目录
一是基于通用大模型研发行业大模型的难度。
二是私有数据的安全隐患。
三是落地成本的可控性。
To B 的探索并非现在才开始。自 ChatGPT 开放 API 插件以来,国内的多家云厂商在推出通用大模型时,也往往同步其对行业赋能的意愿。但大模型 To B 探索至今仍没有打破高墙,简单来说有三个维度的阻碍:
一是基于通用大模型研发行业大模型的难度。
从技术上来看,专业领域(如金融、医疗、法律)的行业大模型并非通过将数据喂给通用大模型进行精调就能轻松获得。例如,摩根大通 AI 研究院的一项研究已用实验证明,在金融领域,拥有行业私有数据的 BloombergGPT 在多个任务上的表现并没有比通用大模型更好:

这表明,当前行业大模型的技术瓶颈仍待突破。
过去十年的 AI 商业落地又告诉我们,定制化的项目落地模式难逃劳动密集型的「堆人力」结局,造成商业变现上的高投入、低回报局面,行业内不同企业之间又存在竞争关系,因此大多数人都认为:解决特定领域问题的行业大模型必须建立在通用大模型的基础上,即「基于标准化的定制化」、而非「彻头彻尾的定制化」。
也就是说,行业大模型的研发离不开通用大模型的能力。同时,还要有能为企业提供模型精调与训练的平台、稳定运行模型推理与应用的基础设施等。虽然行业模型的最终落地大概率是本地私有部署,但大多数应用的使用者也是广泛 C 端用户,因此长久稳定、充足可靠的系统资源也至关重要。

二是私有数据的安全隐患。
To B 场景中,大模型的买方与卖方间存在天然的信任障碍。一方面,企业担心自己的数据(如对话数据、内部代码、文档等)在接入公有大模型后泄露,通常要求私有化部署;但这种情况下,另一方面,大模型的提供方又担心技术机密泄漏。
市场上现有第三方公司提供模型微调训练的服务,可以帮助企业在开源模型的基础上训练企业自己所需的行业大模型,然后部署到企业本地的平台上。这类第三方公司不是大模型提供方,没有技术输出的忧虑,收费价格也不高,但企业与其合作仍需要出让自有的数据,且无法保证自家的数据不会被泄露给同行的竞对。
更值得注意的是,当前许多开源的大模型规定,基于其开源的应用不能用在商业用途,如 Meta 的 LLaMa。目前国内外只有极少数的大模型开放商用开源,百川智能最新推出的 baichuan-7B 是国内首家。因此,解决正规大模型提供方与企业用户在合作上的数据安全问题是首当其冲。
三是落地成本的可控性。
通常来说,企业调用大模型的成本有两块,一是模型训练的费用,二是模型推理(即模型应用与调优)的费用。
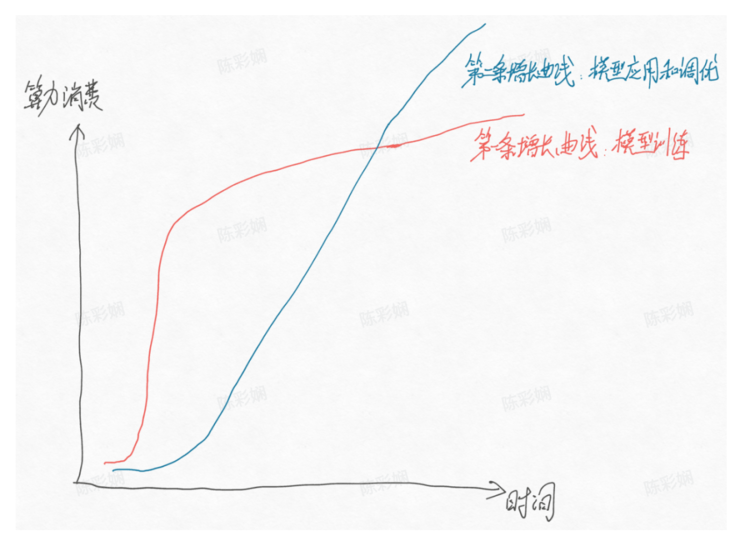
火山引擎智能算法负责人吴迪将这两块分别形容为大模型时代在算力上的「第一增长曲线」与「第二增长曲线」,其中第一增长曲线的结果已经得到验证,并预言两条曲线大约在 2024 年相遇(如下图)。而在第二增长曲线中,企业将扮演重要角色,大模型在行业的落地成本也主要体现在应用与调优上。
在《大模型时代的三道鸿沟》一文中,我们指出了企业应用大模型的一个「悖论」:企业希望在性能最好的大模型上做微调训练,然后再进行私有化部署。但在实际调用 API 的过程中,许多开源的大模型版本都是相对固定的,所以企业无法基于最新的模型版本进行微调。
国内大模型成果虽多,但企业在选定一家模型的过程中需要一一验证,时间与人力成本均难以把控。即使经过验证作出选择,也无法使用最新模型,这就降低了传统行业在大模型时代崛起早期的参与意愿,尤其降低付费意愿。
大模型的微调成本并不低。以 GPT-3.5 为例,未经调优的 API 价格是 0.02 美元,微调后的价格则变成了原来的 6 倍,即 0.12 美元。大模型的训练成本低,上线部署的价格才会降低。随着市场化的深入,大模型必将进入价格战,底层技术的比拼将成为模型卖方争取 B 端客户的终极杀手锏。