VIO在ARM上的加速:
VIO在ARM上的加速(1)- ARM加速基础
VIO在ARM上的加速(2)- Neon
VIO在ARM上的加速(3)- Neon在VIO中的应用
1 NEON的概述
ARM 处理器中使用的高级 SIMD 扩展的实现称为 NEON,这是架构规范之外使用的常用术语。
NEON指令只适用于支持NEON的系统。
ARMv7-M不支持NEON,NEON技术只适用于ARM Cortex-A系列处理器。
NEON的指令集只是ARM和THUMB指令集中的子集。
NEON的指令都是以V字母开头。
使用intrinsics(内联函数)不如使用汇编优化效率,这些函数在编译的时候会直接转化成NEON的汇编指令,使用intrinsics没法控制寄存器分配和内存对齐等。
为了支持这些内联函数必须要包含头文件arm_neon.h , 使用NEON技术还要通过在编译的时候加入-mfpu=neon才能起到效果。
NEON注意事项:
(1)、load数据的时候,第一次load会把数据放在cache里面,只要不超过cache的大小,下一次load同样数据的时候,则会比第一次load要快很多,会直接从cache中load数据;
(2)、在做NEON乘法指令的时候会有大约2个clock的阻塞时间,如果你要立即使用乘法的结果,则就会阻塞在这里。乘法的结果不能立即使用,可以将一些其它的操作插入到乘法后面而不会有时间的消耗;
(3)、使用饱和指令的时候,如乘法饱和的时候,在做乘法后会再去做一次饱和,所用时间要比直接做乘法要慢;
(4)、在对16位数据进行load或者store操作的时候,需要注意的是字节移位。
2 NEON数据类型与指令
NEON中的数据类型说明符由一个指示数据类型的字母构成,该字母通常后跟一个指示宽度的数字。
在ARMv7和ARMv8上,NEON支持的数据类型几乎相同,但是ARMv8引入了更多的数据类型支持。
在ARMv7上,NEON支持的数据类型包括:
整数:8位、16位、32位和64位整数
浮点数:32位和64位浮点数
在ARMv8上,NEON支持的数据类型包括:
整数:8位、16位、32位和64位整数,以及128位长整数
浮点数:16位、32位和64位浮点数,以及128位长浮点数
所以,虽然在ARMv7和ARMv8上NEON支持的数据类型几乎相同,但ARMv8引入了更多的数据类型支持。
数据类型针对的是操作数,而不是目标数(结果)。
在ARMv7上,VCVT指令在单精度浮点和以下元素之间进行转换:32 位整数,定点,半精度浮点(如果处理器实现半精度扩展)
在ARMv7上,NEON指令可处理:
(1)、双字向量:八个8位元素、四个16位元素、两个32位元素、一个64位元素;
(2)、四字向量:十六个8位元素、八个16位元素、四个32位元素、两个64位元素。
在ARMv7上,NEON中的正常指令、宽指令、窄指令、饱和指令、长指令:
(1)、正常指令:生成大小相同且类型通常与操作数向量相同的结果向量;
(2)、长指令:对双字向量操作数执行运算,生成四字向量的结果。所生成的元素一般是操作数元素宽度的两倍,并属于同一类型;
(3)、宽指令:一个双字向量操作数和一个四字向量操作数执行运算,生成四字向量结果。所生成的元素和第一个操作数的元素是第二个操作数元素宽度的两倍;
(4)、窄指令:四字向量操作数执行运算,并生成双字向量结果,所生成的元素一般是操作数元素宽度的一半;
(5)、饱和指令:当超过数据类型指定的范围则自动限制在该范围内。
在ARMv7上,有些NEON指令可处理与向量组合使用的标量:
NEON标量可以为8位、16位、32位或64位;
除乘法指令之外,访问标量的指令也可访问寄存器组中的任何元素;
指令语法通过在双字向量中使用索引来引用标量,从而使Dm[x]表示Dm中的第x个元素;
乘法指令仅允许使用16位或32位标量,并且只能访问寄存器组中的前32个标量;
这在乘法指令中意味着:(1)、16位标量限定为寄存器D0-D7,其中x位于范围0-3内;(2)、32位标量限定为寄存器D0-D15,其中x为0或1。
在ARMv7上,NEON支持的数据类型还包括{0,1}上的多项式,使用布尔算法规则处理系数0和1:
(1)、0+0=1+1+0;
(2)、0+1=1+0=1;
(3)、0*0=0*1=1*0=0;
(4)、1*1=1.
