目录
- 0 专栏介绍
- 1 从一个例子出发
- 2 回报与奖赏
- 3 策略评估函数
- 4 贝尔曼期望方程
- 5 收敛性证明
0 专栏介绍
本专栏重点介绍强化学习技术的数学原理,并且采用Pytorch框架对常见的强化学习算法、案例进行实现,帮助读者理解并快速上手开发。同时,辅以各种机器学习、数据处理技术,扩充人工智能的底层知识。
🚀详情:《Pytorch深度强化学习》
1 从一个例子出发
例1:如图所示的真空吸尘器世界只有两个地点:方格A和B。假设吸尘器Agent的传感器可以感知自身处于哪个方格中,以及方格中是否有灰尘;它具有且仅具有左移、右移、吸尘或什么也不做四种行为;假设吸尘器Agent采用的策略是若当前所在地点有灰尘则进行清洁,否则往另一个地点运动。请用马尔科夫决策过程表示吸尘器问题
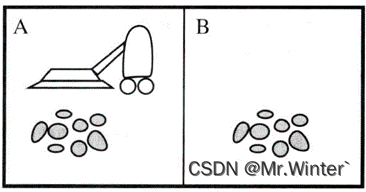
如图所示即为例1的一种马尔科夫决策过程,其设计思路是:只要采取移动就会造成一定的损失,在有灰尘的方格中若智能体不采取吸尘则会造成严重的损失。朴素地,最优策略在当前方格有灰尘时选择“吸尘”直至清扫干净,在当前方格无灰尘时选择“移动”进行巡查或“什么也不做”节省能源
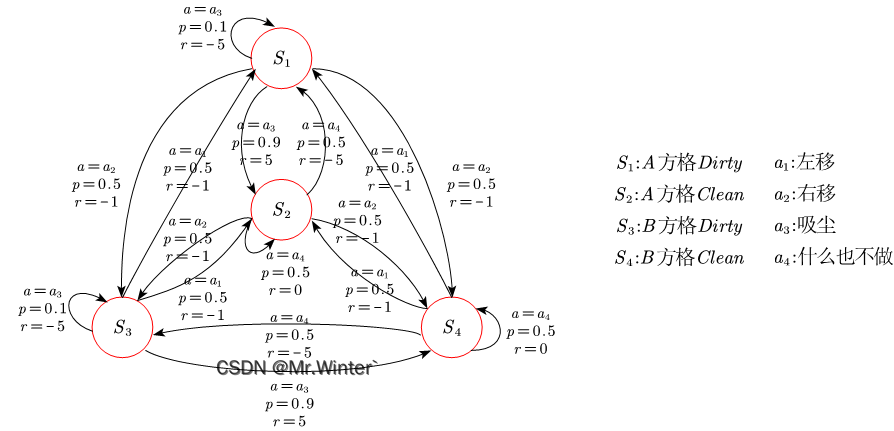
那么问题来了,智能体要如何决策才能使其长期运行下去得到的奖励最多呢? 这就是本文要讨论的策略评估问题
2 回报与奖赏
强化学习的目标是找到一个策略
π ( s , a ) = P ( a c t i o n = a ∣ s t a t e = s ) \pi \left( s,a \right) =P\left( \mathrm{action}=a|\mathrm{state}=s \right) π(s,a)=P(action=a∣state=s)
使智能体长期执行该策略后得到的回报(Return)最大化。自然地,需要定义回报与策略评估的计算方法。引入回报函数:
- T T T步回报函数
R t = 1 T ∑ i = t + 1 T r i R_t=\frac{1}{T}\sum_{i=t+1}^T{r_i} Rt=T1i=t+1∑Tri
- γ \gamma γ折扣回报函数
R t = ∑ i = t + 1 ∞ γ i − t r i R_t=\sum_{i=t+1}^{\infty}{\gamma ^{i-t}r_i} Rt=i=t+1∑∞γi−tri
其中 R t R_t Rt是从 t t t时刻状态 s t s_t st开始计算的回报,当执行某动作转移到下一个状态时产生第一个奖赏,因此从 t + 1 t+1 t+1时刻开始求和。 r i r_i ri是第 i i i步的单步奖赏,是一个随机变量。迭代因子 T ⩾ 1 T\geqslant 1 T⩾1与折扣因子 γ < 1 \gamma <1 γ<1都对奖赏期望序列进行加权,在数学上使级数收敛。在物理意义上, T T T、 γ \gamma γ越大表示考虑决策的长期回报; T T T、 γ \gamma γ越小表示考虑决策的短期收益。特别地,当 T = 1 T=1 T=1或 γ = 0 \gamma=0 γ=0表示单步强化学习任务。
3 策略评估函数
策略评估函数分为两种
- 状态值函数
V
π
(
s
)
V^{\pi}\left( s \right)
Vπ(s)
表示从 t t t时刻状态 s s s出发,采用策略 π \pi π带来的回报期望
{ V T π ( s ) = E [ R t ] ∣ s t = s = 1 T ∑ i = t + 1 T E [ r i ] ∣ s t = s V γ π ( s ) = E [ R t ] ∣ s t = s = ∑ i = t + 1 ∞ γ i − t E [ r i ] ∣ s t = s \begin{cases} V_{T}^{\pi}\left( s \right) =\mathbb{E} \left[ R_t \right] \mid_{s_t=s}^{}=\frac{1}{T}\sum_{i=t+1}^T{\mathbb{E} \left[ r_i \right] \mid_{s_t=s}^{}}\\ V_{\gamma}^{\pi}\left( s \right) =\mathbb{E} \left[ R_t \right] \mid_{s_t=s}^{}=\sum_{i=t+1}^{\infty}{\gamma ^{i-t}\mathbb{E} \left[ r_i \right] \mid_{s_t=s}^{}}\\\end{cases} {VTπ(s)=E[Rt]∣st=s=T1∑i=t+1TE[ri]∣st=sVγπ(s)=E[Rt]∣st=s=∑i=t+1∞γi−tE[ri]∣st=s - 状态动作值函数
