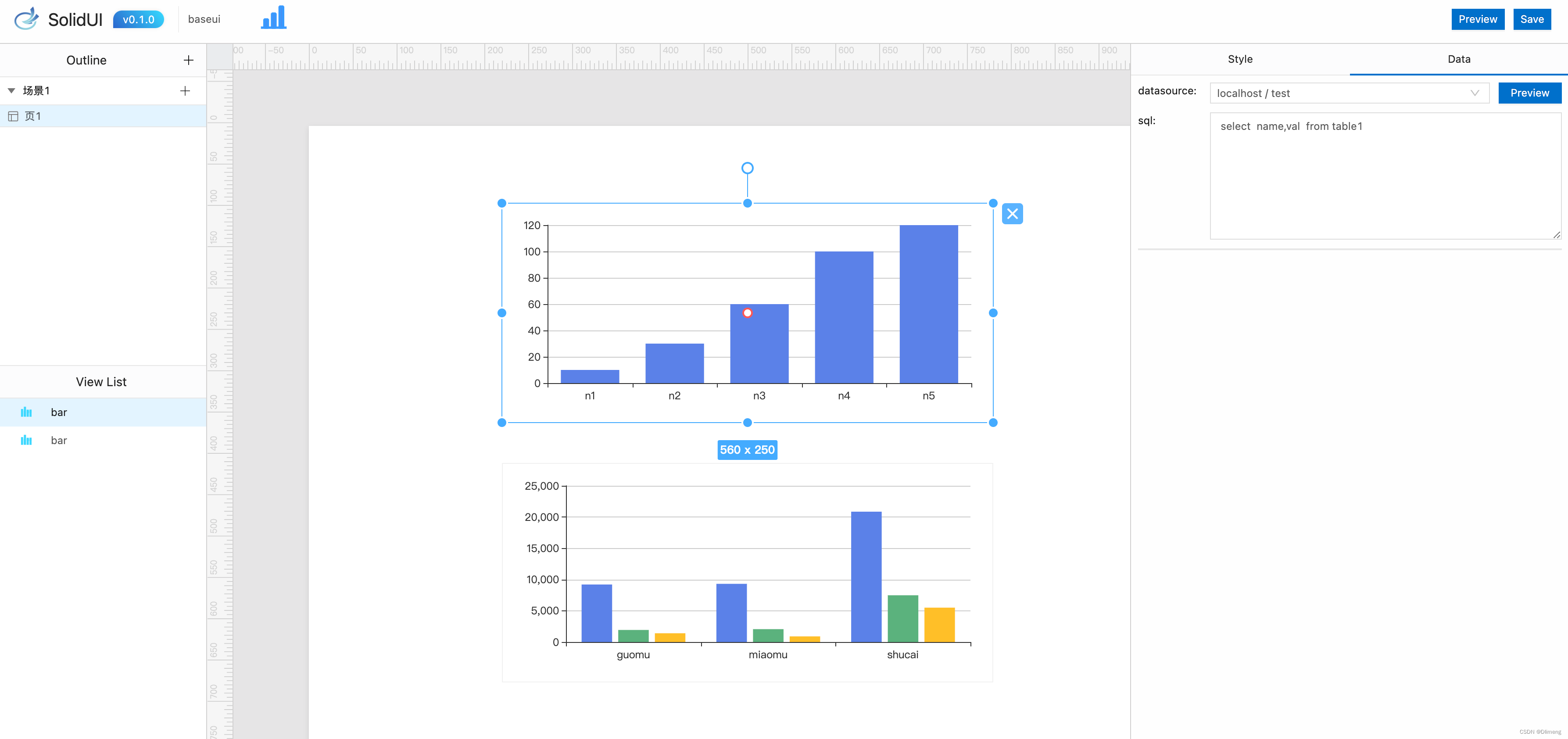
在今天的文章中,我来详细描述一下 Elasticsearch 文档的版本控制以及如何更新文档。你也可以阅读我之前的文章 “Elasticsearch:深刻理解文档中的 verision 及乐观并发控制”。
版本控制
我们知道 Elasticsearch 的每个文档都有一个相对应的版本。这个版本号在我们成功写入到 Elasticsearch 之后,就已经生成了:
PUT twitter/_doc/1
{
"content": "This is Xiaoguo from Elastic"
}上面命令返回如下的结果:
{
"_index": "twitter",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}从上面的输出中来看,它的 _version 值为 1。当我们更新该文档后:
PUT twitter/_doc/1
{
"content": "This is Xiaoguo, Liu from Elastic"
}我们看到如下的返回结果:
{
"_index": "twitter",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}上面的结果显示 _version 的值为 2。也就是说,当我们更新一次文档后,版本号就自动增加 1。
当我们在 Elasticsearch 中索引文档时,它会跟踪它们的版本。 重要的是要记住,Elasticsearch 的版本控制非常简单,并且不提供文档修改的完整历史记录。
它是如何工作的?
