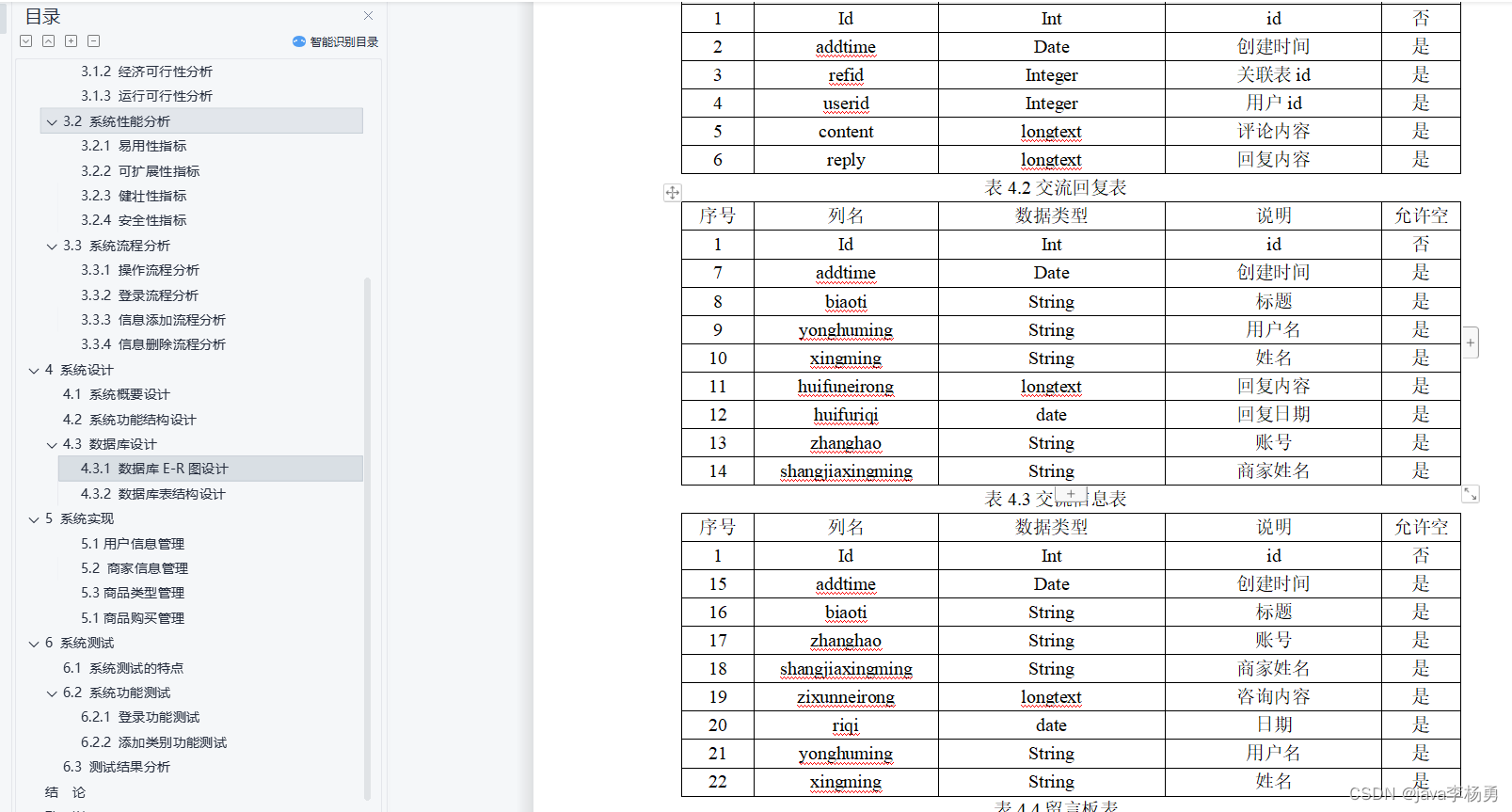
在最近的AIGC社区中,3D视觉生成领域越来越受到广泛的关注,以神经辐射场(NeRFs) 为基础的深度渲染网络向大家展示了非常惊艳的三维效果。可是,NeRFs需要大量的多视角图片作为监督,因而从单张2D图像进行3D重建依然具有极大的挑战性。本文介绍一篇来自KAUST、牛津大学VGG组和Snapchat合作完成的工作 Magic123(One Image to High-Quality 3D Object Generation using Both 2D and 3D diffusion Pirors)。Magic123是一个两阶段的从粗到细的3D生成框架,其提出同时使用2D和3D视觉先验来从单张图像进行三维重建,下图是Magic123与其他基线方法的生成效果对比。