Q
π
(
s
,
a
)
Q^{\pi}\left( s,a \right)
Qπ(s,a)
表示从 t t t时刻状态 s s s出发,执行动作 a a a后再采用策略 π \pi π带来的回报期望
{ Q T π ( s , a ) = E [ R t ] ∣ s t = s , a t = a = 1 T ∑ i = t + 1 T E [ r i ] ∣ s t = s , a t = a Q γ π ( s , a ) = E [ R t ] ∣ s t = s , a t = a = ∑ i = t + 1 ∞ γ i − t E [ r i ] ∣ s t = s , a t = a \begin{cases} Q_{T}^{\pi}\left( s,a \right) =\mathbb{E} \left[ R_t \right] \mid_{s_t=s,a_t=a}^{}=\frac{1}{T}\sum_{i=t+1}^T{\mathbb{E} \left[ r_i \right] \mid_{s_t=s,a_t=a}^{}}\\ Q_{\gamma}^{\pi}\left( s,a \right) =\mathbb{E} \left[ R_t \right] \mid_{s_t=s,a_t=a}^{}=\sum_{i=t+1}^{\infty}{\gamma ^{i-t}\mathbb{E} \left[ r_i \right] \mid_{s_t=s,a_t=a}^{}}\\\end{cases} {QTπ(s,a)=E[Rt]∣st=s,at=a=T1∑i=t+1TE[ri]∣st=s,at=aQγπ(s,a)=E[Rt]∣st=s,at=a=∑i=t+1∞γi−tE[ri]∣st=s,at=a
其中 s t s_t st表示评估的初始状态, a t a_t at表示在初始状态上采取的第一个动作
下面研究 V π ( s ) V^{\pi}\left( s \right) Vπ(s)与 Q π ( s , a ) Q^{\pi}\left( s,a \right) Qπ(s,a)的关系。根据全概率公式,状态值函数 V π ( s ) V^{\pi}\left( s \right) Vπ(s)可用状态动作值函数 Q π ( s , a ) Q^{\pi}\left( s,a \right) Qπ(s,a)加权得到
V π ( s ) = ∑ a ∈ A P ( a ∣ s ) Q π ( s , a ) = ∑ a ∈ A π ( s , a ) Q π ( s , a ) V^{\pi}\left( s \right) =\sum_{a\in A}{P\left( a|s \right) Q^{\pi}\left( s,a \right)}={\sum_{a\in A}{\pi \left( s,a \right) Q^{\pi}\left( s,a \right)}} Vπ(s)=a∈A∑P(a∣s)Qπ(s,a)=a∈A∑π(s,a)Qπ(s,a)
以 T T T步回报函数为例说明 Q π ( s , a ) Q^{\pi}\left( s,a \right) Qπ(s,a)如何用 V π ( s ) V^{\pi}\left( s \right) Vπ(s)表示
Q T π ( s , a ) = 1 T ∑ i = t + 1 T E [ r i ] ∣ s t = s , a t = a = 1 T [ E [ r t + 1 ] ∣ s t = s , a t = a + ∑ i = t + 2 T E [ r i ] ∣ s t = s , a t = a ] = 1 T [ ∑ s ′ ∈ S P s → s ′ a R s → s ′ a + ∑ s ′ ∈ S P s → s ′ a ∑ i = t + 2 T E [ r i ] ∣ s t + 1 = s ′ ] = ∑ s ′ ∈ S P s → s ′ a [ 1 T R s → s ′ a + T − 1 T 1 T − 1 ∑ i = t + 1 T − 1 E [ r i ] ∣ s t = s ′ ] \begin{aligned}Q_{T}^{\pi}\left( s,a \right) &=\frac{1}{T}\sum_{i=t+1}^T{\mathbb{E} \left[ r_i \right]}\mid_{s_t=s,a_t=a}^{}\\&=\frac{1}{T}\left[ \mathbb{E} \left[ r_{t+1} \right] \mid_{s_t=s,a_t=a}^{}+\sum_{i=t+2}^T{\mathbb{E} \left[ r_i \right] \mid_{s_t=s,a_t=a}^{}} \right] \\&=\frac{1}{T}\left[ \sum_{s'\in S}{P_{s\rightarrow s'}^{a}}R_{s\rightarrow s'}^{a}+\sum_{s'\in S}{P_{s\rightarrow s'}^{a}}\sum_{i=t+2}^T{\mathbb{E} \left[ r_i \right] \mid_{s_{t+1}=s'}^{}} \right] \\&=\sum_{s'\in S}{P_{s\rightarrow s'}^{a}}\left[ \frac{1}{T}R_{s\rightarrow s'}^{a}+\frac{T-1}{T}\frac{1}{T-1}\sum_{i=t+1}^{T-1}{\mathbb{E} \left[ r_i \right] \mid_{s_t=s'}^{}} \right]\end{aligned} QTπ(s,a)=T1i=t+1∑TE[ri]∣st=s,at=a=T1[E[rt+1]∣st=s,at=a+i=t+2∑TE[ri]∣st=s,at=a]=T1[s′∈S∑Ps→s′aRs→s′a+s′∈S∑Ps→s′ai=t+2∑TE[ri]∣st+1=s′]=s′∈S∑Ps→s′a[T1Rs→s′a+TT−1T−11i=t+1∑T−1E[ri]∣st=s′]
即
Q T π ( s , a ) = ∑ s ′ ∈ S P s → s ′ a [ 1 T R s → s ′ a + T − 1 T V T − 1 π ( s ′ ) ] {Q_{T}^{\pi}\left( s,a \right) =\sum_{s'\in S}{P_{s\rightarrow s'}^{a}}\left[ \frac{1}{T}R_{s\rightarrow s'}^{a}+\frac{T-1}{T}V_{T-1}^{\pi}\left( s' \right) \right] } QTπ(s,a)=s′∈S∑Ps→s′a[T1Rs→s′a+TT−1VT−1π(s′)]
同理有
Q γ π ( s , a ) = ∑ s ′ ∈ S P s → s ′ a [ R s → s ′ a + γ V γ π ( s ′ ) ] {Q_{\gamma}^{\pi}\left( s,a \right) =\sum_{s'\in S}{P_{s\rightarrow s'}^{a}}\left[ R_{s\rightarrow s'}^{a}+\gamma V_{\gamma}^{\pi}\left( s' \right) \right] } Qγπ(s,a)=s′∈S∑Ps→s′a[Rs→s′a+γVγπ(s′)]
4 贝尔曼期望方程
策略评估是给定一个策略 π \pi π计算策略评估函数 V π ( s ) V^{\pi}\left( s \right) Vπ(s)或 Q π ( s , a ) Q^{\pi}\left( s,a \right) Qπ(s,a)的过程,用于衡量策略的好坏。策略评估通常采用迭代法而非第三节中的定义计算
根据强化学习任务的马尔科夫性,多步强化学习中的某一步仅与上一步的状态和动作有关,将第三节的式子
-
V π ( s ) = ∑ a ∈ A P ( a ∣ s ) Q π ( s , a ) = ∑ a ∈ A π ( s , a ) Q π ( s , a ) V^{\pi}\left( s \right) =\sum_{a\in A}{P\left( a|s \right) Q^{\pi}\left( s,a \right)}={\sum_{a\in A}{\pi \left( s,a \right) Q^{\pi}\left( s,a \right)}} Vπ(s)=∑a∈AP(a∣s)Qπ(s,a)=∑a∈Aπ(s,a)Qπ(s,a)
