Java性能权威指南-总结25
- 数据库性能的最佳实践
- 随机数
- Java原生接口
- 字符串的性能
数据库性能的最佳实践
随机数
Java7提供了3个标准的随机数生成器类:java.util.Random、java.util.concurrent.ThreadLocalRandom以及java.security.SecureRandom。这三个类在性能方面差距很大。
Random和ThreadLocalRandom两个类的差别是,Random类的主要操作(nextGaussian())是同步的。任何要获取随机值的方法都会用到这个方法,所以不管如何使用该随机数生成器,都会存在锁竞争:如果两个线程同时使用同一随机数生成器,那一个线程要等待另一个先完成其操作。 之所以会使用ThreadLocalRandom,原因就在于此:每个线程都有自己的随机数生成器,Random类的同步就不是问题了。(因为创建对象成本很高,而ThreadLocalRandom类会重用对象,所以有很大的性能优势。)
SecureRandom类与上面介绍的两个类的区别是,所用的算法不同。Random类(以及继承它而来的ThreadLocalRandom)实现了一个典型的伪随机数算法。尽管那些算法非常复杂,但到底是确定性的。如果知道初始种子,很容易确定该引擎将生成的数字的精确序列。这意味着,黑客能够从特定的生成器看到数字序列,也就能够指出下一个数字是什么。尽管好的伪随机数生成器可以生成看上去真正随机的数字序列(甚至符合随机性的概率期望),但这仍然不是真正的随机。
而另一方面,SecureRandom类使用一个系统接口来获得随机数。数据生成方式与所用的操作系统有关,不过一般而言,这类源提供了基于真正随机事件(比如鼠标移动时)的数据。这就是所谓的基于熵的随机性,比依赖随机数的操作更安全。SSL熵是这类操作中最广为人知的例子:加密所用的随机数不可能通过基于熵的源来确定。(即便在算法中使用了SecureRandom随机数生成器,还是有其他方式可以攻破数据的加密算法。)
计算机生成的熵的数量是有限的,所以要从一个安全随机数生成器获得大量的随机数,需要很长时间。调用SecureRandom类的nextRandom()方法消耗的时间并不确定,跟系统中还有多少熵尚未使用有关。如果没有熵可用,这个调用看上去就挂起了,可能一次长达数秒,直到有可用的熵为止。所以对性能的计时非常困难,因为性能本身也是随机的。
对于会创建很多SSL连接,或者需要大量安全随机数的应用而言,这往往会成为问题;这样的应用要花很多时间去执行其操作。当在一个这样的应用上执行性能测试时,计时会有很多变数。除了运行大量示例测试,其实没什么办法处理此类变数。
必要时,可以使用Random类运行性能测试,即便在生产环境中使用的是SecureRandom类。如果性能测试是模块级的,这会很有意义:在同样的一段时间内,与产品系统相比,这些测试需要的随机数更多(比如需要更多SSL套接字)。但是,最终预期的负载必须用SecureRandom类来测试,以确定生产系统上的负载是否能够获得足够的随机数。
快速小结
- Java默认的
Random类的初始化的成本很高,但是一旦初始化完毕,就可以重用。 - 在多线程代码中,应该首选
ThreadLocalRandom类。 SecureRandom类表现出的性能也是随意的和完全随机的。在对用到这个类的代码做性能测试时,一定要认真规划。
Java原生接口
如果想编写尽可能快的代码,要避免使用JNI。
在现行的JVM版本上,编写得好的Java代码至少会与相应的C或C++代码跑得一样快。然而这里要说的是:如果某个应用已经是用Java编写的,那出于性能原因调用原生代码几乎总是一个坏主意。
JNI有时仍然非常有用。Java平台提供了不同操作系统的很多公共特性,但如果需要访问一个特殊的、特定于操作系统的函数,那JNI就派上用场了。 如果有现成的商用原生代码,那为什么还要构建自己的执行操作的库呢?在这种情况和其他一些情况下,问题就变成了如何编写最高效的JNI代码。
答案是尽可能避免从Java调用C。跨JNI边界(边界是描述跨语言调用的术语)成本非常高,这是因为,调用一个现有的C库首先需要一些胶水代码,需要花时间通过胶水代码创建新的、粗粒度的接口,一下子要多次进入C库。
反过来就未必如此了:从C代码调用回Java不会有很大的性能损失(与所用的参数有关)。比如,考虑下面的代码:
public void main() {
calculateError();
}
public void calculateError() {
for (int i = 0; i < numberOfTrials; i++) {
error += 50 - calc(numberofIterations);
}
}
public double calc(int n) {
double sun = θ;
