作开始事务,因为业务层的事务管理就是数据库中的数据管理 - 持久层访问数据库时,每次访问均需要
sqlsession对象,有了该对象才能访问数据库,而sqlsession对象是由mybatis中的sqlsessionFactory来提供的,这里使用了工厂模式,每次访问数据库时,都会从该工厂中获取一个sqlsession对象,对数据访问 - 注意:同一个事务中共享一个
sqlsession对象
mybatis的一级缓存是sqlsession级别的缓存,同一个事务中共享一个sqlsession对象,在事务中若执行查询操作,会将查询到的数据缓存到一级缓存中,后续若再次查询相同的数据,直接从缓存中获取即可(查询操作顺序:先去一级缓存查,若有则直接返回,若无再去数据库查)但是要注意:若事务中在查询后执行update操作,此时清空一级缓存一级缓存的意义:提高查询效率(对数据库IO操作是ms级别;对内存IO操作是ns级别)
mybatis的二级缓存是mapper/namespace级别的缓存,二级缓存默认关闭,若想使用,必须通过设置开启如何开启二级缓存:
- mybatis的配置文件中添加属性:cachable:true
- 在想开启二级缓存的mapper的xml文件中添加一组标签(添加为
<mapper>的子标签)<cache></cache>或<cache/>二级缓存可以实现跨sqlsession数据的共享,但是若操作该mapper的多个sqlsession中,有一个执行了update操作,则立即清空二级缓存
一级缓存、二级缓存都存在时,事务的查询顺序:二级缓存 -> 一级缓存 -> 数据库
32.mybatis的动态sql
-
if标签:<select id = "findActiveBlogLike" resultType = "Blog"> SELECT * FROM BLOG WHERE state = 'ACTIVE' <if test="title != null"> AND title like #{title} </if> <if test = "author != null and author.name != null"> AND author_name like #{author.name} </if> </select> -
choose、when、otherwise标签:<select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BLOG WHERE state = 'ACTIVE' <choose> <when test="title != null"> AND title like #{title} </when> <when test="author != null and author.name != null"> AND author_name like #{author.name} </when> <otherwise> AND featured = 1 </otherwise> </choose> </select> -
trim、where、set标签:<select id="findActiveBlogLike" resultType="Blog"> SELECT * FROM BLOG <where> <if test="state != null"> state =#{state} </if> <if test="title != null"> AND title like #{title} </if> <if test="author != null and author. name != null"> AND author_name like #{author.name} </if> </where> </select> <!-- where元素只会在子元素返回任何内容的情况下才插入“WHERE”子句,且子句的开头为“AND”或“OR”,where 元素也会将它们去除。 如果where元素与你期望的不太一样,你也可以通过自定义trim元素来定制where元素的功能。比如,和where元素等价的自定义trim元素为: --> <trim prefix="WHERE" prefixOverrides="AND | OR "> </trim> -
set标签< update id="updateAuthorIfNecessary"> update Author <set> <if test="username != null">username=#{ username},</if> <if test="password != null">password=#{ password},</if> <if test="email != null">email=#{email},</if> <if test="bio != null">bio=#{bio}</if> </set> where id=#{id} </update> -
foreach标签<select id="selectPostIn" resultType="domain.blog.Post"> SELECT * FROM POST P WHERE ID in <foreach item="item" index="index" collection="list" open="(" separator = "," close=")"> #{item} </foreach> </select> <!-- 各属性的意义: collection: 遍历的对象类型 item: 给出引用,指向遍历得到的元素对象 index: 序号 open: 所有遍历到的元素最开始以..开头 close: 所有元素遍历结束,以...结尾 separator: 遍历到的元素之间的分隔符 --> <!-- 你可以将任何可迭代对象(如List、set等)、Map对象或者数组对象作为集合参数传递给foreach。当使用可迭代对象或者数组时,index是当前迭代的序号,item的值是本次迭代获取到的元素。当使用Map对象(或者Map. Entry 对象的集合)时,index是键, item是值。 -->
33.请简述Spring的两种核心技术
- 组件类注解:
@Controller@Service@Repository--持久层组件@Component--通用组件@Configuration--配置组件@Bean
- SprignMVC中的注解:
@RestController=@Controller+@Responsebody@ResponseBody--将返回的数据封装到响应体中返回@RequestMapping--定义请求映射路径@GetMapping--只处理get请求@PostMapping--只处理post请求@RequestParam--对接收到的参数进行判断
- 组件扫描注解:
@ComponentScan@Autowired--注入对象@Transactional--开启事务管理@SpringBootApplication--启动类注解
34.请说出几个Spring中的注解以及其作用
-
IOC(Inversion of control):将对象的创建权交给Spring去管理DI:依赖注入IOC和DI的区别:IOC描述的是现象;DI是过程
-
AOP(aspect orientedprogramming):-
AOP是一种思想,具体实现运用到反射 -
反射
reflect:反射是用于在运行期执行一些操作(创建对象、调用方法、获取类的内部信息) -
目的:实现关注点代码和业务代码的分离解耦,从而提高关注点代码的可维护性和可扩展性
-
AOP的底层是动态代理机制:
运行期通过代理机制将关注点代码织入到业务代码中,产生的新对象叫做代理对象,运行期执行的是代理对象中融合之后的方法代码
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qOw1JhEb-1688522274673)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704114722074.png)]](https://img-blog.csdnimg.cn/22f49873a65d4bed9e24446119186c28.png)
-
动态代理机制分类
-
JDK动态代理:为实现类接口的目标对象生成代理对象
生成代理对象需要什么:
- 创建一个实现了接口的目标对象
- 创建切面类对象,保存增强代码 / 关注点代码
- 实现
InvocationHandler接口
- 实现
- 使用JDK的动态代理机制生成代理对象
- 调用代理对象中的方法,看执行结果是否为融合后的代码
-
CGLIB动态代理:为没有实现接口的目标对象生成代理对象
- 创建一个没有实现接口的目标对象
- 创建增强类对象
- 实现
MethodInterceptor接口
- 实现
- 使用CGLIB的api方法生成代理对象
- 调用代理对象中的目标方法,看执行的结果是否为组合后的代码
-
AOP代理机制的选择:Spring的AOP会自动根据目标对象是否实现了接口来智能的选择动态代理机制;若目标对象实现了接口,则选择JDK动态代理机制,若目标对象没有实现接口,则自动选择CGLIB动态代理机制
注意:从SpringBoot2.xx版本开始,不论目标对象是否实现了接口,均会默认选择CGLIB动态代理机制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xo3ogT3k-1688522274673)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704113825006.png)]](https://img-blog.csdnimg.cn/33ad2f78a7814acaa8fcb30bf58a6df0.png)
- 专业术语:
aspect:切面advice:通知 切面类中的方法joinPoint:连接点pointcut:切点 关注点代码切入的连接点叫做切点weaving:织入
- 通知类型:
- 前置通知:
@Before - 后置通知:
@After - 环绕通知:
@Around - 返回后通知:
@AfterReturing - 抛出异常后通知:
@AfterThrowing
- 前置通知:
AOP的应用
- Spring的声明式事务管理
- 记录日志
- 性能统计
反射
反射:反射是用于在运行期执行一些操作(创建对象、调用方法、获取类的内部信息)
反射API:
-
在运行期获取类信息
-
获取类对象:
Class cls = Test.class Class cls = 对象.getClass() -
获取类中的所有属性:
Field[] fields = cls.getFields(); getFields() //获取所有公有成员变量 getDecalredFields(); //获取所有成员变量 getDecalredField(String name):Field; //获取类中指定名称的成员变量 getField(String name):Field; //获取类中指定名称的公有的成员变量 -
获取类中的方法:
getMethods():Method[] getDecalredMethods():Method[] //获取本类中声明的所有方法,不包括继承的 getMethod(String name,Class... paramterTypes) //通过方法名和参数列表获取公有的方法 getDecalredMethod(String name,Class... types) //通过方法名和参数列表获取声明的方法
-
-
在运行期执行操作
-
根据类名加载类对象
Class cls = Class.forName(className); -
创建对象
Object obj = cls.newInstance(); -
调用方法
Object returnVal = method.invoke(Object target,Object... arg); //调用Method类中的方法 /* target:该方法所属的对象 args:调用方法传递的参数 */
-
35.JVM的结构以及如何调优
JVM的结构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nx8MnknV-1688522274674)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704141737972.png)]](https://img-blog.csdnimg.cn/789ab98cd2fb4b2faaf029d98e0d957b.png)
-
元空间:从JDK1.8开始的叫法,其实就是以前的方法区,但是和方法区也有区别。方法区的数据保存在JVM的内存上;但是元空间是将数据直接保存到物理磁盘上
-