也就是说,将两个{0,1}上的多项式相加与按位异或的运算相同,而将两个{0,1}上的多项式相乘则与整乘的运算相同,但部分积执行的是异或运算,而不是相加运算。
向量寄存器
向量寄存器用来存放向量数据,每个向量元素的类型必须相同。向量寄存器根据处理元素的大小可以划分为 2/4/8/16 个通道。

AArch64 向量寄存器
AArch64 有 32 个 128bit 的向量寄存器,这些寄存器又可以划分为:
- 32 个 128bit 的 V 寄存器,V0~V31。
- 32 个 64bit 的 D 寄存器,D0~D31。
- 32 个 32bit 的 S 寄存器,S0~S31。
每种类型寄存器的映射关系如下:

AArchh32 / ARMV7向量寄存器
AArch32/Armv7 有 16 个 128bit 的向量寄存器,这些寄存器又可以划分为:
- 16 个128bit 的 Q 寄存器,Q0~Q15。
- 32 个 64bit 的 D 寄存器,D0~D31。
- 32 个 32bit 的 S 寄存器,S0~S31。
每种类型寄存器的映射关系如下:

汇编指令格式
略
intrinsics指令格式
Intrinsics是一种编程技术,用于在高级语言中直接调用底层硬件指令。它允许开发人员利用底层硬件的并行计算能力和优化指令集,以提高程序的性能和效率。
在ARM架构中,有一套专门的Intrinsics函数,用于调用NEON指令集中的指令。通过使用这些Intrinsics函数,开发人员可以在高级语言中编写并行计算的代码,而无需直接编写汇编语言。这样可以提高开发效率,并且可以充分利用底层硬件的计算能力。
相比于汇编指令,NEON Intrinsics 是一种更简单的编写 NEON 代码的方法,NEON Intrinsics 类似于 C 函数调用,在编译时由编译器替换为相应的汇编指令,使用时需要包含头文件arm_neon.h。
https://developer.arm.com/architectures/instruction-sets/intrinsics/
向量类型
向量类型分为非数组向量和数组向量
- 非数组向量格式 <type><size>x<number_of_lanes>_t
- 数组向量格式 <type><size>x<number_of_lanes>x<length_of_array>_t
<type> 数据类型,如 int/uint/float/poly。
<size> 元素大小,如8/16/32/64。
<number_of_lanes> 通道数。
<length_of_array> 数组中元素个数。
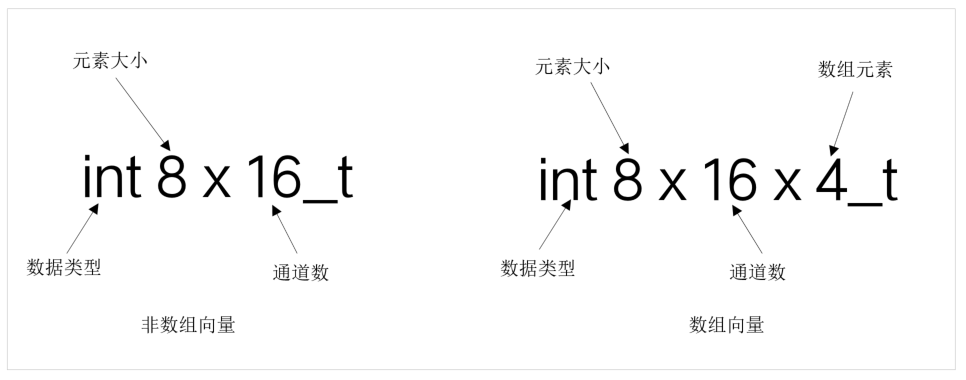
向量类型示意图
内联函数
函数格式如下:v<mod><opname><shape><flags>_<type>
mod表示计算的模式:
- q:表示饱和计算
- h:表示折半计算
- d:表示加倍计算
- r:表示舍入计算
- p:表示pairwise计算
opname表示具体的计算指令,分类如下:
| 功能类别 | 介绍 |
|---|---|
| Load/Store | 对数据进行向量加载和存储,既可以对单个数据进行加载和存储,也可以对向量结构体数据进行加载和存储 |
| Arithmetic | 对整数和浮点数向量加减运算 |
| Multiply | 整型或浮点型的向量乘法运算,同时包含了乘法和加法混合运算,以及乘法和减法的运算的混合运算 |
| Shift | 向量位移操作,其中位移数据可以是立即数也可以是向量 |
| Logical and compare | 包含了逻辑运算(与或非运算等)和比较运算(等于、大于、小于等) |
| Floating-point | 包含了浮点和其他类型数据之间的相互转化操作 |
| Permutation | 对向量进行重排操作 |
| Misecllaneous | 标量数据赋值到向量的操作 |
| Data processing | 一般性处理,极值操作、绝对值差、数值取反、平方根倒数等 |
| Type conversion | 数值类型转换,数据的组合及提取等 |
shape表示有效长度:
- l:表示long,输出向量的元素长度是输入长度的2倍
- n:表示 narrow,输出向量的元素长度是输入长度的1/2倍
- w:表示 wide,第一个输入向量和输出向量类型一样,且是第二个输入向量元素长度的2倍
- _high:AArch64专用,而且和上面的l/n 配合使用。