Elasticsearch 仅存储文档的最新版本。 因此,你无法返回过去并查看文档的先前版本。Elasticsearch 将名为 _version 的自定义字段存储为索引文档的元数据(metadata)。 该字段的初始值为 1,每次更新或删除文档时该字段都会增加 1。
删除文档时,Elasticsearch 默认保留版本号 60 秒。 如果在该时间范围内索引具有相同 ID 的新文档,版本号将会增加。 否则,它将被重置为 1。
当你使用文档 ID 获取文档时,您你在响应中看到此元数据字段。 但是,对于搜索请求,该字段不会自动包含在结果中。 但不用担心,如果需要,我们可以指示 Elasticsearch 包含它。
这种类型的版本控制称为 “内部版本控制”,但你还可以使用 “外部版本控制”。
外部版本控制专为你希望将文档版本保留在 Elasticsearch 外部(例如外部数据库中)的情况而设计。 例如,你可以使用关系数据库作为主要数据存储,并将数据索引到 Elasticsearch 中以进行搜索。 外部版本控制允许你指定 Elasticsearch 应存储的版本和版本类型。 你给出的版本必须是正整数。
那么,这个版本控制的目的是什么?
嗯,它实际上允许你跟踪文档被修改的次数,尽管这在大多数情况下可能不是特别有用。
老实说,“版本控制” 这个术语不再被普遍使用,或者不应该被普遍使用。 它曾经是一种乐观并发控制的技术。 现在,最好的做法是使用 primary 单词和 sequence number,而不是这种类型的版本控制。 另一方面,如果你有特定需求,_version 元数据字段仍然可用,尽管它的实用性受到极大限制。
那么,我为什么首先提出它呢?
你可能会以某种方式遇到此字段,特别是如果你正在使用使用旧版本 Elasticsearch 且需要乐观锁定的应用程序。
乐观并发控制
乐观并发控制是一种防止旧版本文档覆盖较新版本的技术。 这在处理无序到达的写入操作等场景时非常有用。
由于 Elasticsearch 是一个涉及网络的分布式系统,因此这种情况是可能的。 让我们看一个简单的例子来帮助你更好地掌握它。
