文章目录
- 什么是栈
- 如何实现一个“栈”?
- 定长顺序栈
- 动长链式栈
- 栈的应用
- 栈在函数调用中的应用
- 栈在表达式求值中的应用
- 栈在括号匹配中的应用
- 总结
什么是栈
后进者先出,先进者后出,这就是典型的“栈”结构。
就像一摞叠在一起的盘子。我们平时放盘子的时候,都是从下往上一个一个放;取的时候,我们也是从上往下一个一个地依次取,不能从中间任意抽出。
从栈的操作特性上来看,栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。
如何实现一个“栈”?
定长顺序栈
栈主要包含两个操作,入栈和出栈,也就是在栈顶插入一个数据和从栈顶删除一个数据。
栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。我们这里给出一个用数组实现顺序栈的代码示例:
public class ArrayStack<T> {
/**
* 存放数据的数组
*/
private T[] tArray;
/**
* 数组的长度(定长)
*/
private int arrLength;
/**
* 栈的大小(动长)
*/
@Getter
private int size;
/**
* 构造函数
*/
public ArrayStack(int arrLength) {
this.arrLength = arrLength;
this.tArray = (T[]) new Object[arrLength];
this.size = 0;
}
/**
* 入栈,线程不安全
*/
public boolean push(T t) {
// 数组是否已满
if (size == arrLength) {
return false;
}
// 数组未满,将其放入数组中
tArray[size] = t;
size++;
return true;
}
/**
* 出栈,线程不安全
*/
public T pop() {
// 数组为空,返回null
if (size == 0) {
return null;
}
// 数组非空,返回栈尾
T t = tArray[size - 1];
size--;
return t;
}
}
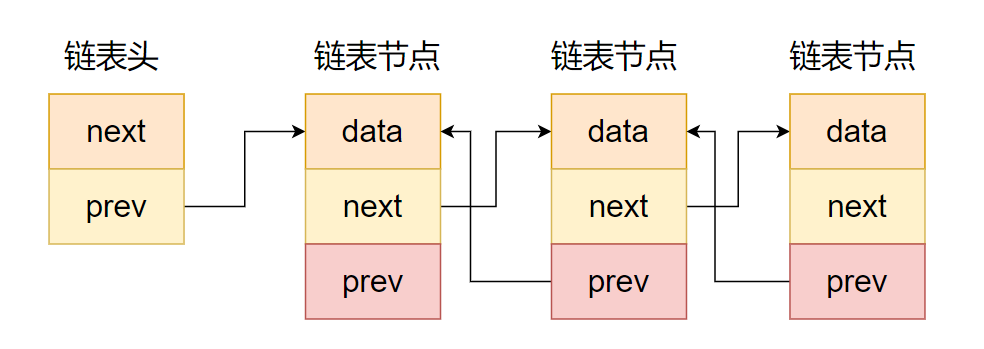
动长链式栈
public class LinkedStack<T> {
/**
* 栈顶节点
*/
private StackNode<T> topNode = null;
/**
* 入栈,线程不安全
*/
public boolean push(T t) {
// 定义新节点
StackNode<T> newNode = new StackNode<>();
newNode.setData(t);
// 栈顶节点非空时,将原栈顶节点的上一节点设置为新节点
if (topNode != null) {
newNode.setPreNode(topNode);
}
// 将新节点设置为栈顶节点
topNode = newNode;
return true;
}
/**
* 出栈,线程不安全
*/
public T pop(){
// 栈已空
if (topNode == null) {
return null;
}
// 获取当前节点的数据
T data = topNode.getData();
// 取上一节点设置为栈顶
topNode = topNode.getPreNode();
return data;
}
@Data
private class StackNode<T> {
/**
* 数据
*/
private T data;
/**
* 上一个节点
*/
private StackNode<T> preNode = null;
}
}
