1 并发与竞态
1.1 竞态概念
1. 并发(Concurrency)是指多个执行单元在同一时间段内执行(但并不一定在同一时刻),而并发的执行单元对共享资源(包括硬件资源和软件资源)的访问就会导致竞态(Race Conditions)
2. 此处的执行单元可以是进程、线程或中断处理程序(其中又分为中断顶半部和中断底半部)
3. Linux内核提供了一系列并发控制机制用于确保在并发环境下能安全地访问共享资源
说明1:由于是分析Linux设备驱动中的互斥与同步,因此本文的讨论范围局限于内核态
说明2:访问共享资源的代码区域称为临界区(Critical Sections),各种并发控制机制保护的就是临界区
1.2 竞态场景
所谓竞态场景就是上文所述的多种执行单元在访问共享资源时的并发场景
1.2.1 对称多处理器SMP
1. SMP(Symmetric Multi-Processor,对称多处理器)是一种紧耦合、共享存储的系统模型,他的特点是多个CPU使用共同的系统总线,因此可以访问共同的外设和存储器

2. 在SMP场景中,不同CPU的进程和中断处理程序之间访问共享资源时构成竞态

3. SMP导致的竞态属于核间竞态
1.2.2 内核抢占调度
1. Linux 2.6之后的内核支持内核抢占调度(用户态抢占调度则是始终支持的),即一个进程在内核态执行时可能因时间片耗尽或者有更高优先级的进程要执行而被打断
2. 进程与抢占他的进程访问共享资源时构成竞态
3. 内核抢占调度导致的竞态属于核内进程间竞态
说明1:早期的Linux内核不支持内核态抢占调度,以Linux 0.11内核为例,如果进程在内核态执行时耗尽时间片,内核并不会触发调度,而是会让进程在内核态继续运行,直到进程返回用户态或主动放弃CPU

说明2:对于支持内核抢占的内核,在编译时需要打开CONFIG_PREEMPT配置宏才能使能内核抢占功能
1.2.3 中断机制
1. 中断可以打断正在执行的进程,如果中断服务程序和被打断的进程访问共享资源,则构成竞态
2. 中断机制导致的竞态属于核内进程与中断间竞态
说明1:在SMP环境中,考虑到内核抢占与中断,可能构成竞态的完整场景如下图所示。针对不同的竞态对象,需要选择合适的并发控制机制进行处理

说明2:上述竞态场景中,只有SMP场景是真正的并行,其他都是在单CPU上的"宏观并行,微观串行"(但是他们引发的问题与SMP类似)
说明3:关于中断嵌套
① 中断嵌套是指中断处理函数被新的更高优先级的中断打断,如果新的中断处理函数和被打断的中断处理函数访问共享资源,则构成竞态
② 在Linux 2.6.35之前的内核版本中软件层面支持中断嵌套,在申请中断时可以设置IRQF_DISABLED标志以避免中断嵌套
③ 从Linux 2.6.36开始内核默认不支持中断嵌套,因此IRQF_DISABLED标志变得无效,从而被移除。相关内容可参考[PATCH v2] Remove deprecated IRQF_DISABLED flag entirely
1.3 互斥与同步的区别
1. 互斥关注的是资源的独占访问,目的是确保在任何时刻只有一个执行单元可以访问共享资源,互斥原语包括自旋锁(spinlock)和互斥锁(mutex)等
2. 同步关注的是执行单元之间的执行顺序,目的是在执行单元之间建立先后关系,同步原语包括信号量(semaphore)和完成量(completion)等
说明:本文对Linux内核提供的互斥机制和同步机制进行了区分,互斥机制侧重于对临界区的保护,而同步机制侧重于协调不同执行单元的执行顺序
2 Linux内核中的上下文判断
后续互斥与同步机制的实现分析与适用性讨论中会涉及Linux内核中的上下文判断,因此单列章节进行说明
2.1 上下文与preempt_count字段
1. Linux内核中的上下文表示程序执行的环境,在特定的环境下只能做特定的事,或者不允许做某些事。一个典型的例子,就是在中断上下文中不允许睡眠
2. 在Linux内核中,上下文的设置与判断通过进程中的preempt_count字段实现,该字段定义在thread_info结构体中

3. Linux内核在preempt_count字段中打包了禁止内核抢占计数、软中断处理中标志、禁止软中断计数、硬中断嵌套计数(硬中断处理中标志)、NMI中断处理中标志和需要重新调度标志。内核通过设置与判断preempt_count字段中的不同位域,来设置与判断当前的上下文类型
2.2 preempt_count字段布局
Linux 5.4.70内核中的preempt_count字段布局如下图所示,
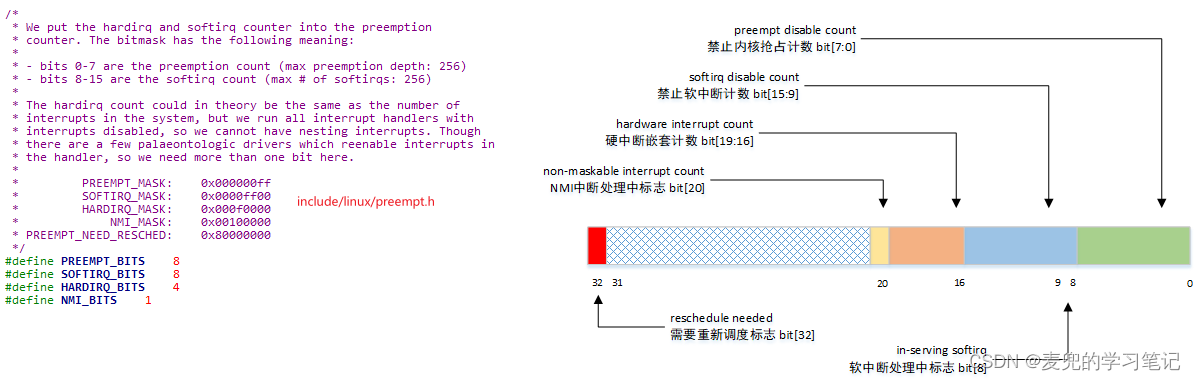
说明1:preempt_count字段各位域起始比特位宏定义
通过preempt_count字段各位域长度宏定义,可以计算得到各位域起始比特位