- 当使用 l(Long) 时,表示输入向量只有高 64bit 有效;
- 当使用 n(Narrow) 时,表示输出只有高 64bit 有效。
- _n:表示有标量参与向量计算
- _lane: 指定向量中某个通道参与向量计算
flags表示是128bit还是64bit:
- q:表示使用 128bit 的向量,否则使用 64bit 的向量。
type表示类型:
表示单个通道的数据类型,有u8、s8、u16、s16、u32、s32、f32、f64。
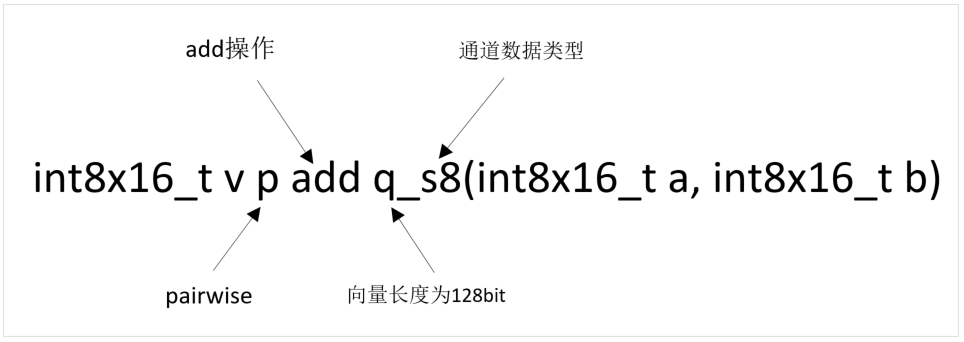
内联函数结构示意图
Load/Store
- Load以解交织的方式加载数据
// 以解交织方式加载数据到n个向量寄存器, n为1~4
Result_t vld[n]<q>_type(Scalar_t *p_addr);
// 以解交织方式加载数据到n个向量寄存器的第N通道, n为1~4
Result_t vld[n]<q>_lane_type(Scalar_t *p_addr, Vector_t M, int N);
- Store以交织的方式存储数据
// 将n个向量寄存器数据以交织方式存储到内存中, n为1~4
void vst[n]<q>_type(Scalar_t* N, Vector_t M);
// 将n个寄存器的N通道数据以交织方式存储到内存中, n为1~4
void vst[n]<q>_lane_type(Scalar_t *p_addr, Vector_t M, int N);
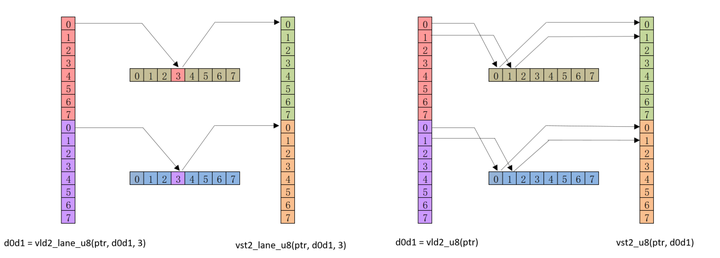
2 个向量中多通道 load/store, 以及单个通道的load/store
Arithmetic
- 整数和浮点数的加减运算。
// 基本的加减操作
Result_t vadd<q>_type(Vector1_t N, Vector2_t M);
Result_t vsub<q>_type(Vector1_t N, Vector2_t M);
// L(Long)类型的指令加减运算,输出向量长度是输入的两倍。
Result_t vaddl_type(Vector1_t N, Vector2_t M);
Result_t vsubl_type(Vector1_t N, Vector2_t M);
// W(Wide)类型的指令加减运算,第一个输入向量的长度是第二个输入向量长度的两倍。
Result_t vaddw_type(Vector1_t N, Vector2_t M);
Result_t vsubw_type(Vector1_t N, Vector2_t M);
// H(half)类型的加减运算;将计算结果除以2。
Result_t vhadd<q>_type(Vector1_t N, Vector2_t M);
Result_t vhsub<q>_type(Vector1_t N, Vector2_t M);
// Q(Saturated)饱和类型的加减操作
Result_t vqadd<q>_type(Vector1_t N, Vector2_t M);
Result_t vqsub<q>_type(Vector1_t N, Vector2_t M);
// RH(Rounding Half)类型的加减运算
Result_t vrhadd<q>_type(Vector1_t N, Vector2_t M);
Result_t vrhsub<q>_type(Vector1_t N, Vector2_t M);
// HN(half Narrow)类型的加减操作
Result_t vaddhn_type(Vector1_t N, Vector2_t M);
Result_t vsubhn_type(Vector1_t N, Vector2_t M);
// RHN(rounding half Narrow)类型的加减操作
Result_t vraddhn_type(Vector1_t N, Vector2_t M);
Result_t vrsubhn_type(Vector1_t N, Vector2_t M);

vhadd_s32 instrisics指令的操作
Multiply
- 整型和浮点型的乘法运算, 参与计算的都是向量
// 基本乘法操作
Result_t vmul<q>_type(Vector1_t N, Vector2_t M);