类装载子系统:所有的.class文件的数据加载到元空间,以方便运行调用
-
程序执行引擎:执行代码,并将执行到的代码的行号记录到程序计数器
-
程序计数器:
-
本地方法栈:服务于本地方法(
native修饰的方法),本地方法内存的所有局部变量都保存在本地方法栈中,其内部结果和栈相同的,都是为调用的方法分配栈帧区域,该方法内部的局部变量保存在这个栈帧中 -
栈(JVM栈 / 线程栈):即会为每个线程分配一块区域,在该线程内部调用方法,会在该区域中为方法开辟一块栈帧区域,方法内部的局部变量都保存在该栈帧区域中
- 局部变量表:保存的一直都是所知局部变量和数据
- 操作数栈(先进后出):中间过程所可能出现的任何操作数,取需要出栈,产生需要入栈
- 动态链接:当前方法保存在元空间上的地址,想调用可在这里直接查看到地址,在元空间找到执行
- 方法出口:保存当前方法执行结束要返回到其他那个方法的那个位置去,保存其他某个方法的行号用到了程序计数器
-
堆:采取分代思想,分为年轻代(
young generation)、年老代(old generation),年轻代:年老代 = 1:2;-
年轻代:
Eden区、S0区、S1区(Suvivor 幸存者区)Eden:S0:S1= 8 :1 :1年轻代工作原理:
新创建的对象会保存到Eden区,当Eden区内存不足时,会触发minor gc,会对整个年轻代进行回收,在回收之前,会使用可达性分析算法,从栈开始,标记正在使用的对象,将使用的对象保存到S0区,然后对Eden和S1区进行回收,保存到S0的对象的年代数会+1,后续若再次Eden内存不足时,将正在使用的对象存入另一个s区(S1区),然后对Eden和S0进行回收,当对象的年代数达到15,会将对象移入到年老代中 -
年老代:创建时太大的对象会直接保存到年老代;从年轻代产生,年代数达到15的对象
年老代工作原理:
年老代中会保存大的对象和年代数达到15的对象,当年老代内存不足时,会触发
full gc,会对整个堆内存进行回收,且会造成STW(stop the world),用户会有卡顿的体验,若频繁的触发full gc,用户的体验非常差,此时就需要进行JVM调优
注:
minor gc和full gc都会触发STW,但是minor gc回收内存小,所以造成的卡顿几乎感觉不到,所以minor gc触发频率可以高,但是full gc是对整个堆内存回收,造成的卡顿用户感觉很明显,所以要尽可能的减少full gc的触发 -
JVM的优化
- 尽可能减少大对象的产生
- 操作文件时,尽可能的多次操作
- 尽可能让对象在年轻代被回收走
- 尽可能的扩大年轻代的大小
- 直接扩大堆内存大小
- 调整年轻代比例
- 可以调整
Eden和两个S区的比例 - 调整年轻代和年老代的比例(慎用)
- 可以调整
- 尽可能的扩大年轻代的大小
- 更换
CMSGC为G1GC
JVM堆内存大小的调整
修改JVM堆大小的方式:
-
找到Idea安装目录下的 --> bin -->
idea.exe.vmoptions-server -Xms128m //堆初始大小 -Xmx512m //最大堆内存 -XX:ReservedCodeCacheSize=240m -XX:+UseConcMarkSweepGC //指定GC -XX:SoftRefLRUPolicyMSPerMB=50-ea -XX:CICompilerCount=2-Dsun.io.useCanonPrefixCache=false -Djdk.http.auth.tunneling.disabledSchemes="" -XX:+HeapDumpOnOutOfMemoryError -XX:-OmitStackTraceInFastThrow -Djdk.attach.allowAttachSelf=true -Dkotlinx.coroutines.debug=off -Djdk.module.illegalAccess.silent=true /* 堆配置: -Xms 初始堆大小 -Xmx 最大堆大小 -XX:Newsize=n: 设置年轻代大小 -XX:NewRatio=n: 设置年轻代和年老代的比值, 如:为3表示年轻代和年老代比值为1:3,年轻代占堆内存的1/4 -XX:SurvivorRatio=n: 年轻代中Eden区与两个Survivor区的比值 注意Survivor区有两个。如3表示Eden: 3 Survivor: 2,一个Survivor区占整个年轻代的1/5 -XX:MaxPermSize=n: 设置永久代大小 永久代:元空间 */
36.说一说年轻代、年老代的工作原理
年轻代
-
新创建的所有对象都会到达Eden区
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yiK3swds-1688522274674)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704145417703.png)]](https://img-blog.csdnimg.cn/f75492ff144e4f2a9ece6b70b7c067e5.png)
-
当Eden区内存不够会触发
minor GC,在此之前会通过可达性分析算法标记出当前正在被使用的对象,标记之后将所有标记对象复制到两个Suvivor区之一,此时的Suvivor区为 S0区。对象每移动一次,其自身年代数+1- 可达性分析算法:从栈内存入手,堆里的对象如果正在被使用,其对他的引用一定保存在栈中,根据栈中的局部变量判断有没有指向的对象,有则表示正在被使用,会对其进行标记,且对标记对象再检测判断有没有指向的对象从而再标记
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c60fU22b-1688522274682)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704145211809.png)]](https://img-blog.csdnimg.cn/db25b471a3c542c9b7da73122481e7e7.png)
-
在触发
minor GC之后,会将Eden区和另一个Suvivor区全部进行回收,继续创建新对象,直到当一个Suvivor区内存也不足,将所有正在被使用的对象复制到另一个Suvivor区,且自身年代数+1![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BDZDo6II-1688522274682)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704150943772.png)]](https://img-blog.csdnimg.cn/25a5a60368c14e0da91a79c4adbff18d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fyTy1sFI-1688522274683)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704151012335.png)]](https://img-blog.csdnimg.cn/a978f08630334faaa3277021a196f330.png)
-
直到
Suvivor区中的对象年代数为15时,如果仍在使用,则移入老年代;同样当一个对象过大,创建时不够存入年轻代中将直接移入老年代。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iOT79Vpa-1688522274683)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704151100313.png)]](https://img-blog.csdnimg.cn/7d13896de320491888f1cc3197aef6b5.png)
年老代
创建时太大的对象和年代数达到15的对象会保存到年老代,当年老代内存不足时会触发full GC,会对整个堆内存进行回收,包括年轻代,且产生STW(Stop The World),让程序除了full GC其余所有线程暂停,所以要尽可能少产生full GC
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PUParVIT-1688522274684)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704153353096.png)]](https://img-blog.csdnimg.cn/4b14a86976e241148c642f1194d15ce8.png)
37.GC的分类
SerialGC:单线程ParalleGC:并行情况作用的GCConcMarkSweepGC:并发情况作用的GC,从JDK1.5开始默认提供的G1GC:从JDK1.9开始默认提供的(JDK1.9版本的堆内存结构不再是之前的结构,而是使用块结构,但是依然保留分代思想)
G1GC:JDK1.9之后堆内存结构变为块结构,当内存不足回收时按块回收,
G1GC有一个后台线程会记录当前回收利用率最高的块,将其作为最优先回收的块,若回收后够用,则不再继续回收,大大降低STW的时间。回收后,该块下次可以作为不同的区使用,所以相当灵活
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cAAXqPwC-1688522274685)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704162323741.png)]](https://img-blog.csdnimg.cn/0d19009beeca42f89d114fd13211b7f2.png)
38.GC垃圾回收机制的常用算法
-
复制算法:
minor gc使用 -
标记清除算法
-
回收后的内存不连续,内存利用率低
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-91pcBCrO-1688522274685)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704163415166.png)]](https://img-blog.csdnimg.cn/2659027b7fc9486689077ed66995a9dd.png)
-
-
标记整理算法
- 回收后,将使用的对象进行整理,将可利用的内存整理到一起,实现内存连续,内存利用率变高
39.数据库的主从复制,读写分离,分库分表
数据库的读写分离,主从复制,分库分表都是为了优化数据库
比如现在只有一台数据库服务器,若某写操作会给表加锁,此时其他所有并发操作的效率都会受到影响,采用读写分离,master用于写操作,多台salve用于读操作,在写的同时不会影响读操作,且多台salve用于读,可以大大提高并发读取的效率,在读写分离的情况下必须保证master和salve上的数据一致,所以需要主从复制
分库分表也是优化数据库的措施,可以降低服务器的压力,提高执行效率
40.redis的哨兵模式
redis是非关系数据库,作用在项目的数据持久层(数据访问层)。使用redis的哨兵模式必须是实现了读写分离的主从复制
redis的哨兵模式用于在master宕机时,快速的从slave中选举出一个,成为新的master,并通知其他的slave,告知master发生了改变,让他们重新建立关系,从而保证系统正常运行
具体细节:
哨兵系统中是由若干个哨兵实例组成的,每个哨兵实例均会和每台服务器通过心跳机制,保持联系,若某个sentinel接收不到master的响应,则主观认为master宕机,但是master不一定真的宕机,可能是网络不好引起的。此时sentinel会向其他的sentinel发起询问,判断master是否真的宕机,其他的sentinel会通过心跳机制来检测是否能收到master的响应,若超过半数的sentinel都收不到响应,则客观认为master宕机,从slave中投票选举出一台服务器作为新的master,并通知其他的slave和新的master重新建立联系
-
一个
master用于读数据,多个slave用于写数据,多个slave集群连接![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q1t9UYdV-1688522274686)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704165947098.png)]](https://img-blog.csdnimg.cn/856e378ccd574254a0a3d93afe8f6f01.png)
-
