是不是苦于没有ChatGPT的API key或者免费的token而无法愉快地和它玩耍?想不想在有限的计算资源上部署大模型并调戏大模型??想不想解锁大模型的除了对话之外的其它功能???几行代码教你搞定如何在有限的计算资源下部署超大模型并实现推理。
准备
超大语言模型。OPT,GPT,LLaMA都行,只要是开源的都行。去Hugging Face找一款心仪的模型,总有适合你的。我用的LLaMA-30B,你需要从官网上准备好下面这一堆文件:

相应的环境依赖。作为调包侠,基本的pytorch、transformers等等就不用说了,这次介绍本期主角**accelerate**!!!
GPUs。TITAN RTX×4,也就是4×24G的算力。
# 踩坑 不用踩坑!!!因为我都踩好了。
直接开始
首先,简单阐述一下accelerate的实现原理:将模型切分存放,GPU不行放在CPU上,CPU放不下放在内存里。然后用哪一部分加载哪一部分就行。详细看油管的视频介绍。而计算哪部分需要被加载到哪里,需要经过预先的计算。可是不加载模型怎么计算内存并分配?新版本pytorch的init_empty_weights帮你实现。具体原理还是看看别人讲的吧,我主要负责踩坑。
上代码。
from transformers import LlamaTokenizer, AutoConfig, AutoModelForCausalLM
import os
import torch
from accelerate import infer_auto_device_map, init_empty_weights, load_checkpoint_and_dispatch
os.environ["CUDA_VISIBLE_DEVICES"] = '0,1,2,3'
# model_name = 'llama-7b'
model_name = 'llama-30b'
# 首先使用虚拟内存加载模型,这个内存被认为是无限大
# "/{}/".format(model_name)是你自己模型存放的路径,这个不会改的也别来部署大模型了
with init_empty_weights():
model = AutoModelForCausalLM.from_pretrained("/{}/".format(model_name),
trust_remote_code=True, torch_dtype=torch.float16)
# The model weights are not tied.
# Please use the `tie_weights` method before using the `infer_auto_device` function.
model.tie_weights()
# 人为设置不同的device所分配的内存, devide:0分配得少一些方便后续推理,实际操作中不写也行
# max_memory={0: "16GiB", 1: "23GiB", 2: "23GiB", 3:"23GiB", "cpu":"80Gib"} # cpu辛苦你啦
# device_map = infer_auto_device_map(model, max_memory=max_memory) # 自动推断device_map
#
# print(device_map) # 可以看看模型不同层被分在了哪里
model = load_checkpoint_and_dispatch(model, checkpoint="/{}/".format(model_name),
device_map='auto', offload_folder="offload", no_split_module_classes=["LlamaDecoderLayer"],
offload_state_dict=True, dtype=torch.float16).half()
# half()强制数据转化,看名字应该是一个内存优化的数据类型
print("(*^_^*) model load finished!!!! please play with {}".format(model_name))
while True:
text_in = input('please input your question: ')
# 注意,使用Autokenizer会很慢,不知道为什么
tokenizer = LlamaTokenizer.from_pretrained("/{}/".format(model_name))
inputs = tokenizer(text_in, return_tensors="pt").to(0)
outputs = model.generate(inputs["input_ids"], max_new_tokens=20)
text_out = tokenizer.decode(outputs[0].tolist(), skip_special_tokens=True)
print(text_out)
注意事项:
- 在使用LLaMA的时候,千万不要使用Autokenizer,这会导致tokenizer加载速度很慢很慢很慢。
- 加载模型的时候一定注意使用:no_split_module_classes。它表示模型的哪些部分不能被拆分到不同的GPUs上。具体来说,包含残差的部分一定要设置no split!!!
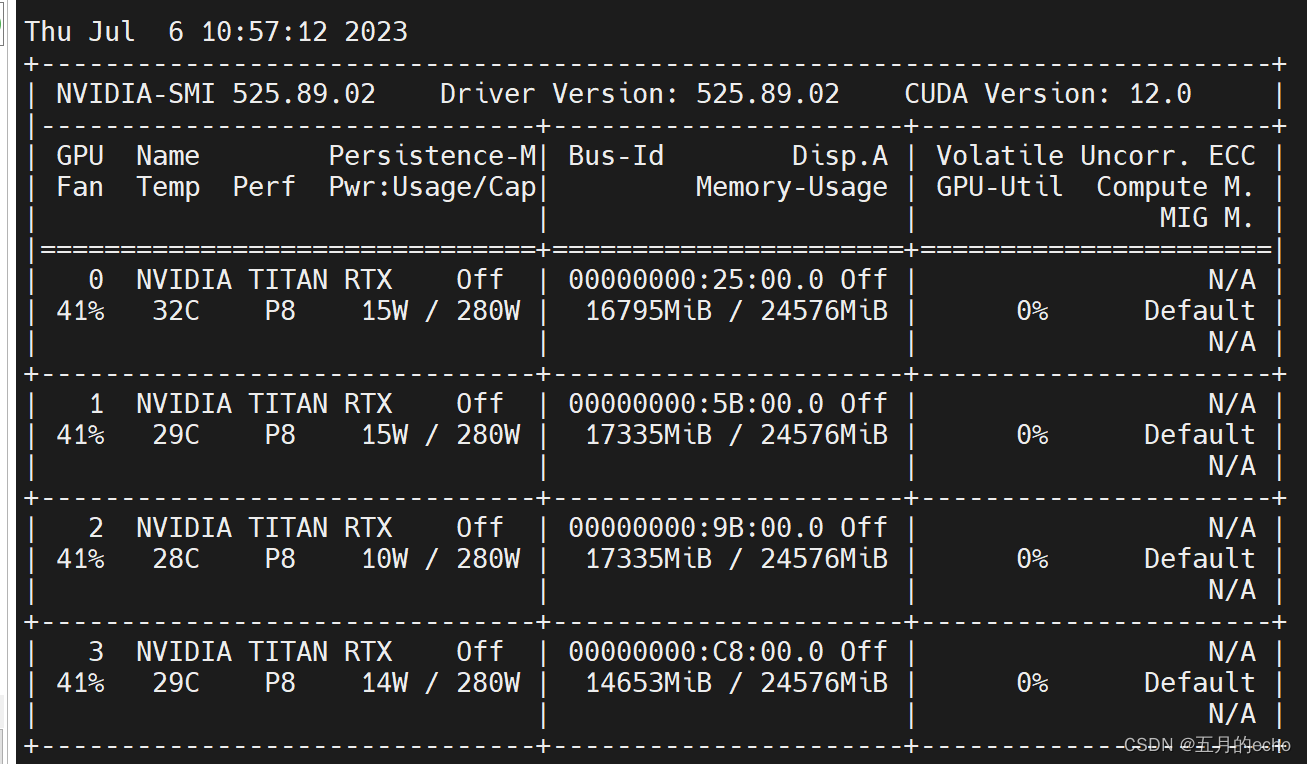
最后,30B的模型占用的显存如下,非常可观: