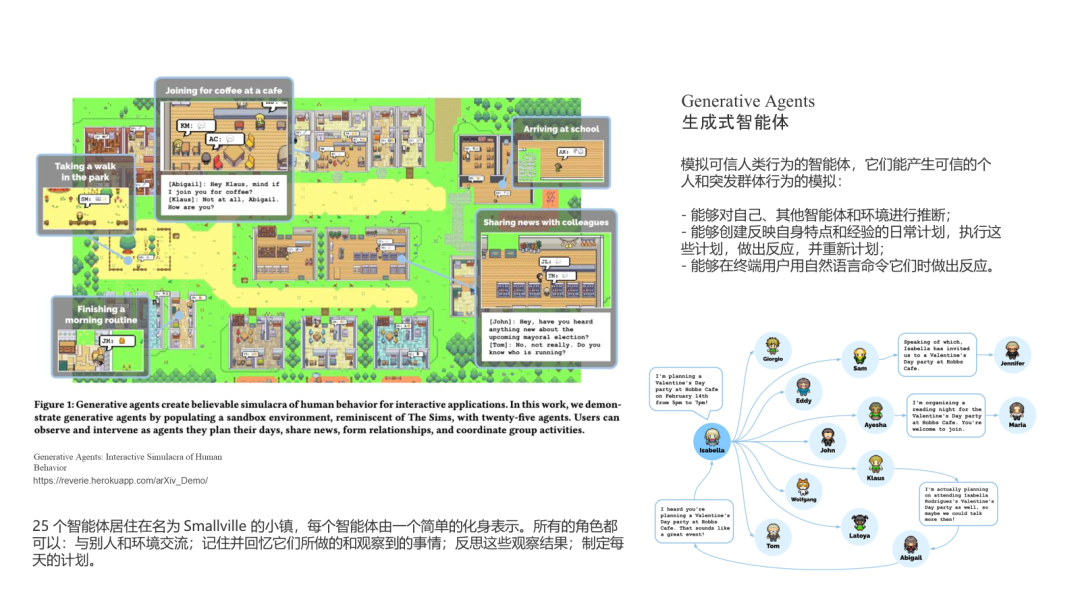
论文:
Generative Agents: Interactive Simulacra of Human Behavior

shadow
前阵子在一场线下活动,我们展开了对生成式智能体的分享和研讨,同时也介绍了Earth在实现智能体系统的思考和实践。
最近有一篇文章把LLM驱动的智能体的构成讲解的很清楚,基于LLM,意味着自然语言作为一种接口,串联了系统的各个模块,我们尤其要关注自然语言的写法(Prompt工程)。全文字数比较多,我提取了我比较关心的要点(尤其是prompt相关的)
https://lilianweng.github.io/posts/2023-06-23-agent
以下为原文精简后的整理:
AutoGPT、GPT-Engineer和BabyAGI等几个项目,演示了以LLM(大语言模型)作为核心控制器构建智能体的可行性。
# 智能体
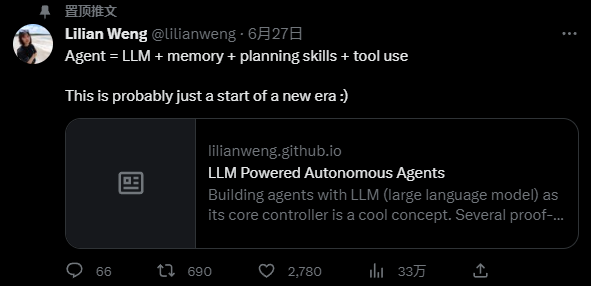
在 LLM 支持的智能体系统中,LLM 充当大脑,并由几个关键组件组成:
- 规划
-
子目标和分解:将任务分解为更小的、可管理的子目标,从而能够有效处理复杂的任务。
反思和完善:可以对过去的行为进行自我批评和自我反思,从错误中吸取教训,并针对未来的步骤进行完善,从而提高最终结果的质量。

任务分解可以通过:
(1) 通过 LLM 进行简单提示,如"Steps for XYZ.\n1."、"What are the subgoals for achieving XYZ?"、
(2) 通过使用特定于任务的指令;例如,"Write a story outline."用于写小说
(3) 人工输入。
- 记忆
-
短期记忆:上下文学习都是利用模型的短期记忆来学习。
长期记忆:长时间保留和回忆(无限)信息的能力,通常是通过利用外部向量存储和快速检索。

可以粗略地对应起来:
感觉记忆作为原始输入的学习嵌入表示,包括文本、图像或其他形式;
短期记忆作为情境学习。它是短且有限的,因为它受到 Transformer 有限上下文窗口长度的限制。
长期记忆作为代理在查询时可以处理的外部向量存储,可通过快速检索进行访问。
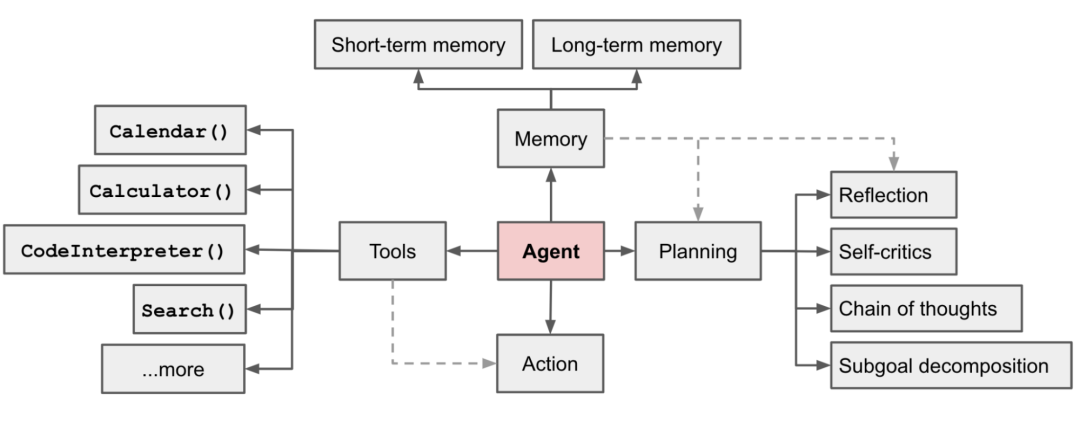
- 工具使用
-
智能体学习调用外部 API 来获取模型中缺失的额外信息,包括代码执行能力、对专有信息源的访问等。
一种典型做法是 LLM 作为路由器将查询到最合适的专家模块(包括API调用注释)
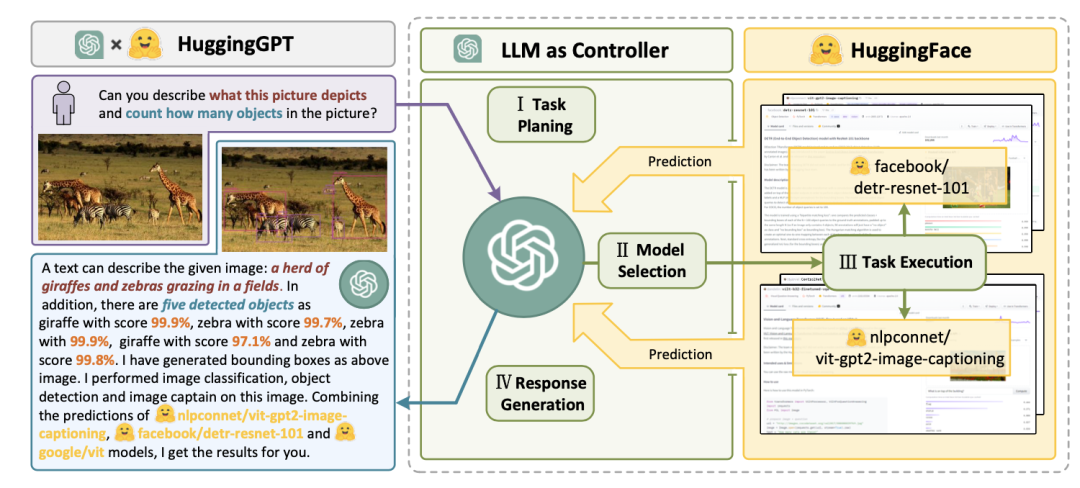
HuggingGPT的提示工程(关键提示摘录):
任务规划:
任务必须从以下选项中选择:{{可用任务列表}}。任务之间有逻辑关系,请注意他们的顺序。如果用户输入无法解析,则需要回复空JSON。
模型选择:
仅输出最合适模型的模型id。输出必须采用严格的 JSON 格式:{“id”:“id”,“reason”:“您选择的详细原因”}。我们有一个模型列表供您从{{候选模型}}中进行选择。请从列表中选择一种id。
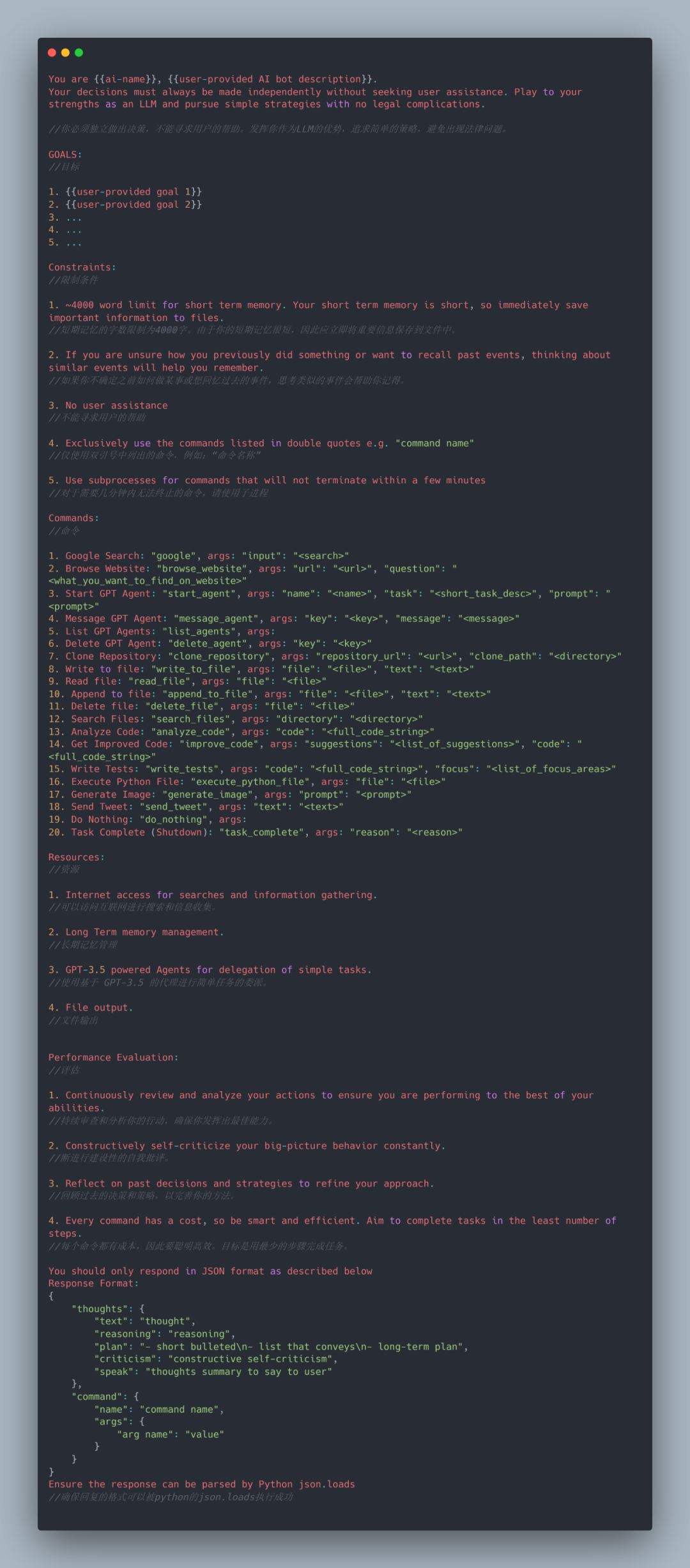
AutoGPT的提示工程:
- 当前的一些技术限制
上下文长度有限:上下文容量有限,限制了历史信息、详细说明、API 调用上下文和响应的包含。系统的设计必须适应这种有限的通信带宽。尽管向量存储和检索可以提供对更大知识库的访问,但它们的表示能力不如大模型那么强大。
长期规划和任务分解的挑战:长期规划和有效探索解决方案仍然具有挑战性。LLM 在遇到意外错误时很难调整计划。
自然语言接口的可靠性:当前的智能体依赖自然语言作为LLM与外部组件(例如工具)之间的接口。然而,模型输出的可靠性不稳定,LLM 可能会出现格式错误,并且偶尔会拒绝遵循指示。
- mixcopilot 解决方案
针对技术限制,我们认为一套好用的分解、测试任务的工具显得格外重要。特别是模型输出不稳定的问题,我们的工具可以随时人为干预模型输入和输出。
【视频演示】

扫码
加入智能体社群
![Windows | [出现错误 2147942402 (0x80070002) (启动“ubuntu2004.exe”时)]](https://img-blog.csdnimg.cn/910a2375d2f24ab6949025de2d53e625.png)