for (int i = 0; i < n; i++) {
int r = random(100);//返回1至100之间的一个随机值
sum += r;
}
return sun / n;
}
这段(完全没有实际意义的)代码有两个主循环:内层循环多次调用生成随机数的代码,外层循环重复调用内层循环,看看所得的随机数与预期值(这里是50)的接近程度。通过JNI,可以用C实现calculateError()、calc()和random()这些方法中的任何一个或多个。下表展示了不同组合情况下的性能,其中numberofTrials为10000。
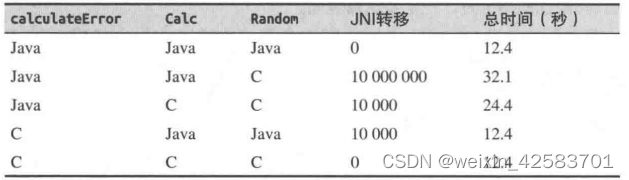
仅用JNI调用实现最内层方法,跨JNI边界的次数最多(nunberOfTrials * numberofloops, 1千万次)。将跨边界次数减少到numberofTrials(即10000)可以大幅减少开销,而将其减到0,性能会最好——至少从JNI角度看是这样,尽管纯Java实现和完全使用原生代码一样快。
如果所用的参数不是简单的基本类型,JNI代码性能会更糟。这一开销涉及两个方面。
第一,对于简单的引用,需要地址转换。这也是为什么在上面的例子中,从Java调用C比从C调用Java开销更大:从Java调用C,会隐式地把问题中的对象(this)传递给C函数,从C调用Java则无需传递任何对象。
第二,对于基于数组的数据,其中的操作在原生代码中会进行特殊处理。这包括String对象,因为字符串数据本质上是一个字符数组。要访问这类数组中的单个元素,必须调用一个特殊的方法,将该对象固定在内存中(对于String对象,要将其从Java的UTF-16编码转换成UTF-8)。当不再需要数组时,必须在JNI代码中显式地释放。当有数组被固定在内存中时,垃圾收集器就无法运行——所以JNI代码中代价最高的错误之一就是在长期运行的代码中固定了一个字符串或数组。这会阻碍垃圾收集器运行,实际上也阻塞了所有应用线程,直到JNI代码完成。对于会固定数组的临界区,尽可能缩短固定时间极为重要。
有时,后面这个目标会与减少跨JNI边界调用这个目标冲突。这种情况下,后一个目标更重要:即使这意味着要多次跨JNI边界,也要让固定数组和字符串的代码区尽可能短。
快速小结
JNI并不能解决性能问题。Java代码几乎总是比调用原生代码跑得快。- 当使用
JNI时,应该限制从Java到C的调用次数;跨JNI边界的调用成本很高。 - 使用数组或字符串的
JNI代码必须固定这些对象;为避免影响垃圾收集器,应该限制固定对象的时间。
字符串的性能
字符串对Java非常重要。
字符串保留
创建多个包含相同字符序列的字符串对象,这种情况很常见。没有必要在堆中为所有这些对象都分配空间;因为字符串是不可变的,所以重用现有的字符串往往更好。
字符串编码
Java的字符串采用的是UTF-16编码,而其他地方多是使用其他编码,所以将字符串编码到不同的字符集的操作很常见。对于Charset类的encode()和decode()方法而言,如果一次只处理一个或几个字符,它们会非常慢;务必完整缓存一些数据,再进行处理。
网络编码
在编码静态字符串(来自JSP文件等地方)时,Java EE应用服务器往往会特殊处理;字符串连接是另一个可能会出现性能问题的地方。考虑这样一个简单的字符串连接操作:
String answer = integerPart + "." + mantissa;
这行代码实际上非常高效;javac编译器的语法糖会将其转换为如下代码:
String answer = new StringBuilder(integerPart).append(".").append(mantissa).tostring();
不过问题来了,如果这个字符串是逐步构造起来的:
String answer = integerPart;
answer += ".";
answer += mantissa;
那么这段代码就会被翻译为:
String answer = new StringBuilder(integerPart).tostring();
answer = new StringBuilder(answer).append(".").toString();
answer = new StringBuilder(answer).append(mantissa).toString();
所有那些临时的StringBuilder对象和中间的String对象都很低效。永远不要使用连接来构造字符串,除非能在逻辑意义上的一行代码内完成;也不要在循环内使用字符串连接,除非连接后的字符串不会用于下一次循环迭代。 对于其他情况,应该总是使用StringBuilder,以获得更好的性能。
快速小结
- 一行的字符串连接代码性能很不错。
- 对于多行的连接操作,一定要确保使用
StringBuilder。