作者选取了泰迪熊、龙雕像、马和彩色茶壶四种物体进行展示,可以看出,Magic123的三维重建效果较为完整,且非常符合对应真实物体的三维形状和纹理,而参与对比的两个最新方法Neural Lift[1]和RealFusion[2](均发表在CVPR2023上),在物体三维形状和纹理细节控制等方面均存在一定的缺陷,其中Neural Lift甚至生成了两个马头的乌龙效果。Magic123能够产生更好的效果,主要得益于两点:
- 作者们同时使用2D和3D先验,促使模型在重建想象力和三维一致性之间达到平衡,且具有更好的泛化能力;
- 二阶段训练,在第一阶段,作者通过优化NeRF网络来产生一个粗略的几何形状,在第二阶段再将其不断细化为纹理丰富的高分辨率三维网格。


论文链接:
https://arxiv.org/abs/2306.17843
项目地址:
https://guochengqian.github.io/project/magic123
代码仓库:
https://github.com/guochengqian/Magic123

一、 引言
虽然人类通常使用2D的方式来观察世界,但人脑拥有非常强大的三维想象和推理能力。如何模拟人脑的三维推理能力,是目前三维视觉领域研究的热点问题。3D图像合成模型需要在生成三维物体的同时,尽可能的保留与原物体一致的几何和纹理细节。但是目前仅通过单张图像完成三维重建的方法仍然存在性能瓶颈,作者认为,这主要有由以下两个原因造成:(1)现有的方法通常依赖于大规模标注的3D数据集,这限制了模型在未知域的泛化能力。(2)现有方法在处理3D数据时,生成3D对象的细节和模型的计算资源之间难以进行良好的权衡。如下图所示,作者分别使用泰迪熊、甜甜圈和龙雕像作为三种不同的三维重建情况,由于泰迪熊比较常见,因此模型仅通过学习3D先验就可以将其较好的复原出来。而对于左下角的龙雕像,仅通过有限标注的3D数据集已经无法满足要求,生成的几何结构虽然具有三维一致性却缺少细节。