想象一下,你正在使用电子商务平台,并且访问者将商品添加到购物车并完成结账流程。 现在,应用程序从 Elasticsearch 检索产品信息。 然而,在此期间,另一个访问者也完成了同一产品的结帐过程,并且 Web 服务器上的单独线程也检索产品信息。
此时,两个线程都返回了相同的产品信息。 第一个线程从产品的 in_stock 字段中减去一个,并使用 Elasticsearch API 更新文档。 这就是事情变得棘手的地方。 第二个线程尝试相同的操作,假设它保存 in_stock 字段的最新值。 然而,它没有意识到自最初检索产品信息以来该值已从 6 更新为 5。
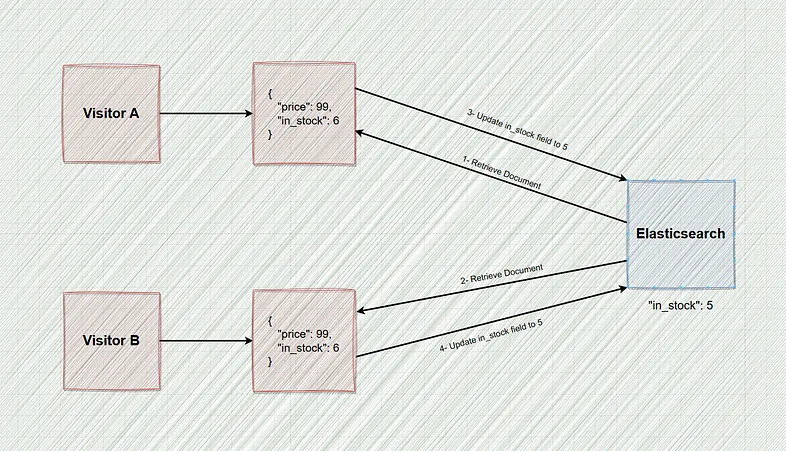
现在,根据应用程序的不同,其后果可能完全不同。 在这种情况下,这可能意味着我们最终会出售实际上缺货的商品,这无疑会导致令人失望的客户体验。
那么,我们以后怎样才能避免类似的错误呢?
为了避免将来出现此类错误,我们必须确保如果文档自检索以来已被修改,我们的更新就会失败。 这就是版本控制发挥作用的地方,或者至少它曾经是解决方案。
过去,我们会使用文档检索附带的 _version 字段,并将其作为发送更新请求时的查询参数。
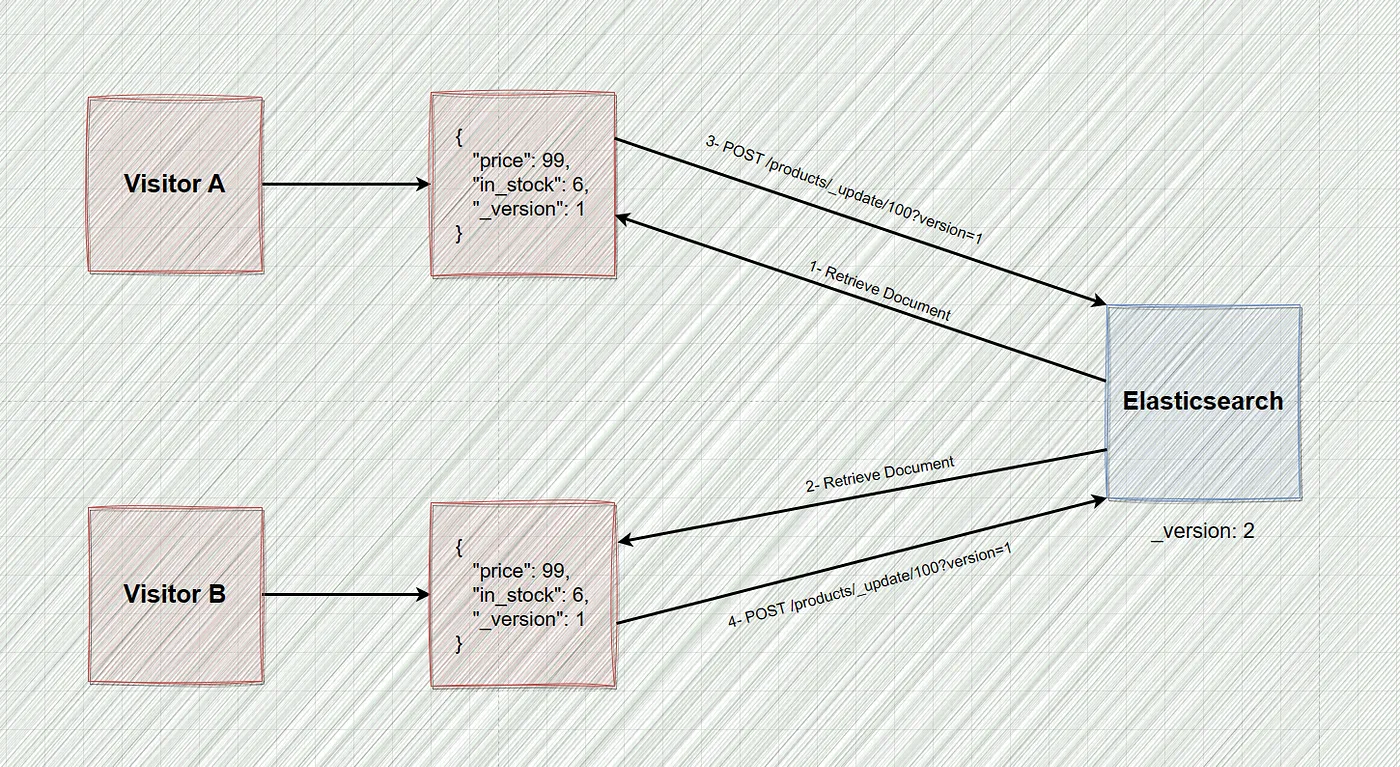
如果提供的版本与索引中存储的版本不匹配,更新操作将会失败。 虽然这种策略总体上运作良好,但当事情没有按计划进行时,它就会出现一些缺点。
这就是 primary terms 和 sequence nunber 用来解决这些问题的地方。 我们现在使用主要术语和序列号,而不是以前的方法。
让我们看一个例子。
当我们检索产品时,当前的 primary term 和序列号将包含在结果中。 要更新文档,我们可以获取这些值并将它们包含在 POST 请求中。 我们使用 “if_seq_no” 和 “if_primary_term” 参数来实现这一点。 然后,Elasticsearch 使用这两个值来确保我们不会意外覆盖自检索以来已修改的文档。 如果出现这种情况,操作会失败,我们可以重试该过程。
现在,让我们去 Kibana 见证这一过程。