-
Q γ π ( s , a ) = ∑ s ′ ∈ S P s → s ′ a [ R s → s ′ a + γ V γ π ( s ′ ) ] {Q_{\gamma}^{\pi}\left( s,a \right) =\sum_{s'\in S}{P_{s\rightarrow s'}^{a}}\left[ R_{s\rightarrow s'}^{a}+\gamma V_{\gamma}^{\pi}\left( s' \right) \right] } Qγπ(s,a)=∑s′∈SPs→s′a[Rs→s′a+γVγπ(s′)]
互相代入,即可推导出强化学习的贝尔曼递推公式(Bellman Equation)或称贝尔曼期望方程,如下
{ V γ π ( s ) = ∑ a ∈ A π ( s , a ) ∑ s ′ ∈ S P s → s ′ a [ R s → s ′ a + γ V γ π ( s ′ ) ] Q γ π ( s , a ) = ∑ s ′ ∈ S P s → s ′ a [ R s → s ′ a + γ ∑ a ′ ∈ A π ( s ′ , a ′ ) Q γ π ( s ′ , a ′ ) ] {\begin{cases} V_{\gamma}^{\pi}\left( s \right) =\sum_{a\in A}{\pi \left( s,a \right)}\sum_{s'\in S}{P_{s\rightarrow s'}^{a}}\left[ R_{s\rightarrow s'}^{a}+\gamma V_{\gamma}^{\pi}\left( s' \right) \right]\\ Q_{\gamma}^{\pi}\left( s,a \right) =\sum_{s'\in S}{P_{s\rightarrow s'}^{a}}\left[ R_{s\rightarrow s'}^{a}+\gamma \sum_{a'\in A}{\pi \left( s',a' \right) Q_{\gamma}^{\pi}\left( s',a' \right)} \right]\\\end{cases}} {Vγπ(s)=∑a∈Aπ(s,a)∑s′∈SPs→s′a[Rs→s′a+γVγπ(s′)]Qγπ(s,a)=∑s′∈SPs→s′a[Rs→s′a+γ∑a′∈Aπ(s′,a′)Qγπ(s′,a′)]
5 收敛性证明
上述迭代公式属于不动点方程。设贝尔曼期望算子为 B π \mathcal{B} ^{\pi} Bπ,则
∣ ( B π V 1 π ) ( s ) − ( B π V 2 π ) ( s ) ∣ = ∣ γ ∑ a ∈ A π ( s , a ) ∑ s ′ ∈ S P s → s ′ a [ V 1 π ( s ′ ) − V 2 π ( s ′ ) ] ∣ ⩽ γ ∑ a ∈ A π ( s , a ) ∑ s ′ ∈ S P s → s ′ a ∣ V 1 π ( s ′ ) − V 2 π ( s ′ ) ∣ 绝对值不等式 ⩽ γ ∑ a ∈ A π ( s , a ) ∑ s ′ ∈ S P s → s ′ a [ max s ′ ′ ∣ V 1 π ( s ′ ′ ) − V 2 π ( s ′ ′ ) ∣ ] = γ ∥ V 1 π ( s ) − V 2 π ( s ) ∥ ∞ \begin{aligned}\left| \left( \mathcal{B} ^{\pi}V_{1}^{\pi} \right) \left( s \right) -\left( \mathcal{B} ^{\pi}V_{2}^{\pi} \right) \left( s \right) \right|&=\left| \gamma \sum_{a\in A}{\pi \left( s,a \right)}\sum_{s'\in S}{P_{s\rightarrow s'}^{a}}\left[ V_{1}^{\pi}\left( s' \right) -V_{2}^{\pi}\left( s' \right) \right] \right|\\&\leqslant \gamma \sum_{a\in