说明2:preempt_count字段各位域掩码宏定义
通过preempt_count字段各位域长度和起始比特位宏定义,可以计算得到各位域掩码
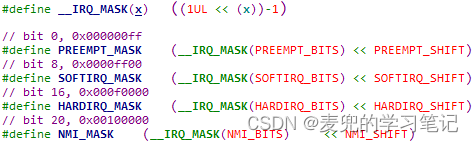
说明3:preempt_count字段各位域偏移量宏定义
通过preempt_count字段各位域的起始比特位宏定义,可以计算得到各位域偏移量,该偏移量后续用于在位域上进行计算

说明4:关于preempt_count字段的基本操作
① 获取preempt_count字段

② 在preempt_count字段的位域中进行累加操作
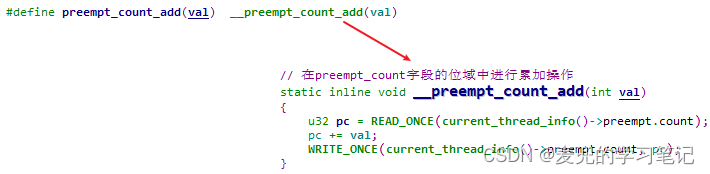
③ 在preempt_count字段的位域中进行递减操作

说明5:在ARM64体系结构中,preempt_count字段通过preempt结构体实现,其中count字段在低32位,need_resched字段在高32位。因此PREEMPT_NEED_RESCHED宏是将1左移32位,从而设置到need_resched字段

2.3 preempt_count字段操作
2.3.1 禁止内核抢占计数操作
1. preempt_disable函数会将禁止内核抢占计数加1,从而禁止内核抢占

2. preempt_enable函数会将禁止内核抢占计数减1,如果计数变为0,则开启内核抢占。如果当前满足内核抢占条件,还会触发调度

需要注意的是,根据__preempt_count_dec_and_test函数的判断标准,只有当preempt_count字段整体为0,也就是除了禁止内核抢占计数为0,还需要软中断处理中标志 / 禁止软中断计数 / 硬中断嵌套计数 / NMI中断处理中标志 / 需要重新调度标志均为0时,才会触发调度
3. preempt_enbale_no_resched函数会将禁止内核抢占计数减1,如果计数变为0,则开启内核抢占,但是该函数不会触发调度

说明:barrier编译器屏障(compiler barrier)的作用
① barrier编译器屏障的作用是防止编译器优化导致指令重排序,在某些情况下,这种重排序可能导致错误的程序行为
② 在preempt_disable函数禁止内核抢占的场景中,preempt_disable函数之后的代码不应该在禁止内核抢占之前执行。为了达到该目的,需要在preempt_disable函数的最后插入编译器屏障
③ 在preempt_enable/enable_no_resched函数开启内核抢占的场景中,preempt_enable/enable_no_resched函数之前的代码不应该在开启内核抢占之后执行。为了达到该目的,需要在preempt_enable/enable_no_resched函数的最前面插入编译器屏障
2.3.2 软中断处理中标志操作
1. 因为软中断在单个CPU上不会嵌套执行,所以对于preempt_count字段中软中断相关的bits [15:8]位域,
① 使用bit [8]标记当前是否处于软中断上下文
② 使用bits [15:9]记录禁止软中断计数
2. 内核在处理软中断的过程前后,会设置和清除软中断处理中标志

3. 可以通过in_serving_softirq宏判断当前是否正在处理软中断

2.3.3 禁止软中断计数操作
1. 可以通过local_bh_disable函数增加禁止软中断计数,通过local_bh_enable函数减少禁止软中断计数。从函数名看,这2个函数用于禁止和使能本地CPU的底半部运行,可见此处的底半部是指软中断(或基于软中断实现的,e.g. tasklet机制)这类运行在中断上下文中的底半部

2. 如果禁止软中断计数不为0,则在退出中断处理的过程中不会处理软中断

说明:__local_bh_enable_ip函数在当前满足内核抢占条件时会触发调度

2.3.4 硬中断嵌套计数操作
1. 早期的Linux内核支持硬中断嵌套,但是目前的内核版本已不再支持内核嵌套,因此硬中断嵌套计数中实际只使用一位,用于标记当前是否处于硬中断上下文
2. 内核在处理硬中断的过程前后,会增加和减少硬中断嵌套计数

2.3.5 NMI中断处理中标志操作
1. NMI中断处理中表示用于标记当前是否处于NMI中断上下文,内核在处理NMI中断的过程前后会设置和清除NMI中断处理中标志

2. 在Linux 5.8之前的内核版本中,不支持NMI中断嵌套,所以NMI_BITS宏值为1。从Linux 5.8版本开始,内核支持NMI中断嵌套,因此将NMI_BITS宏值修改为4,相关内容可参考[PATCH v3 01/22] hardirq/nmi: Allow nested nmi_enter() - Peter Zijlstra
说明:ARMv9.2之前的ARM64体系结构不支持NMI中断,但是可以配置CONFIG_ARM64_PSEUDO_NMI条件编译宏,此时内核会使用GICv3的高优先级中断模拟NMI,相关内容可参考Linux内核性能剖析的方法学和主要工具_linux arm64 nmi实现
2.3.6 需要重新调度标志操作
1. 在ARM64体系结构中,是将need_resched字段设置为0时表示当前进程需要重新调度