// l(Long)类型的乘法操作
Result_t vmull_type(Vector1_t N, Vector2_t M);
// QDL(Saturated, Double, Long)类型的乘法操作
Result_t vqdmull_type(Vector1_t N, Vector2_t M);
// 基本的乘加和乘减操作
Result_t vmla<q>_type(Vector1_t N, Vector2_t M, Vector3_t P);
Result_t vmls<q>_type(Vector1_t N, Vector2_t M, Vector3_t P);
// L(Long)类型的乘加和乘减操作
Result_t vmlal_type(Vector1_t N, Vector2_t M, Vector3_t P);
Result_t vmlsl_type(Vector1_t N, Vector2_t M, Vector3_t P);
// QDL(Saturated, Double, Long)类型的乘加和乘减操作
Result_t vqdmlal_type(Vector1_t N, Vector2_t M, Vector3_t P);
Result_t vqdmlsl_type(Vector1_t N, Vector2_t M, Vector3_t P);
// QDLH(Saturated, Double, Long, Half)类型的乘法操作
Result_t vqdmulh<q>_type(Vector1_t N, Vector2_t M);
// QRDLH(Saturated, Rounding Double, Long, Half)类型的乘法操作
Result_t vqrdmulh<q>_type(Vector1_t N, Vector2_t M);
- 带通道类型的乘法操作
// 基本的乘法操作
Result_t vmull_lane_type(Vector1_t N, Vector2_t M, int n);
// 基本的乘加和乘减操作
Result_t vmla<q>_lane_type(Vector1_t N, Vector2_t M, Vector3_t P, int n);
Result_t vmls<q>_lane_type(Vector1_t N, Vector2_t M, Vector3_t P, int n);
// L(long) 类型的乘加和乘减操作
Result_t vmlal_lane_type(Vector1_t N, Vector2_t M, Vector3_t P, int n);
Result_t vmlsl_lane_type(Vector1_t N, Vector2_t M, Vector3_t P, int n);
// QDL(Saturated, Double, long) 类型的乘加和乘减操作
Result_t vqdmlal_lane_type(Vector1_t N, Vector2_t M, Vector3_t P, int n);
Result_t vqdmlsl_lane_type(Vector1_t N, Vector2_t M, Vector3_t P, int n);
// QDH(Saturated, Double, Half) 类型的操作
Result_t vqdmulh<q>_lane_type(Vector1_t N, Vector2_t M, int n);

vmla_lane_s32 intrinsics 指令的操作
- 向量和标量的乘法
// 基本的向量和标量的乘法
Result_t vmul<q>_n_type(Vector_t N, Scalar_t M);
// L(Long) 类型的向量和标量的乘法
Result_t vmull_n_type(Vector_t N, Scalar_t M);
// QDL(Saturated, Double, long) 类型的向量和标量的乘法
Result_t vqdmull_n_type(Vector_t N, Scalar_t M);
// QDH(Saturated, Double, Half) 类型的向量和标量的乘法
Result_t vqdmulh<q>_n_type(Vector_t N, Scalar_t M);
// QRDH(Saturated, Double, Half) 类型的向量和标量的乘法
