查看和指定GPU服务器显卡
- 1.查看显卡
- 2.间隔查看GPU使用情况
- 3.查看当前显卡信息
- 4. 使用os指定使用的显卡
1.查看显卡
nvidia-smi
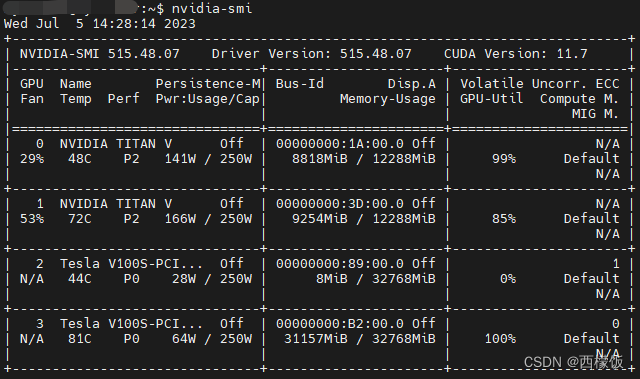
GPU:GPU 编号;与实际编号不一定一致
Name:GPU 型号;
Persistence-M:持续模式的状态。持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态;
Fan:风扇转速,从0到100%之间变动;
Temp:温度,单位是摄氏度;
Perf:性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能(即 GPU 未工作时为P0,达到最大工作限度时为P12)。
Pwr:Usage/Cap:能耗;
Memory Usage:显存使用率;
Bus-Id:涉及GPU总线的东西
Disp.A:Display Active,表示GPU的显示是否初始化;
Volatile GPU-Util:浮动的GPU利用率;
Uncorr. ECC:Error Correcting Code,错误检查与纠正;
Compute M:compute mode,计算模式
2.间隔查看GPU使用情况
间隔10s刷新信息
watch -n 10 nvidia-smi
间隔5s刷新信息
watch -n 5 nvidia-smi
3.查看当前显卡信息
通过nvidia-smi查看的显卡排序不一定是正确的。可能使用到Torch的以下函数确定当前显卡。
torch.cuda.is_available() # 判断GPU是否可用
torch.cuda.device_count() # 查看可用GPU数量
torch.cuda.current_device() # 当前设备的索引,从0开始
torch.cuda.get_device_name(0) # 返回GPU名字
根据上面的信息,我这里有4个GPU。
>>> import torch
>>> torch.cuda.device_count()
4
>>> torch.cuda.current_device()
0
>>> torch.cuda.get_device_name(0)
'NVIDIA TITAN V'
>>> torch.cuda.get_device_name(1)
'NVIDIA TITAN V'
>>> torch.cuda.get_device_name(2)
'Tesla V100S-PCIE-32GB'
>>> torch.cuda.get_device_name(3)
'Tesla V100S-PCIE-32GB'
4. 使用os指定使用的显卡
上面查询到4个可用GPU信息,但是我们想指定在某张或者某几张显卡上训练网络。
(1)使用os.environ指定要使用的显卡:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '2,3'
把os.environ[‘CUDA_VISIBLE_DEVICES’]='2,3’放在所有访问GPU的代码之前,否则设置不生效。
假设原来有4张卡,编号为0的是主卡,现在编号为2的是主卡,且每张显卡的默认标号为[0,1]。
(2)将网络放到指定GPU上训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Model()
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model, device_ids=[0,1])
model.to(device)
device_ids=[0,1]里面的0指的是4张显卡里面的第三张,1表示第四张。