2. 中断返回过程中的内核抢占操作
可见中断返回过程中的内核抢占操作标准,与__preempt_count_dec_and_test函数是相同的,都是要求preempt_count字段整体为0。从el1_irq函数的实现可见,如果当前禁止内核抢占计数不为0,在中断返回过程中就不会触发内核抢占,从而确保中断返回后仍继续执行禁止内核抢占的进程

说明:set_preempt_need_resched函数与set_tsk_need_resched函数辨析
内核中2组设置需要重新调度标志的函数,如下图所示,

① 从设置标志的角度
- set_preempt_need_resched函数是设置thread_info结构体中的need_resched字段

- set_tsk_need_resched函数是设置thread_info结构体中的flags字段

② 从操作对象的角度
- set_preempt_need_resched函数没有参数,只能设置当前进程
set_tsk_need_resched函数参数为指向task_struct结构体的指针,因此可以设置指定进程
2.4 通过preempt_count字段判断上下文类型
内核中提供了一系列宏定义,用于判断当前的上下文类型,

2.5 原子上下文
1. 内核中提供了in_atomic宏用于判断当前是否处于原子上下文,判断的标准就是thread_info结构体中的preempt.count字段不为0,也就是只要存在禁止内核抢占 / 软中断处理中 / 禁止软中断 / 硬中断处理中 / NMI中断处理中的任何一种情况,都属于原子上下文

2. 根据内核注释,通过in_atomic宏判断当前是否处于原子上下文是有风险的。主要是在不支持内核抢占的内核版本中,自旋锁上锁操作不会增加禁止内核抢占计数,此时虽然属于原子上下文,但是无法正确体现在preempt_count字段中
3. 在原子上下文中不应进行可能导致睡眠的操作,内核中提供了might_sleep函数,帮助检查在当前上下文中是否允许睡眠。该函数可以帮助捕获潜在的错误,以确保不会在不允许睡眠的上下文中调用可能导致睡眠的函数,这有助于防止内核死锁或其他不稳定行为
可见如果preempt.count字段不为0,或者中断被关闭,都属于原子上下文,不能进行可能导致睡眠的操作

3 互斥机制
3.1 禁止内核抢占
3.1.1 实现原理
1. 如上文所述,在支持内核抢占的内核版本中,通过禁止内核抢占计数来标识当前是否可抢占
① 如果禁止内核抢占计数为0,则可以抢占
② 如果禁止内核抢占计数大于0,则不可抢占
2. 内核在各抢占调度点会检查禁止内核抢占计数,从而判断当前是否可抢占。只有在可抢占时,内核才会触发任务调度,选择一个新的任务来运行。以preempt_schedule函数为例,只有当preempt_count字段为0且没有关闭中断时才会触发调度,否则直接返回

3.1.2 操作API
| 操作API | 功能 |
| preempt_disable() | 将禁止内核抢占计数加1,从而禁止内核抢占 |
| preempt_enable() | 将禁止内核抢占计数减1,如果计数变为0,则开启内核抢占。如果当前满足内核抢占条件,还会触发调度 |
| preempt_enable_no_resched() | 将禁止内核抢占计数减1,如果计数变为0,则开启内核抢占,但是该函数不会触发调度 |
3.1.3 原子性讨论
说明:内核互斥与同步机制的原子性讨论包含2个方面,
① 该机制是否可以在原子上下文中使用
② 该机制构成的临界区是否是原子上下文
1. 禁止内核抢占不会导致睡眠,而且可以嵌套禁止内核抢占(因为禁止内核抢占通过累加计数的方式实现),因此可以在原子上下文中使用
2. 通过禁止内核抢占构成的临界区属于原子上下文,因此不能在其中进行可能导致睡眠的操作
说明:临界区原子性实验验证
① 以Linux设备驱动基础03:Linux字符设备驱动中实现的字符设备驱动为基础进行验证,在open回调函数中增加禁止内核抢占操作,并且在临界区内调用schedule函数触发调度
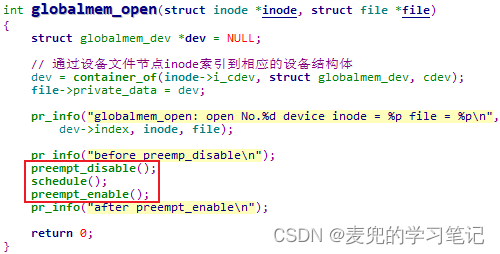
② 经过验证,在schedule函数中会检测出在原子上下文中触发调度的错误

其中schedule函数报错流程如下图所示,

3.1.4 生效场景
1. 可以处理核内进程间竞态
禁止内核抢占可以禁止CPU上当前正在内核态执行的进程被其他经常抢占,因此可以处理核内进程间竞态
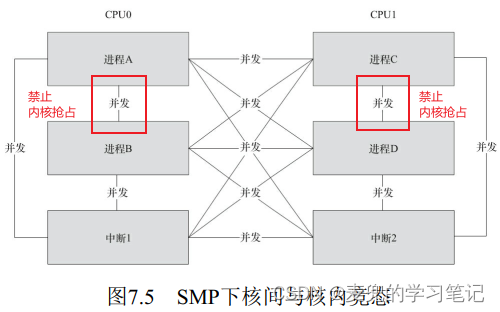
2. 无法处理核间竞态和核内进程与中断间竞态
① 在SMP场景下,禁止内核抢占仅作用于当前CPU,而不是整个系统,因此无法处理核间竞态
② 禁止内核抢占并没有屏蔽本地中断,因此也无法处理核内进程与中断间竞态
说明1:核内进程间竞态实例
per-CPU变量仅能被所属CPU上的执行单元访问,如果某个per-CPU变量仅被所属CPU上的进程访问,则可以使用禁止内核抢占的方式保护
说明2:如果禁止内核抢占的进程长期占用CPU,该CPU上的其他进程将无法及时得到调度,因此通过禁止内核抢占保护的临界区应该尽可能短暂
3.2 屏蔽本地中断
3.2.1 实现原理
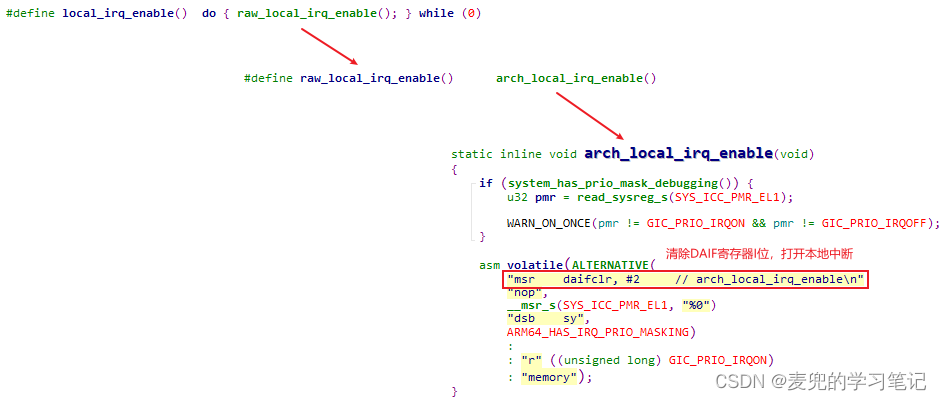
CPU一般都具备屏蔽中断和打开中断的功能,具体操作与体系结构相关。在ARM64体系结构中,通过操作DAIF寄存器中的I位,可以屏蔽和打开中断

3.2.2 操作API
| 操作API | 功能 |
| local_irq_disable() | 屏蔽本地中断 |
| local_irq_enable() | 打开本地中断 |
| local_irq_save(flags) | 保存当前DAIF寄存器状态,并屏蔽本地中断 |
| local_irq_restore(flags) | 使用flags的值恢复DAIF寄存器状态 |
| irqs_disabled() | 判断当前本地中断是否已屏蔽 |
说明1:local_irq_disable函数分析

说明2:local_irq_enable函数分析
说明3:local_irq_save函数分析

说明4:local_irq_restore函数分析

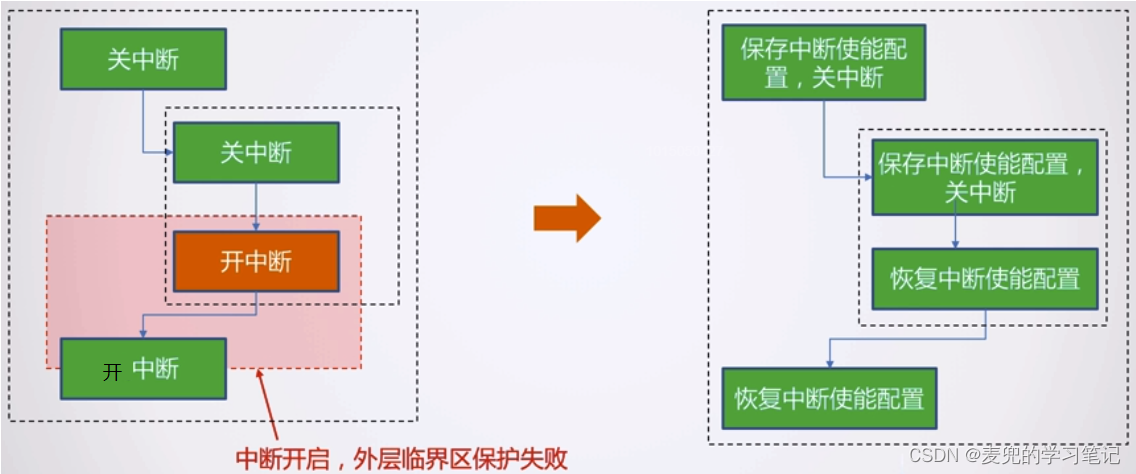
说明5:通过local_irq_save和local_irq_restore函数可以实现嵌套关中断,要点就是local_irq_restore函数是使用匹配的local_irq_save函数保存的状态恢复DAIF寄存器
说明6:irqs_disabled函数分析

说明7:禁止中断底半部
如上文所述,还可以单独禁止中断底半部,相关操作API如下,
| 操作API | 功能 |
| local_bh_disable() | 将禁止软中断计数加1,从而禁止基于软中断实现的中断底半部 |
| local_bh_enable() | 将禁止软中断计数减1,如果计数变为0,则开启中断底半部 如果当前满足处理软中断的条件,会处理软中断 如果当前满足内核抢占条件,还会触发调度 |
3.2.3 原子性讨论
1. 屏蔽本地中断不会导致睡眠,而且有支持嵌套关中断的形式,因此可以在原子上下文中使用
2. 通过屏蔽本地中断构成的临界区属于原子上下文,因此不能在其中进行可能导致睡眠的操作
说明:验证在屏蔽本地中断的情况下调用schedule函数
① 产生该验证想法是因为在in_atomic宏的判断条件中并不包括屏蔽本地中断的情况,而might_sleep函数的判断标准中包括了屏蔽本地中断的情况。也就是说,在屏蔽本地中断的情况下,根据in_atomic宏判断不属于原子上下文(这里还需要thread_info.preempt.count字段为0);但是根据might_sleep函数的判断标准,不能进行可能导致睡眠的操作
② 经过验证,由于schedule函数本身不检查中断是否关闭,因此在调用local_irq_disable函数屏蔽本地中断后仍可以调用schedule函数,而且实验所用的驱动程序"貌似"可以工作
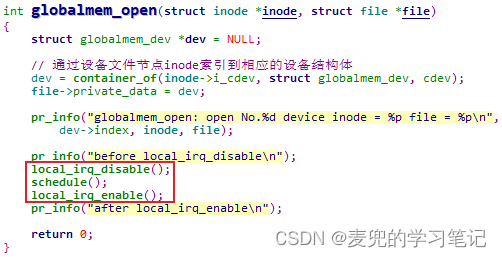

