文章目录
- The Fully Convolutional Transformer for Medical Image Segmentation
- 摘要
- 本文方法
- 实验结果
The Fully Convolutional Transformer for Medical Image Segmentation
摘要
我们提出了一种新的Transformer ,能够分割不同模式的医学图像。医学图像分析的细粒度特性所带来的挑战意味着Transformer 对其分析的适应仍处于初级阶段。UNet的巨大成功在于它能够理解分割任务的细粒度性质,这是现有的基于变压器的模型目前所不具备的能力。为了解决这个缺点,我们提出了全卷积Transformer (FCT),它建立在卷积神经网络学习有效图像表示的成熟能力之上,并将它们与Transformer 有效捕获其输入中的长期依赖关系的能力相结合。
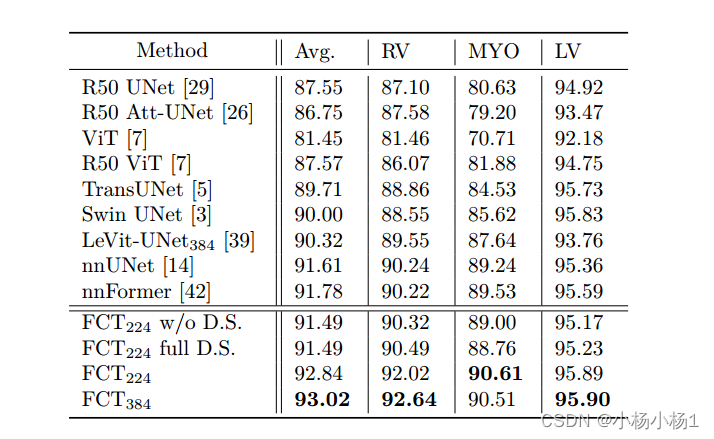
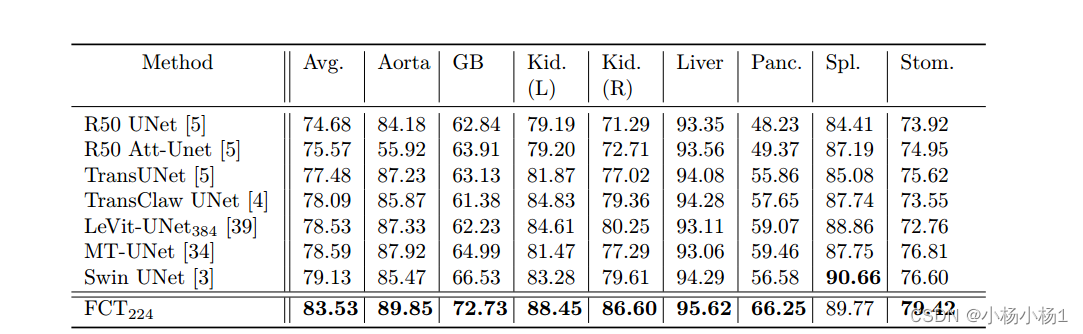