A}{\pi \left( s,a \right)}\sum_{s'\in S}{P_{s\rightarrow s'}^{a}}\left| V_{1}^{\pi}\left( s' \right) -V_{2}^{\pi}\left( s' \right) \right|\,\, {\text{绝对值不等式}}\\&\leqslant \gamma \sum_{a\in A}{\pi \left( s,a \right)}\sum_{s'\in S}{P_{s\rightarrow s'}^{a}}\left[ \underset{s''}{\max}\left| V_{1}^{\pi}\left( s'' \right) -V_{2}^{\pi}\left( s'' \right) \right| \right] \\&=\gamma \left\| V_{1}^{\pi}\left( s \right) -V_{2}^{\pi}\left( s \right) \right\| _{\infty}\end{aligned} ∣(BπV1π)(s)−(BπV2π)(s)∣= γa∈A∑π(s,a)s′∈S∑Ps→s′a[V1π(s′)−V2π(s′)] ⩽γa∈A∑π(s,a)s′∈S∑Ps→s′a∣V1π(s′)−V2π(s′)∣绝对值不等式⩽γa∈A∑π(s,a)s′∈S∑Ps→s′a[s′′max∣V1π(s′′)−V2π(s′′)∣]=γ∥V1π(s)−V2π(s)∥∞
上述不等式对 ∀ s ∈ S \forall s\in S ∀s∈S都成立,不妨取
s = a r g max s ∣ ( B π V 1 π ) ( s ) − ( B π V 2 π ) ( s ) ∣ s=\mathrm{arg}\max _s\left| \left( \mathcal{B} ^{\pi}V_{1}^{\pi} \right) \left( s \right) -\left( \mathcal{B} ^{\pi}V_{2}^{\pi} \right) \left( s \right) \right| s=argsmax∣(BπV1π)(s)−(BπV2π)(s)∣
则
∣ ( B π V 1 π ) ( s ) − ( B π V 2 π ) ( s ) ∣ ∞ ⩽ γ ∥ V 1 π ( s ) − V 2 π ( s ) ∥ ∞ \left| \left( \mathcal{B} ^{\pi}V_{1}^{\pi} \right) \left( s \right) -\left( \mathcal{B} ^{\pi}V_{2}^{\pi} \right) \left( s \right) \right|_{\infty}\leqslant \gamma \left\| V_{1}^{\pi}\left( s \right) -V_{2}^{\pi}\left( s \right) \right\| _{\infty} ∣(BπV1π)(s)−(BπV2π)(s)∣∞⩽γ∥V1π(s)−V2π(s)∥∞
所以 B π \mathcal{B} ^{\pi} Bπ是一个压缩映射,根据巴拿赫不动点定理,映射 B π \mathcal{B} ^{\pi} Bπ存在唯一的不动点 。换言之,若需要求解状态值函数 V π ( s ) V^{\pi}\left( s \right) Vπ(s),可以任取一个值 V 0 π ( s ) V_{0}^{\pi}\left( s \right) V0π(s)进行迭代,最终收敛到正确的 V π ( s ) V^{\pi}\left( s \right) Vπ(s)值
lim k → ∞ ( B π ) k V 0 π = V π \lim _{k\rightarrow \infty}\left( \mathcal{B} ^{\pi} \right) ^kV_{0}^{\pi}=V^{\pi} k→∞lim(Bπ)kV0π=Vπ
这就是强化学习中策略评估的理论保证
🔥 更多精彩专栏:
- 《ROS从入门到精通》
- 《Pytorch深度学习实战》
- 《机器学习强基计划》
- 《运动规划实战精讲》
- …


![BUU [vnctf2023]电子木鱼](https://img-blog.csdnimg.cn/img_convert/bcdbad18655a76fc25c6dddf528ddaa9.png)