Result_t vqrdmulh<q>_n_type(Vector_t N, Scalar_t M);
// L(Long) 类型的乘加和乘减操作
Result_t vmlal_n_type(Vector1_t N, Vector2_t M, Scalar_t P);
Result_t vmlsl_n_type(Vector1_t N, Vector2_t M, Scalar_t P);
// QDL(Saturated, Double, long) 类型的乘加和乘减
Result_t vqdmlal_n_type(Vector1_t N, Vector2_t M, Scalar_t P);
Result_t vqdmlsl_n_type(Vector1_t N, Vector2_t M, Scalar_t P);
Shift
- 立即数类型的位移
// 基本的立即数左移和右移
Result_t vshr<q>_n_type(Vector_t N, int n);
Result_t vshl<q>_n_type(Vector_t N, int n);
// R(rounding) 类型的右移操作
Result_t vrshr<q>_n_type(Vector_t N, int n);
// QL(Saturated, long) 类型的右移操作
Result_t vqshl<q>_n_type(Vector_t N, int n);
// 右移累加操作
Result_t vsra<q>_n_type(Vector1_t N, Vector2_t M, int n);
// R(rounding) 类型的右移累加操作
Result_t vrsraq_n_type(Vector1_t N, Vector2_t M, int n);
// Q(Saturated) 类型的左移操作,而且输入是有符号,输出是无符号的
Result_t vqshluq_n_type(Vector_t N, int n);
// N(Narrow) 类型的右移操作
Result_t vshrn_n_type(Vector_t N, int n);
// QN(Saturated, Narrow) 类型的右移操作, 而且输入是有符号,输出是无符号的
Result_t vqshrun_n_type(Vector_t N, int n);
// QRN(Saturated, Rounding, Narrow) 类型的右移操作, 而且输入是有符号,输出是无符号的
Result_t vqrshrun_n_type(Vector_t N, int n);
// QN(Saturated, Narrow) 类型的右移操作
Result_t vqshrn_n_type(Vector_t N, int n);
// RN(Rounding, Narrow) 类型的右移操作
Result_t vrshrn_n_type(Vector_t N, int n);
// QRN(Rounding, Rounding, Narrow) 类型的右移操作
Result_t vqrshrn_n_type(Vector_t N, int n);
// N(Narrow) 类型的左移操作
Result_t vshll_n_type(Vector_t N, int n);
- 非立即数类型的位移
// 左移
Result_t vshlq_type(Vector1_t N, Vector2_t M);
// Q(Saturated) 类型的左移操作
Result_t vqshl<q>_type(Vector1_t N, Vector2_t M);
// QR(Saturated, rounding) 类型的左移操作
Result_t vrshl<q>_type(Vector1_t N, Vector2_t M);
- 移位并插入
// 将向量 M 中各个通道先右移动 n 位, 然后将移动后元素插入到 N 对应的元素中,
// 并保持 N 中每个元素的高 n 位保持不变
Result_t vsri<q>_n_type(Vector1_t N, Vector2_t M, int n);
// 将向量 M 中各个通道先左移动 n 位, 然后将移动后元素插入到 N 对应的元素中,
// 并保持 N 中第每个元素的低 n 位保持不变
Result_t vsli<q>_n_type(Vector1_t N, Vector2_t M, int n);
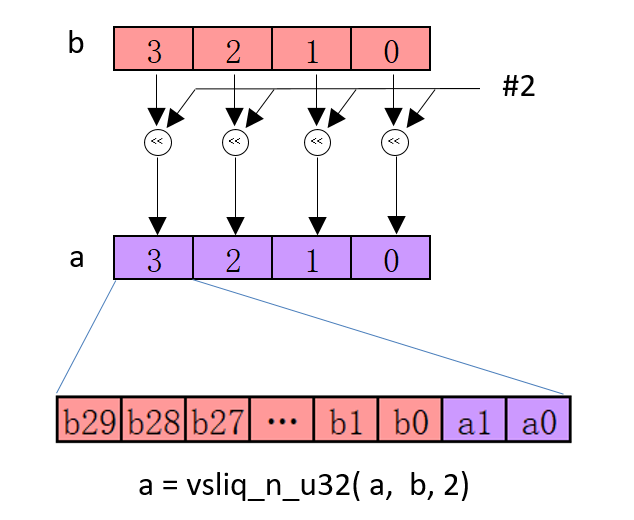
vsliq_n_u32 intrinsics 指令的操作
Logical and compare
eq 表示相等, ge 表示大于或等于, gt 表示大于, le 表示小于或等于, lt 表示小于
- 逻辑比较操作,比较结果为true,输出向量的对应通道将被设置为全 1,否则设置为全0 。
Result_t vceq<q>_type(Vector1_t N, Vector2_t M);
Result_t vcge<q>_type(Vector1_t N, Vector2_t M);
Result_t vcle<q>_type(Vector1_t N, Vector2_t M);
Result_t vcgt<q>_type(Vector1_t N, Vector2_t M);
Result_t vclt<q>_type(Vector1_t N, Vector2_t M);
- 向量的绝对值比较,比较结果为true时,输出向量对应通道将被设置为全1,否则设置为全0。
Result_t vcage<q>_type(Vector1_t N, Vector2_t M);
Result_t vcale<q>_type(Vector1_t N, Vector2_t M);
Result_t vcagt<q>_type(Vector1_t N, Vector2_t M);
Result_t vcalt<q>_type(Vector1_t N, Vector2_t M);
- 按位与\或\非\异或操作
Result_t vand<q>_type(Vector1_t N, Vector2_t M);
Result_t vorr<q>_type(Vector1_t N, Vector2_t M);
Result_t vmvn<q>_type(Vector_t N);
Result_t veor<q>_type(Vector1_t N, Vector2_t M);
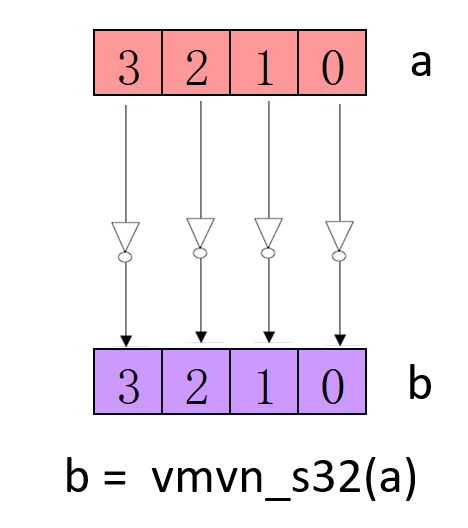
vmvn_s32 intrinsics 指令操作
- 元素与操作
// 按通道做与操作,为 true 时,将输出向量对应通道设置为全 1,否则设置为全 0
Result_t vtst<q>_type(Vector1_t N, Vector2_t M);
- 其他
// M 作为 mask,标识是否对 N 做清零操作。当 M 中某位为 1, 则将 N 中对应位清零
Result_t vbic<q>_type(Vector1_t N, Vector2_t M);
// P 作为 mask,按位 select。当 P 中某位是 1 时,将选择 N 中对应位作为输出,否则选择 M
Result_t vbsl<q>_type(Vector1_t N, Vector2_t M, Vector3_t P);
Floating-point
- 浮点数之间的转化, 以及浮点类型与整数类型之间的转化
// 单精度浮点转化为整数类型
Result_t vcvt<q>_type_f32(Vector_t N);
// 整数类型转化为单精度浮点
Result_t vcvt<q>_f32_type(Vector_t N);
// f16转化为f32
Result_t vcvt_f16_f32(Vector_t N);
// f32转化为f16
Result_t vcvt_f32_f16(Vector_t N);
- 浮点类型的乘加操作
Result_t vfma<q>_type(Vector1_t N, Vector2_t M, Vector3_t P);
- 浮点类型的乘减操作
Result_t vfms<q>_type(Vector1_t N, Vector2_t M, Vector3_t P);

vfms intrinsics 指令操作
Permutation
- 向量提取组合操作
Result_t vext<q>_type(Vector1_t N, Vector2_t M, int n);
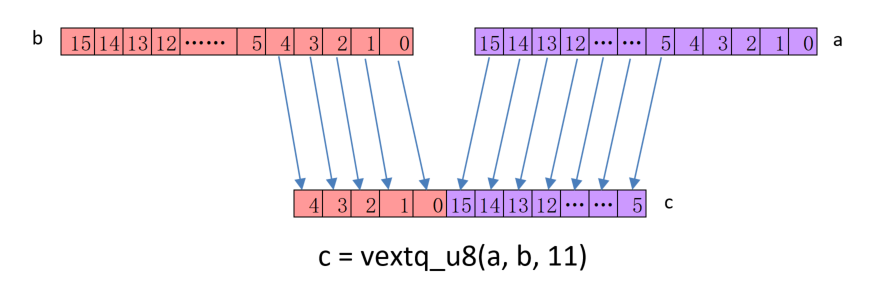
vextq_u8 intrinsics 指令操作
- 查表操作
Result_t vtbl[n]_type(Vector1_t N, Vector2_t M);
Result_t vtbx[n]_type(Vector1_t N, Vector2_t M, Vector3_t P);
- 向量翻转操作