FCT是医学影像文献中第一个完全卷积的Transformer模型。它分两个阶段处理输入,首先,它学习从输入图像中提取长期语义依赖关系,然后学习从特征中捕获分层全局属性。FCT结构紧凑、准确、坚固。我们的研究结果表明,在不需要任何预训练的情况下,它在不同数据模式的多个医学图像分割数据集上大大优于所有现有的变压器架构。FCT在ACDC数据集上比其直接竞争对手高出1.3%,在Synapse数据集上高出4.4%,在脾脏数据集上高出1.2%,在ISIC 2017数据集上高出1.1%,参数减少了五倍
代码地址
本文方法
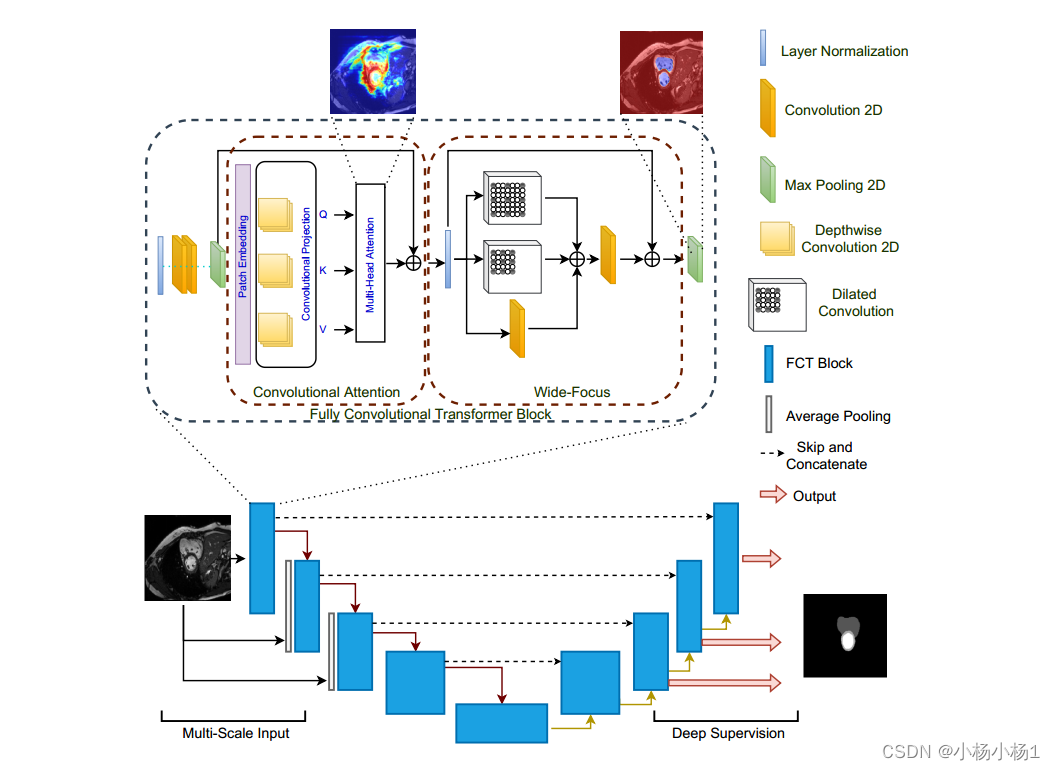
网络(底部)遵循标准的UNet形状,明显的区别是它纯粹是基于卷积-变压器的。FCT层的第一个组成部分(顶部)是卷积注意。在这里,投影层中的深度卷积消除了对位置编码的需要,导致了一个更简单的模型。我们创建重叠的patch,其中patch重叠的程度是通过卷积投影层的步幅来控制的。为了利用图像中的空间背景,我们的MHSA块用深度卷积取代了线性投影。
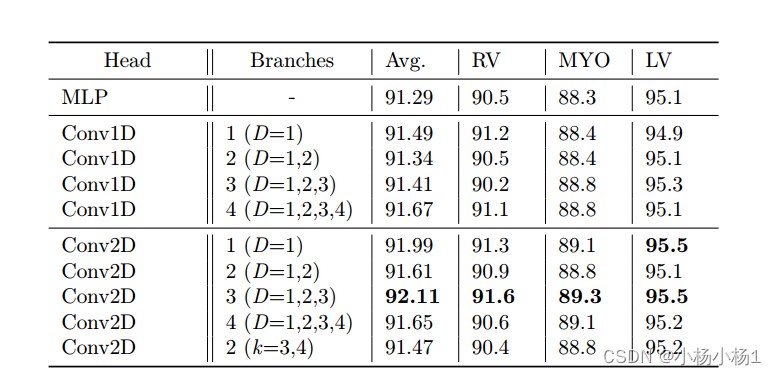
wide-focus应用扩展卷积在线性增加的接受野对MHSA输出
看代码会更清晰
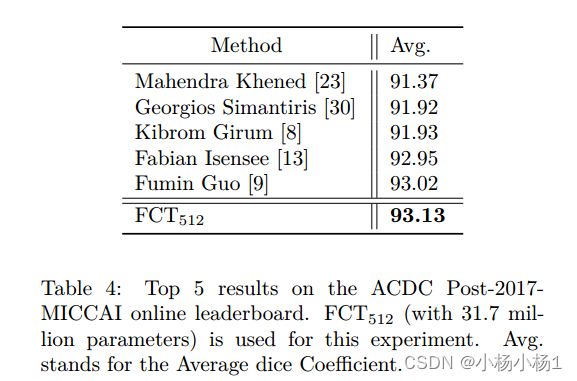
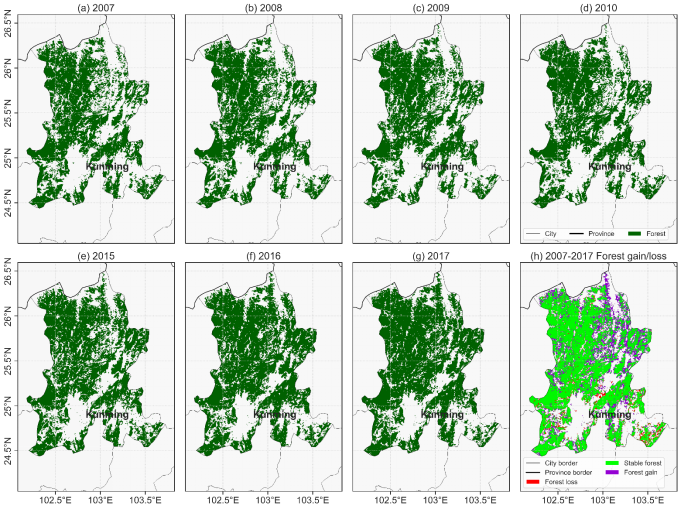
实验结果