③ 为了进一步验证上述现象,在屏蔽和使能本地中断的操作前后打印当前中断屏蔽状态。可见当再次切换回globalmem_open函数所在进程执行时,本地中断已经被打开

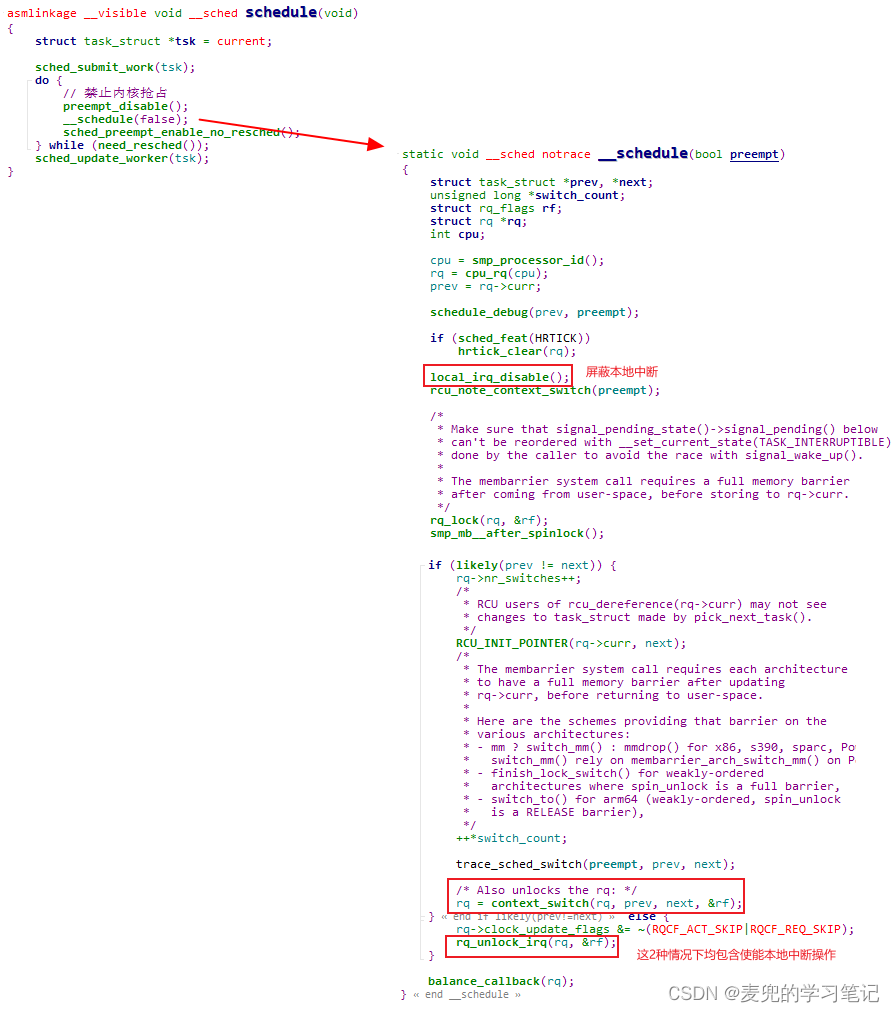
④ 之所以在屏蔽本地中断并调用schedule函数之后中断会被打开,是因为在schedule函数中有屏蔽和使能本地中断的操作,而且使用的是非嵌套版本,这就是实验驱动程序在屏蔽本地中断的情况下可以调用schedule函数并且没有导致系统崩溃的原因
但是从语义上说,schedule函数返回后的中断屏蔽状态已经被修改,并不是驱动程序期望的屏蔽状态,因此不应在屏蔽本地中断的情况下进程可能导致睡眠的操作
3.2.4 生效场景
1. 可以处理核内进程与中断间竞态
屏蔽本地中断后,本地CPU不再响应中断,也就不会运行中断处理函数,因此可以处理核内进程与中断间竞态

2. 无法处理核间竞态和核内进程间竞态
① 在SMP场景下,屏蔽本地中断仅作用于当前CPU,而不是整个系统,因此无法处理核间竞态
② 屏蔽本地中断会导致部分内核抢占点不被执行(e.g. 中断返回过程中的内核抢占点),但是无法禁止所有内核抢占点,所以也无法处理核内进程间竞态
说明1:核内进程与中断间竞态的2个对象并不是对等的,中断本身是可以打断进程的。所以一般都是在进程中屏蔽本地中断,从而确保进程在内核中的执行路径不被中断处理程序打断
对于中断处理程序而言,中断顶半部本身就是在关中断的环境中运行,所以无需屏蔽本地中断;而中断底半部是在开中断的环境中运行,但是中断底半部可能运行在中断上下文(e.g. 软中断softirq)也可能运行在进程上下文(e.g. 工作队列workqueue),此时需要根据根据实际情况决定是否需要屏蔽本地中断,详解后文自旋锁章节的讨论
说明2:屏蔽本地中断并不是安全的禁止内核抢占的方法
如上文所述,屏蔽本地中断虽然会影响部分内核抢占点,但是无法禁止所有内核抢占点。在屏蔽本地中断的情况下,只要执行路径中调用到cond_resched函数,则依然会触发内核抢占,详情可参考如下链接
Why is irqs_disabled() an unsafe way of disabling preemption?
Why disabling interrupts disables kernel preemption and how spin lock disables preemption
说明3:中断对于内核的运行非常重要(e.g. 进程调度就依赖于中断),在屏蔽中断期间所有中断都无法得到处理。如果长时间屏蔽中断,可能造成数据丢失乃至系统崩溃等后果,因此通过屏蔽本地中断保护的临界区也应该尽可能短暂
3.3 原子操作
3.3.1 实现原理
原子操作依靠体系结构的原子操作指令实现,在ARM64体系结构中有2种实现机制,
1. Load/Store Exclusive机制
这是ARMv8体系结构支持的基础原子内存访问机制,该机制通过ldxr和stxr指令对实现原子操作。ldxr和stxr指令配对使用,可以让总线监控ldxr和stxr指令之间有无其他执行单元存取该地址。如果有其他并发访问,则执行stxr指令时第1个寄存器的值会被设置为1,并且存储的行为也会失败。当独占访问失败时,可以通过条件跳转指令重新尝试