Result_t vrev64<q>_type(Vector_t N);
Result_t vrev32<q>_type(Vector_t N);
Result_t vrev16<q>_type(Vector_t N);
vrev16<q>_type按照 16bit 为块,块内数据按照 8bit 为单位进行翻转 。
vrev32<q>_type按照 32bit 为块,块内数据按照 8bit,16bit 为单位进行翻转 。
vrev64<q>_type按照 64bit 为块,块内数据按照8bit, 16bit, 32bit为单位进行翻转 。

vrev16_s8, vrev32_s8 intrinsics 指令操作
- 旋转操作
旋转指令包含了两种矩阵旋转的指令,TRN1,TRAN2
Result_t vtrn1<q>_type(Vector1_t N, Vector2_t M);
Result_t vtrn2<q>_type(Vector1_t N, Vector2_t M);
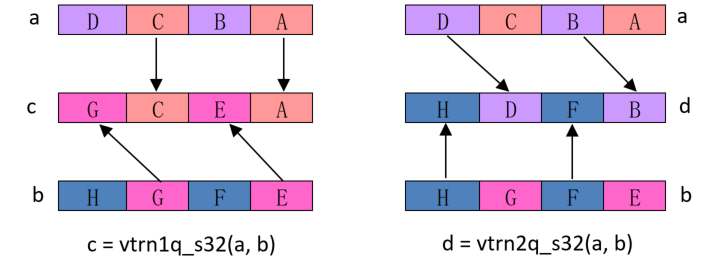
vtrn1q_s32, vtrn2q_s32 intrinsics 指令操作
- 向量交织和解交织操作
// 交织操作
Result_t vzip<q>_type(Vector1_t N, Vector2_t M);
// 解交织操作
Result_t vuzp<q>_type(Vector1_t N, Vector2_t M);

vzip_u8 intrinsics 指令操作
Miscellaneous
- 将同一个标量填充到每个向量通道
Result_t vcreate_type(Scalar_t N);
Resutl_t vdup_type(Scalar_t N);
Result_t vdup_n_type(Scalar_t N);
Result_t vdupq_n_type(Scalar_t N);
Result_t vmov_n_type(Scalar_t N);
Result_t vmovq_n_type(Scalar_t N);
- 将向量中某个通道的数据填充到指定的向量中
Result_t vdup<q>_lane_type(Vector_t N, int n);
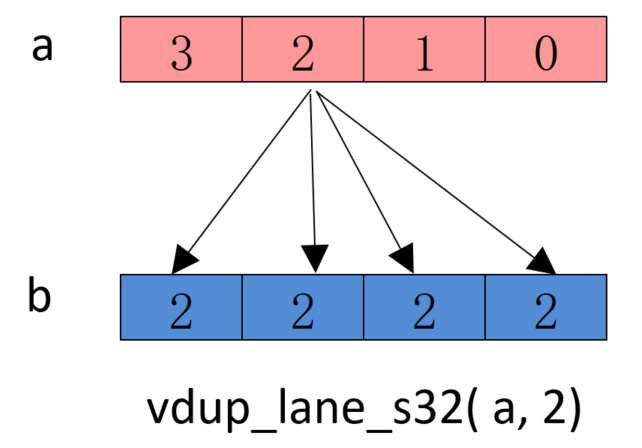
vdup_lane_s32 intrinsics 指令操作
Data processing
- max\min操作
// 基本的 max, min
Result_t vmax<q>_type(Vector1_t N, Vector2_t M);
Result_t vmin<q>_type(Vector1_t N, Vector2_t M);
// pairwise 类型的 max, min
Result_t vpmax_type(Vector1_t N, Vector2_t M);
Result_t vpmin_type(Vector1_t N, Vector2_t M);

vpmin_s16 intrinsics 指令操作
- 差的绝对值操作
// 基本的绝对值计算
Result_t vabs<q>_type(Vector_t N);
// 差的绝对值操作
Result_t vabd<q>_type(Vector1_t N, Vector2_t M);
// L(Long)类型, 差的绝对值
Result_t vabdl_type(Vector1_t N, Vector2_t M);
// 差的绝对值,并和另一个向量相加
Result_t vaba<q>_type(Vector1_t N, Vector2_t M, Vector3_t P);
// L(Long)类型, 差的绝对值,并和另一个向量相加, 输出是输入长度的两倍
Result_t vabal_type(Vector1_t N, Vector2_t M, Vector3_t P);
- 取反操作
// 基本的取反操作
Result_t vneg<q>_type(Vector_t N);
// Q(Saturated)类型,带饱和的取反操作
Result_t vqneg<q>_type(Vector_t N);
- 按位统计 0 或 1 的个数
// 统计每个通道 1 的个数
Result_t vcnt<q>_type(Vector_t N);
// 从符号位开始,统计每个通道中与符号位相同的位的个数,且这些位必须是连续的