与3D生成模型相比,2D图像生成模型的发展显然更加迅速和完善,现有的2D生成模型使用海量的文本标注图像进行训练,可以涵盖的图像语义非常广泛,因此使用2D模型作为先验来生成3D内容已经成为一种非常流行的方法,如DreamFusion [6]。但是作者发现,完全依赖2D先验会产生严重的3D不一致性,如Janus problem (生成多个脸),不同视角物体大小和材质不一致等。因此本文的Magic123提出,同时利用3D先验和2D先验,并在它们之间设置一个权衡参数,来达到动态调节3D模型生成效果的目的。除此之外,作者发现,传统的NeRF会占用大量的显存,这导致模型渲染的图像分辨率较低,影响了3D生成的细节,因此作者在Magic123的第二阶段中引入了内存高效的混合3D网格表示,可以将最终的生成分辨率提高到1K,同时细化生成对象的几何纹理和细节。
二、 本文方法
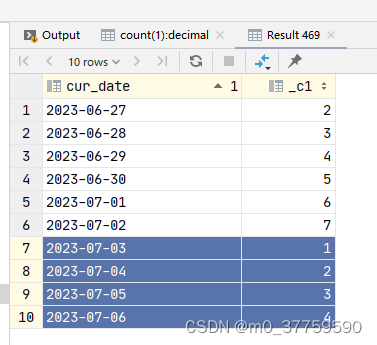
Magic123综合考虑了2D和3D图像生成时的扩散先验,并以一种两阶段(从粗到细)的形式完成从单张图像进行三维重建的任务,Magic123的整体框架如下图所示。
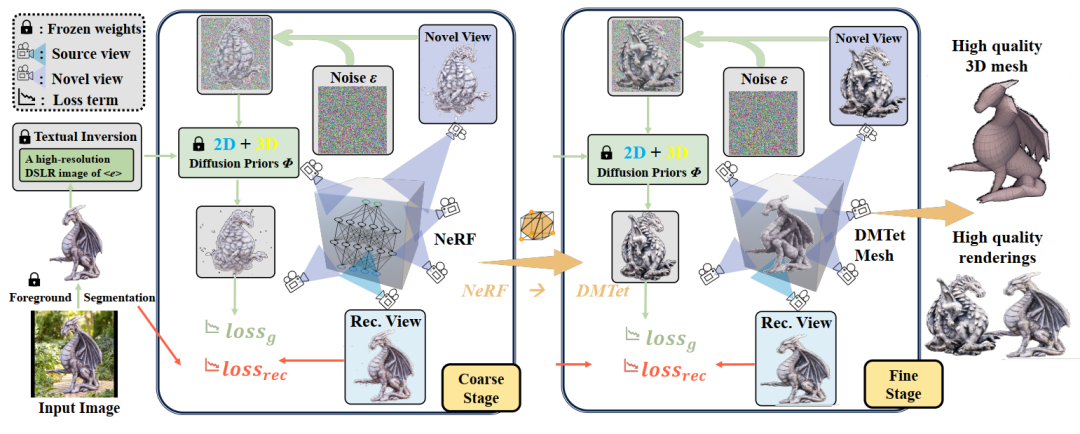
2.1 粗阶段
如上图左半部分所示为Magic123的粗生成阶段,在一过程中,模型重点优化图像的基础几何结构,这一过程主要使用NeRF进行生成。Magic123首先部署了一个预训练的分割模型Dense Prediction Transformer[3]来从给定的单张图像中提取前景目标。此外,在粗阶段,作者综合考虑了NeRF合成时所需的图像重构监督、新视角图像的引导、生成3D对象的深度先验以及NeRF自身的伪影合成缺陷等因素。并根据这些因素分别设计了对应的损失函数,来联合优化整体模型:
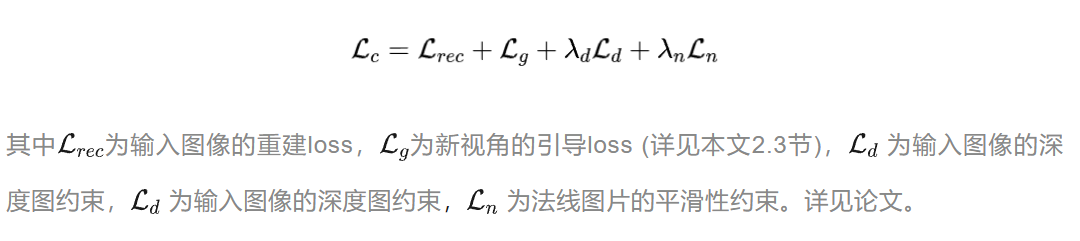
2.2 细阶段
由于NeRF庞大的计算开销并且容易引入伪影噪声,因此粗阶段只能生成低分辨率的半成品3D模型。Magic123的细阶段采用了一种混合SDF-Mesh表示,即DMTet[4],其大大优化了NeRF合成时的显存效率,作者提到,先前资源效率较高的NeRF替代方案Instant-NGP在16GB显存GPU上也只能达到128128分辨率,而本文Magic123框架在DMTet的加持下,可以轻松合成渲染图像分辨率1K的高精度三维模型。
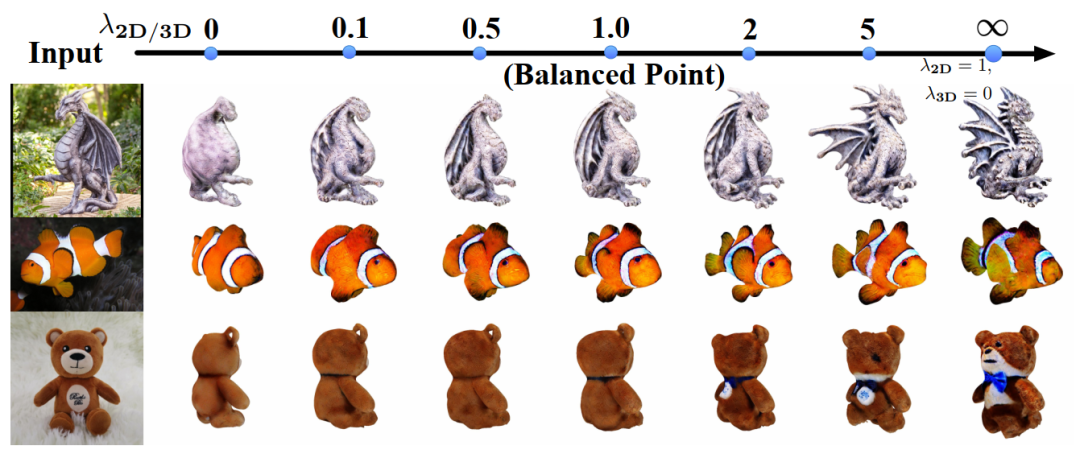
2.3 2D先验和3D先验的权衡
Magic123中所参考的2D图像先验来源于Stable Diffusion中的分数蒸馏采样损失(score distillation sampling,SDS),SDS主要作用在图像的扩散过程中,其首先将渲染视图编码到隐空间中,并为其添加一定的噪声,然后根据输入文本提示来预测出去噪的新视图,SDS构建起了渲染视图内容和文本提示之间的一道桥梁。SDS损失的定义如下:


作者随后发现,在图像合成的过程中,使用2D先验和3D先验实际上是互补的,2D先验具有很强想象力拥有使模型探索几何空间的能力,但是会导致生成3D模型的几何不完整,而3D先验则可以弥补这一缺陷,但是通用性较差以及缺少几何细节。因而作者提出了一种权衡二者的先验损失:

三、 实验效果
本文的实验在NeRF4和RealFusion15两个数据集上进行,评价指标使用PSNR、LPIPS和CLIP相似度,其中前两者用来衡量生成效果的重建图像质量和感知相似性,后者则主要通过CLIP模型计算得到的外观相似性来测量生成内容的3D一致性。作者选取了包括Zero-1-to-3、Neural Lift和RealFusion在内的6种方法进行了对比,下表为3D合成效果性能对比


四、 总结
本文提出了一种从粗到细的两阶段3D合成的Magic123框架,Magic123可以仅从单张随机视角的图像出发,生成具有高度纹理细节的高质量3D模型。Magic123通过权衡模型内部的2D和3D扩散先验,克服了现有3D合成框架中的种种局限性,本文提出的2D、3D权衡参数可以使网络在2D几何和3D形状约束之间探索一种动态平衡的效果,使模型在3D合成过程中,同时兼顾对象的多样性和特殊的3D纹理和细节。
参考
[1] Dejia Xu, Yifan Jiang, Peihao Wang, Zhiwen Fan, Yi Wang, and Zhangyang Wang. Neurallift-360: Lifting an in-the-wild 2d photo to a 3d object with 360{\deg} views. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023[2] Luke Melas-Kyriazi, Christian Rupprecht, Iro Laina, and Andrea Vedaldi. Realfusion: 360{\deg} reconstruction of any object from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.[3] René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision trans ormers for dense prediction. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12159–12168, 2021.[4] Tianchang Shen, Jun Gao, Kangxue Yin, Ming-Yu Liu, and Sanja Fidler. Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis. In Advances in Neural Information Processing Systems (NeurIPS), volume 34, pages 6087–6101, 2021.[5] Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object. arXiv preprint arXiv:2303.11328, 2023.[6] Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. International Conference on Learning Representations (ICLR), 2022.
作者:seven_
Illustration by IconScout Store from IconScout