2. LSE(Large System Extension)机制
① LSE机制是ARMv8.1引入的一组新的原子操作指令,用于提高大型系统(e.g. 多核处理器和多处理器系统)中的同步和并发性能。相较于传统的Load/Store Exclusive指令,LSE指令在高争用场景中有更好的性能表现
② LSE指令集包括原子交换(SWAP)、原子比较交换(CAS)、原子加载和操作(LDADD)和原子存储和操作(STADD)等,这些指令可以用于实现各种高效的原子操作和同步原语

3.3.2 操作API
3.3.2.1 int型原子操作
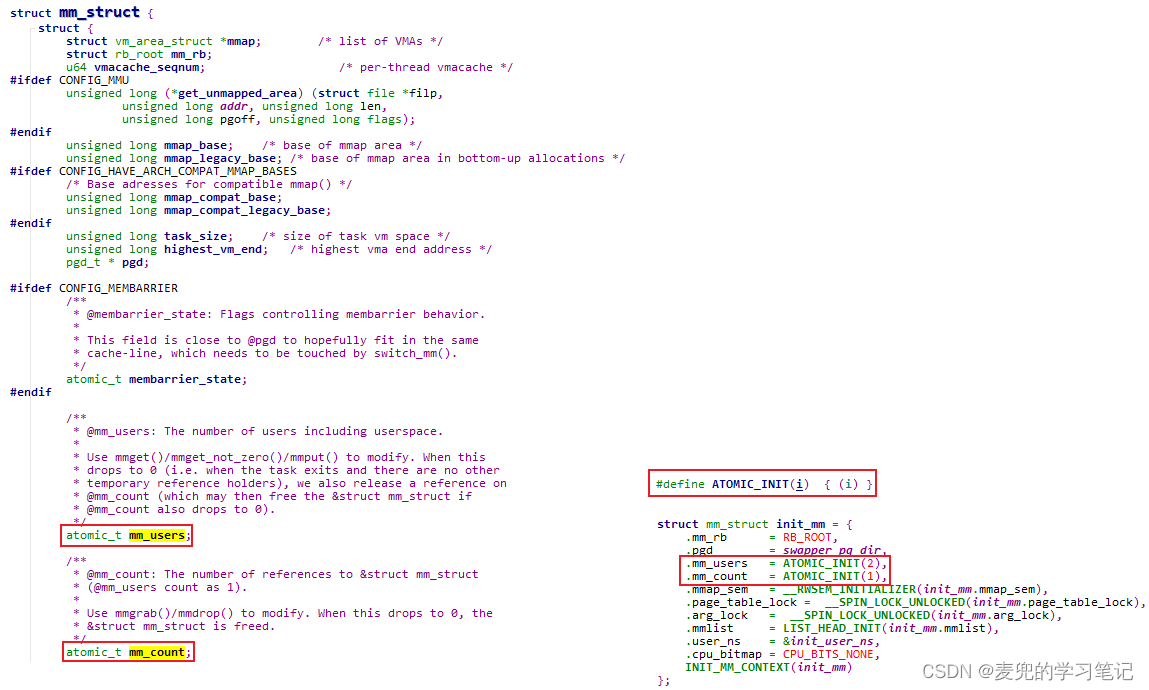
1. int型原子操作数据类型如下,
![]()
2. int型原子操作API如下,
| 操作API | 功能 |
| atomic_read(const atomic_t *v) | 读取原子变量的值,即原子地读取v->counter |
| atomic_set(atomic_t *v, int i) | 设置原子变量的值,即原子地设置v->count = i |
| atomic_inc(atomic_t *v) | 将原子变量的值加1,即原子地v->counter++ 相应的atomic_inc_return函数还会返回原子变量加1后的值 |
| atomic_dec(atomic_t *v) | 将原子变量的值减1,即原子地v->counter-- 相应的atomic_dec_return函数还会返回原子变量减1后的值 |
| atomic_add(int i, atomic_t *v) | 将原子变量的值加i,即原子地v->counter += i 相应的atomic_add_return函数还会返回原子变量加i后的值 |
| atomic_sub(int i, atomic_t *v) | 将原子变量的值减i,即原子地v->counter -= i 相应的atomic_sub_returen函数还会返回原子变量减i后的值 |
| atomic_inc_and_test(atomic_t *v) | 先将原子变量的值加1,再判断新值是否为0,如果新值为0,则返回1 |
| atomic_dec_and_test(atomic_t *v) | 先将原子变量的值减1,再判断新值是否为0,如果新值为0,则返回1 |
说明:可以通过ATOMIC_INIT宏设置int型原子变量的初始值
3.3.2.2 long型原子操作
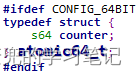
1. long型原子操作数据类型如下,可见与int型原子操作相比数据长度从4B扩展为8B
2. long型原子操作API如下,可见与int型原子操作基本相同
| 操作API | 功能 |
| atomic64_read(const atomic64_t *v) | 读取原子变量的值,即原子地读取v->counter |
| atomic64_set(atomic_t *v, int i) | 设置原子变量的值,即原子地设置v->count = i |
| atomic64_inc(atomic_t *v) | 将原子变量的值加1,即原子地v->counter++ 相应的atomic64_inc_return函数还会返回原子变量加1后的值 |
| atomic64_dec(atomic_t *v) | 将原子变量的值减1,即原子地v->counter-- 相应的atomic64_dec_return函数还会返回原子变量减1后的值 |
| atomic64_add(int i, atomic_t *v) | 将原子变量的值加i,即原子地v->counter += i 相应的atomic64_add_return函数还会返回原子变量加i后的值 |
| atomic64_sub(int i, atomic_t *v) | 将原子变量的值减i,即原子地v->counter -= i 相应的atomic64_sub_returen函数还会返回原子变量减i后的值 |
| atomic64_inc_and_test(atomic_t *v) | 先将原子变量的值加1,再判断新值是否为0,如果新值为0,则返回1 |
| atomic64_dec_and_test(atomic_t *v) | 先将原子变量的值减1,再判断新值是否为0,如果新值为0,则返回1 |
说明1:可以通过ATOMIC64_INIT宏设置long型原子变量的初始值,可见在ARM64体系结构体中ATOMIC64_INIT宏与ATOMIC_INIT宏相同
![]()
说明2:int型原子操作和long型原子操作均通过体系结构的原子操作指令实现,差别主要在于操作的数据长度