Result_t vcls<q>_type(Vector_t N);
// 从符号位开始,统计每个通道连续0的个数
Result_t vclz<q>_type(Vector_t N);
- 倒数和平方根求倒计算
// 对每个通道近似求倒
Result_t vrecpe<q>_type(Vector_t N);
// 对每个通道使用 newton-raphson 求倒
Result_t vrecps<q>_type(Vector1_t N, Vector2_t M);
// 对每个通道平方根近似求倒
Result_t vrsqrte<q>_type(Vector_t N);
// 对每个通道使用 newton-raphson 平方根近似求倒
Result_t vrsqrts<q>_type(Vector1_t N, Vector2_t M);
- 向量赋值
// N(Narrow) 类型的赋值,取输入每个通道的高半部分,赋给目的向量
Result_t vmovn_type(Vector_t N);
// L(long) 类型的赋值,使用符号拓展或者 0 拓展的方式,将输入通道的数据赋给输出向量
Result_t vmovl_type(Vector_t N);
// QN(Saturated, Narrow) 类型的赋值,饱和的方式赋值,输出是输入宽度的两倍
Result_t vqmovn_type(Vector_t N);
// QN(Saturated, Narrow) 类型的赋值,饱和的方式赋值,输出是输入宽度的两倍,而且输入为有符号数据,输出无符号
Result_t vqmovun_type(Vector_t N);
Type conversion
- 元素类型的重新解释
Result_t vreinterpret<q>_DSTtype_SRCtype(Vector1_t N);
- 两个 64bit 向量组合成一个 128bit 向量
Result_t vcombine_type(Vector1_t N, Vector2_t M);
- 提取 128bit 向量的高半部分或则低半部分
Result_t vget_high_type(Vector_t N);
Result_t vget_low_type(Vector_t N);
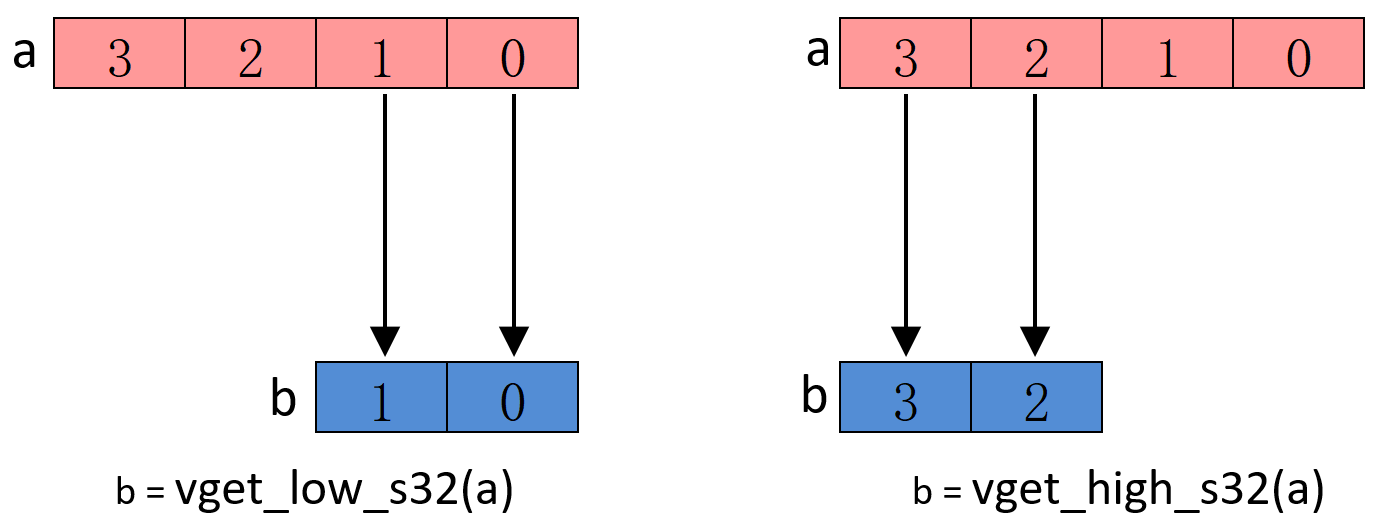
vget_low_s32 \ vget_high_s32 intrinsics 指令操作
NEON intrisics 指令在x86平台的仿真
为了便于 NEON 指令从 ARM 平台移植到 x86 平台使用,Intel 提供了一套转化接口 NEON2SSE,用于将 NEON 内联函数转化为 Intel SIMD(SSE) 内联函数。大部分 x86 平台 C/C++编译器均支持 SSE,因此只需下载并包含接口头文件NEON_2_SSE.h,即可在x86平台调试 NEON 指令代码。
#ifdef ARM_PLATFORM
# include <arm_neon.h>
#else
# include "NEON_2_SSE.h"
#endif
NEON2SSE 提供了 1700 多个 NEON 内联函数的转换接口,运算结果确保与 ARM 平台准确一致。
性能方面:
- 对于使用 128 位向量运算的 NEON 操作,NEON2SSE 在 x86 平台能得到与 ARM 类似的加速比;
- 如果使用 64 位向量做 NEON 运算,x86 平台的加速比将低于 ARM 平台。
参考
ARM技术杂谈:何谓FPU、VFP、ASE、NEON、MPE、SVE、SME以及MVE
NEON
Armv8上不弃不离的NEON/FPU
ARM FPU 加速浮点计算介绍
ARM Cortex-A Series Programmer’s Guide for ARMv7-A
ARM Cortex-M7 Processor Technical Reference Manual r0p2:About the FPU
IEEE 754浮点数标准详解
arm浮点运算
CPU 优化技术-NEON 指令介绍 - 知乎
ARM Neon Programmer's Guide
ARM NEON programming quick reference
ARM Architecture Reference Manual Armv8, for A-profile architecture
Intrinsics – Arm Developer