sentinel通过心跳机制连接服务器,某个sentinel接收不到master的响应,主观认定为宕机,会向其他的sentinel发起询问,判断master是否真的宕机![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sNHhBwY4-1688522274686)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704170342325.png)]](https://img-blog.csdnimg.cn/c4884f56d8d848c0a6ed58e9a437a6b6.png)
-
从
slave中投票选举新的master,并通知其他的slave和新的master重新建立联系![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PTLEUkax-1688522274687)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704170259578.png)]](https://img-blog.csdnimg.cn/6989852edc5341a9b7cd40e041695daa.png)
41.redis的五种数据类型,分别应用场景
redis保存数据是以key-value的形式保存的,其中key一定是String类型,而value的数据类型有5种:
-
String:保存字符串,可以是整数,整数可以实现自增长,进行加减incr key //增1 decr key //减1应用:保存点击量
-
hash:特别适合用于保存对象应用:购物车
-
list:保存字符串数据,元素有序,redis3.2之前数据结构采用ziplist和LinkedList来保存数据,从redis3.2版本开始采用quickList,quickList是ziplist+LinkedList,整体结构是双向链表,每个节点的元素保存的是ziplist![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oJQQtNFN-1688522274687)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704181927644.png)]](https://img-blog.csdnimg.cn/08394c552ec44b08b77d64a46981ad8d.png)
应用:微信点赞
-
set:保存String类型的无序集合,元素唯一,底层为散列表应用:黑名单
-
sorted set:数据结构为散列表,保存字符串,必须携带分数存入,会根据分数进行升序排列;字符串作为key,分数作为value,字符串唯一存在,分数可以重复,分数可以相同,若存入的字符串已经存在,则后来的分数覆盖之前的分数应用:排行榜
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OkXyUijP-1688522274687)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704183018478.png)]](https://img-blog.csdnimg.cn/0207ab7569dc4eee835415a60a661bb5.png)
42.SpringCloud的五大组件和作用
SpringCloud是微服务框架,NetFlix(奈飞)公司刚开始提供了5个独立的微服务组件,五大组件之间若想配合使用,必须进行相关的配置,五个组件都配合,配置比较繁琐,而SpringCloud帮我们完成了这件事,相当于一个一站式服务平台
Zuul:网关,用于路由请求 GatewayEureka:注册和发现中心,用于注册和拉取微服务 NacosRibbon:负载均衡,用于将请求均衡的路由到一个服务中的多台服务器上 Feign- ribbon有均衡策略实现负载均衡:默认是轮询策略
Hystrix:熔断器,用于避免雪崩效应的- 实现方式:当服务器出现问题,进行服务降级,从而避免雪崩效应
Config:配置中心,用于保存一些共有的配置信息 Nacos
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ujXYFDAM-1688522274688)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704193511104.png)]](https://img-blog.csdnimg.cn/c4992e1c7e3f40659745de7d6c073626.png)
43.同步通讯和异步通讯的区别
以请求为例:
- 同步通讯是指客户端发起的请求,必须等待之前请求结束之后才能发起
- 异步通讯是指客户端发起的请求,无需等待之前请求结束即可发起
以多线程并发为例:
- 同步通讯是指某个线程必须等待之前的线程执行结束才能执行
- 异步通讯是指某个线程无需等待其他线程执行结束即可执行
44.Ribbon和Feign的区别
相同:
Ribbon和Feign都是用于实现负载均衡的,Feign是基于Ribbon,提供了更多方便的操作- 二者均是发送HTTP请求
区别:
-
Ribbon需要手动构建HTTP请求,Feign无需手动构建HTTP请求,而采用接口式编程,来发起请求![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ibl3ljx2-1688522274688)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704194759995.png)]](https://img-blog.csdnimg.cn/48066f5abea94202903b8e59682acafd.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WpaOf9yW-1688522274689)(../../../AppData/Roaming/Typora/typora-user-images/image-20230704195026207.png)]](https://img-blog.csdnimg.cn/bc9685964ee246d6a0b10a39e74e9c7f.png)
45.Linux命令
详细命令请看这篇文章