3.3.2.3 bit型原子操作
bit型原子操作没有定义特殊的数据类型,而是直接操作整型数据中的位,相关操作API如下,
| 操作API | 功能 |
| void set_bit(unsigned int nr, volatile unsigned long *p) | 将(*p)的bit[nr]置为1 |
| void clear_bit(unsigned int nr, volatile unsigned long *p) | 将(*p)的bit[nr]置为0 |
| void change_bit(unsigned int nr, volatile unsigned long *p) | 翻转(*p)中bit[nr]的值 |
| bool test_bit(unsigned int nr, const volatile unsigned long *p) | 测试(*p)的bit[nr]是否置位 |
| int test_and_set_bit(unsigned int nr, volatile unsigned long *p) | 将(*p)的bit[nr]置为1,并且返回该位的旧值 |
| int test_and_clear_bit(unsigned int nr, volatile unsigned long *p) | 将(*p)的bit[nr]置为0,并且返回该位的旧值 |
| int test_and_change_bit(unsigned int nr, volatile unsigned long *p) | 翻转(*p)中bit[nr]的值,并且返回该位的旧值 |
说明1:bit型原子操作基于整型原子操作实现,以set_bit函数为例,

说明2:虽然Linux内核中的bitmap系列函数(以bitmap_开头,e.g. bitmap_and,定义在include/linux/bitmap.h文件)也可以进行位操作,但是他们不是原子的,相关内容可参考Atomic bitops — The Linux Kernel documentation
说明3:根据Atomic bitops — The Linux Kernel documentation,内核中以__开头的位操作也不是原子的(e.g. __set_bit)

3.3.3 原子性讨论
1. 原子操作不会导致睡眠,因此可以在原子上下文中使用
2. 原子操作构成的临界区局限于一个原子操作的范围,没有上下文的概念
3.3.4 生效场景
原子操作可以确保对一个整型数据的修改是排他性的,通过将临界区局限在一个原子操作的范围,就可以处理核间竞态、核内进程间竞态和核内进程与中断间竞态
3.4 自旋锁
3.4.1 实现原理
1. 自旋锁基于原子操作指令实现,具体的实现方式则经历了原始自旋锁、ticket自旋锁、MCS自旋锁和队列自旋锁的阶段
2. 本节通过原始自旋锁来说明自旋锁的实现原理,以Linux 2.6.35内核基于ARMv7体系结构的实现为例
① 自旋锁数据类型如下,可见其本质上是一个整型变量。自旋锁就是通过对该变量的标记,来确定当前执行单元是否成功持有锁,而这个标记的过程必须是原子的,这就需要依靠体系结构提供的原子操作指令

② 自旋锁初始化后,数据类型中的整型变量值为0,即表示unlock状态

③ spin_lock函数上锁操作流程如下,可见核心是依靠ldrex和strex原子操作指令

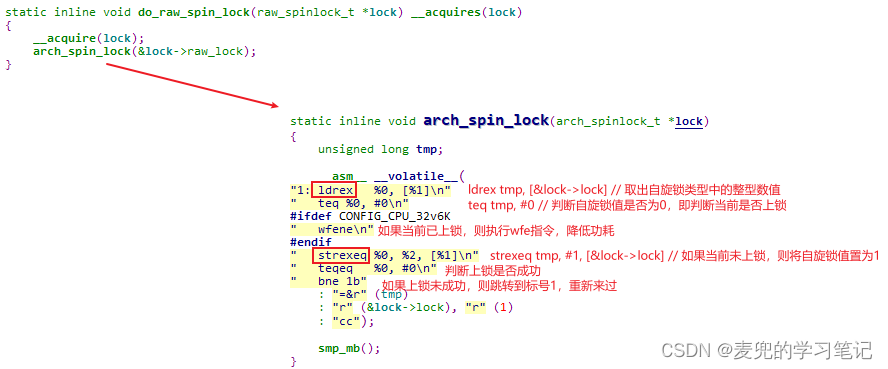
说明1:arch_spin_lock函数中当上锁未成功时的重试操作,就是自旋锁名称的由来。也就是说自旋锁是一种忙等锁,执行单元在等待获取自旋锁的过程中会一直循环操作等待
如果配置使能执行wfe指令,则CPU可以进入low power模式而不是循环操作等待,但是也仍然不会放弃CPU
说明2:从spin_lock函数的实现分析可见,自旋锁和原子变量的实现方式是相同的,都是基于原子操作指令