不管是顺序栈还是链式栈,我们存储数据只需要一个大小为 n 的数组就够了。在入栈和出栈过程中,只需要一两个临时变量存储空间,所以空间复杂度是 O(1)。注意,这里存储数据需要一个大小为 n 的数组,并不是说空间复杂度就是 O(n)。因为,这 n 个空间是必须的,无法省掉。所以我们说空间复杂度的时候,是指除了原本的数据存储空间外,算法运行还需要额外的存储空间。
不管是顺序栈还是链式栈,入栈、出栈只涉及栈顶个别数据的操作,所以时间复杂度都是 O(1)。
栈的应用
栈在函数调用中的应用
栈作为一个比较基础的数据结构,应用场景还是蛮多的。其中,比较经典的一个应用场景就是函数调用栈。
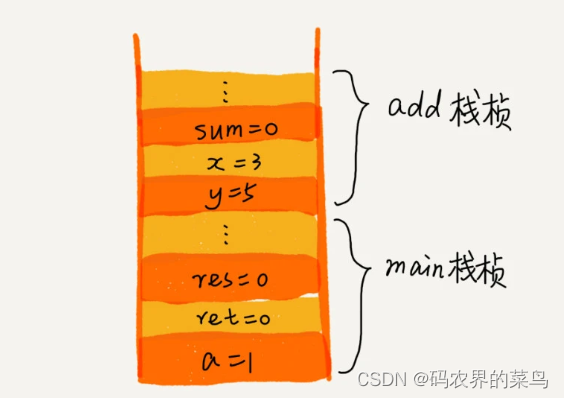
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。我们看下下面这段代码的栈图示:
public static void main(String[] args) {
int a = 1;
int ret = 0;
int res = 0;
ret = add(3, 5);
res = a + ret;
System.out.println(res);
}
public static int add(int x, int y) {
int sum = 0;
sum = x + y;
return sum;
}
从代码中我们可以看出,main() 函数调用了 add() 函数,获取计算结果,并且与临时变量 a 相加,最后打印 res 的值。为了让你清晰地看到这个过程对应的函数栈里出栈、入栈的操作,我画了一张图。图中显示的是,在执行到 add() 函数时,函数调用栈的情况。
栈在表达式求值中的应用
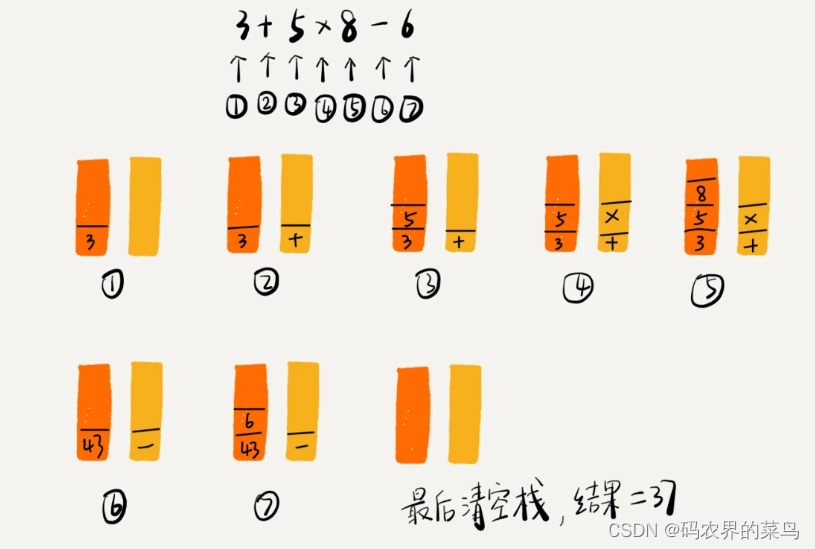
编译器通过两个栈来实现表达式求值。其中一个保存操作数的栈,另一个是保存运算符的栈。我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较。
如果比运算符栈顶元素的优先级高,就将当前运算符压入栈;如果比运算符栈顶元素的优先级低或者相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后进行计算,再把计算完的结果压入操作数栈,继续比较。
我将 3+5*8-6 这个表达式的计算过程画成了一张图,你可以结合图来理解我刚讲的计算过程。
栈在括号匹配中的应用
我们假设表达式中只包含三种括号,圆括号 ()、方括号[]和花括号{},并且它们可以任意嵌套。比如,{[] ()[{}]}或[{()}([])]等都为合法格式,而{[}()]或[({)]为不合法的格式。那我现在给你一个包含三种括号的表达式字符串,如何检查它是否合法呢?
这里也可以用栈来解决。我们用栈来保存未匹配的左括号,从左到右依次扫描字符串。当扫描到左括号时,则将其压入栈中;当扫描到右括号时,从栈顶取出一个左括号。如果能够匹配,比如“(”跟“)”匹配,“[”跟“]”匹配,“{”跟“}”匹配,则继续扫描剩下的字符串。如果扫描的过程中,遇到不能配对的右括号,或者栈中没有数据,则说明为非法格式。
当所有的括号都扫描完成之后,如果栈为空,则说明字符串为合法格式;否则,说明有未匹配的左括号,为非法格式。
总结
栈是一种操作受限的数据结构,只支持入栈和出栈操作。后进先出是它最大的特点。栈既可以通过数组实现,也可以通过链表来实现。不管基于数组还是链表,入栈、出栈的时间复杂度都为 O(1)。




![[管理与领导-6]:新任管理第1课:管理转身--从技术业务走向管理,角色的转变](https://img-blog.csdnimg.cn/img_convert/364b007896c005ee6aea73fa07841108.jpeg)