首先,我们检索一个文档来展示结果中的 primary term 和 sequence number。
GET /products/_doc/100
请注意结果中的 “_primary_term” 和 “_seq_no” 字段。 如果你遵循的话,如果你看到的值有所不同,请不要担心。
我准备了另一个查询,它只是将 in_stock 字段更新为任意数字。
POST /products/_doc/100?if_primary_term=X&if_seq_no=X
{
"doc": {
"in_stock": 123
}
}正如你所看到的,我添加了两个查询参数,但还没有给它们一个合适的值。 让我们从查询结果中获取主要术语和序列号并填写它们。
首先,我们将参数 “if_primary_term” 设置为我们从结果中获得的主要项的值,并将第二个参数 “if_seq_no” 设置为结果中 “_seq_no” 的值,即 9。
这意味着,仅当文档的主要术语和序列号与提供的值匹配时,才会更新文档。
POST /products/_doc/100?if_primary_term=1&if_seq_no=9
{
"doc": {
"in_stock": 123
}
}
正如我们在结果中看到的,文档已更新,新的序列号现在为 11。让我们再次运行查询而不更新序列号,只是为了证明这不起作用。

这次,我们遇到了一个错误,表明 primary term 和 sequence number 组合不匹配。 在这种情况下,我们是更新文档的人,但在你之前看到的场景中也可能会发生相同的情况。
通过采用这种技术,我们可以有效地避免文档在检索时更新的并发问题。
那么,当我们遇到这个错误时,我们该怎么办呢?
那么,当以这种方式更新文档时,你需要在应用程序中处理它。 这意味着你应该再次检索文档并在重试更新时使用新的 primary term 和 sequence number,并且不要忘记重新计算任何值,因为字段值可能已更改。
这就是你如何使用 Elasticsearch 实现乐观并发控制。 根据你的具体用例,这可能并不总是必要的,但如果您有可能同时更新同一文档的进程或线程,那么绝对值得考虑这种方法。