说明3:为什么spin_lock函数在实际的上锁操作之前需要禁止内核抢占?
① 对于SMP系统,spin_lock函数禁止内核抢占是为了避免死锁
spin_lock函数的上锁操作本身可以处理核间竞态,但是如果不禁止本地CPU的内核抢占,则当前持有锁的执行单元可能被抢占。如果抢占的执行单元也要获取相同的自旋锁,则会导致死锁
② 对于单核CPU(也称作UP系统,Uni-Processor)且运行支持内核抢占的Linux内核,spin_lock函数的实现就是禁止内核抢占。仍以Linux 2.6.35内核基于ARMv7体系结构的实现为例,spin_lock函数实现如下,

③ 对于单核CPU且运行不支持内核抢占的Linux内核,spin_lock函数的实现退化为空操作(本质上是此时preempt_disable函数实现为空操作)
![]()
说明4:如果持有自旋锁的执行单元可以被中断打断,且中断处理函数也要获取相同的自旋锁,则也可能导致死锁,此时在执行单元中需要使用spin_lock_irq函数同时屏蔽本地中断
需要注意的是,此处的被中断打断,是指被执行单元所在CPU的中断打断。如果中断处理函数在SMP系统的其他CPU上执行,互斥锁上锁操作本身即可处理;但是如果中断处理函数在本地CPU执行,则可能导致死锁
说明5:原始自旋锁spin_unlock函数分析


① 在设置自旋锁整型值进行解锁操作时使用str指令即可,因为地址和长度对齐(即地址按要操作的数据长度对齐)的str指令操作本身就是原子的
② 解锁过程中的sev指令用于唤醒上锁过程中因wfe指令进入low power状态的CPU
3.4.2 操作API
1. 自旋锁数据类型如下,可见在Linux 5.4.70内核中自旋锁以队列自旋锁的方式实现

2. 自旋锁操作基础API
| 操作API | 功能 |
| spin_lock_init(spinlock_t *lock) | 初始化自旋锁为unlock状态 |
| void spin_lock(spinlock_t *lock) | 获取自旋锁,该函数返回时说明肯定获取了自旋锁 |
| int spin_trylock(spinlock_t *lock) | 尝试获取自旋锁,成功获取返回1,否则返回0 |
| void spin_unlock(spinlock_t *lock) | 释放自旋锁 |
| int spin_is_locked(spinlock_t *lock) | 返回自旋锁状态,已加锁返回1,否则返回0 |
说明:可以通过DEFINE_SPINLOCK宏定义自旋锁且初始状态为unlock

3. 自旋锁操作衍生API
如上文所述,持有自旋锁的执行单元还可能被中断或中断底半部打断,此时需要使用衍生的自旋锁API,在获取自旋锁的同时屏蔽本地中断或禁止中断底半部
| 操作API后缀 | 功能 |
| _bh(spinlock_t *lock) | 加锁时禁止中断底半部,解锁时使能中断底半部 相当于spin_lock + local_bh_disable |
| _irq(spinlock_t *lock) | 加锁时屏蔽本地中断,解锁时使能本地中断 相当于spin_lock + local_irq_disable |
| _irqsave(spinlock_t *lock, flags) _restore(spinlock_t *lock, flags) | 加锁时保存当前DAIF寄存器状态并屏蔽本地中断,解锁时使用flags值恢复DAIF寄存器状态 相当于spin_lock + local_irq_save |
说明:自旋锁API使用原则
根据互斥对象的不同,自旋锁API的使用原则如下表所示。表格中将执行单元分为线程、软中断和硬中断,其中后者可以打断前者,前者不可以打断后者。因此如果互斥对象存在打断关系时,需要在前者中禁用后者才能确保临界区安全且不会发生死锁

3.4.3 原子性讨论
1. 自旋锁不会导致睡眠,因此可以在原子上下文中使用
2. 通过自旋锁构成的临界区属于原子上下文,因此不能在其中进行可能导致睡眠的操作
说明:临界区原子性实验验证
① 在实验驱动程序的open回调函数中增加自旋锁上锁操作,并且在临界区内调用schedule函数触发调度

② 经过验证,在schedule函数中会检测出在原子上下文中触发调度的错误

3.4.4 生效场景
1. 在SMP环境中,自旋锁基于原子操作指令实现,因此可以处理核间竞态
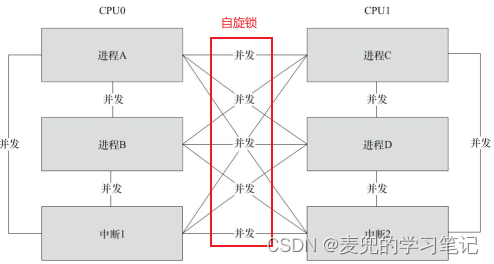
2. 在获取自旋锁的spin_lock函数中,会在真正上锁前调用preempt_disable函数禁用内核抢占,因此还可以处理核内进程间竞态


3. spin_lock函数还有衍生的关中断版本,即spin_lock_irq和spin_lock_irqsave函数。由于是在spin_lock函数的基础上增加了屏蔽本地中断的操作, 因此该版本还可以处理核内进程与中断间竞态
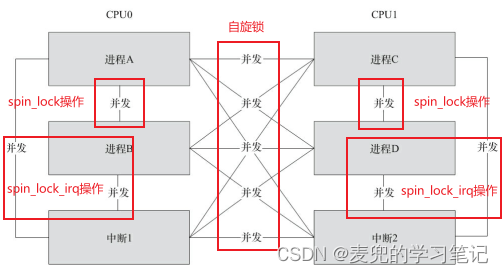
说明:自旋锁是一种忙等锁,在执行单元获取到锁之前不会放弃CPU(无论是循环操作等待还是执行wfe指令进入low power模式),在此期间CPU不会做任何有用的工作,因此通过自旋锁保护的临界区应该尽可能短暂









![[MySQL]表的操作](https://img-blog.csdnimg.cn/img_convert/e35d745297b8b323c689eec319104804.png)