本章主要讲解机器学习的基础知识,有关一些专业术语的定义与解释。
文章目录
- 2.1 经验误差与过拟合
- 2.2 评估方法
- 2.2.1 留出法
- 2.2.2 交叉验证法
- 2.2.3 自助法
- 2.2.4 调参与最终模型
- 2.3 性能度量
- 2.3.1 错误率与精度
- 2.3.2 查准率、查全率与F1
- 2.3.3 ROC与AUC
2.1 经验误差与过拟合
错误率:分类错误的样本数占样本总数。
精度:1-错误率
误差:学习器的实际预测输出与样本的真实输出之间的差异成为“误差”。
学习器在训练集上的误差称为“训练误差”或“经验误差”,在新样本上的误差称为“泛化误差”
过拟合:学习器把训练样本学的太好,从而把训练样本本身的一些性质特点当作了所有泛化样本都会存在的一般性质,则会产生过拟合,导致泛化性能下降。
过拟合是机器学习面临的关键障碍。
欠拟合:与过拟合相对的是欠拟合,指对样本的一般性质都没学好。
多 项 式 时 间 ( 英 语 : P o l y n o m i a l t i m e ) 在 计 算 复 杂 度 理 论 中 , 指 的 是 一 个 问 题 的 计 算 时 间 m ( n ) 不 大 于 问 题 大 小 n 的 多 项 式 倍 数 。 任 何 抽 象 机 器 都 拥 有 一 复 杂 度 类 , 此 类 包 括 可 于 此 机 器 以 多 项 式 时 间 求 解 的 问 题 。 多项式时间(英语:Polynomial time)在计算复杂度理论中,\newline指的是一个问题的计算时间{\displaystyle m(n)}不大于问题大小{\displaystyle n}的多项式倍数。\newline任何抽象机器都拥有一复杂度类,\newline此类包括可于此机器以多项式时间求解的问题。 多项式时间(英语:Polynomialtime)在计算复杂度理论中,指的是一个问题的计算时间m(n)不大于问题大小n的多项式倍数。任何抽象机器都拥有一复杂度类,此类包括可于此机器以多项式时间求解的问题。
(1)P( Polynomial )问题:如果一个问题可以找到一个能在多项式时间里解决它的算法,那么这个问题就属于P问题。
(2)NP( Non-Deterministic Polynomial )问题: NP问题不是非P类问题,是多项式复杂程度的非确定性问题。是指可以在多项式的时间里验证一个解的问题。NP问题的另一个定义是,可以在多项式的时间里猜出一个解的问题。
我们假设可以彻底避免过拟合现象,则经验误差最小化就能取得最优解,这就意味着我们构造性地证明了“P=NP”;因此,只要相信 “ P ≠ N P ” “P \ne NP” “P=NP”,过拟合就不可避免。
2.2 评估方法
2.2.1 留出法
将数据集划分为两个互斥的集合,其中一个集合作为训练集,另一个集合作为测试集,训练集用于训练,测试集用于评估测试误差,作为对泛化误差的估计。
2.2.2 交叉验证法
将数据集划分为k个大小相似的互斥子集,每个子集都尽可能保持数据分布的一致性,即通过分层采样得到。
然后,每次用k-1个子集作为训练集,用余下的1个子集作为测试集,这样可以重复k次遍历k个不同的方案,最终返回k个测试结果的均值。这个验证法也称为“k折交叉验证”。
若共有m个样本,并另k=m,则得到了交叉验证法的一个特例:留一法。
2.2.3 自助法
我们希望评估D训练出的模型,但在留出法和交叉验证法中保留了一部分样本进行测试,因此实际评估模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致估计偏差。
给定m个样本的数据集,采样产生数据集D’:每次随机产从D中挑选一个样本,将其拷贝放入D’,然后再将该样本放回初始数据集D中,是的该样本再下次采样时仍有可能被采到;这个过程重复m次后,就得到了包含m个样本的数据集D’,显然,D中有一部分样本会在D’中多次出现,而另一部分样本不出现。
样本在m次采样中始终不被采到的概率是
(
1
−
1
m
)
m
(1-\frac{1}{m})^m
(1−m1)m,取极限得到
lim
m
→
∞
(
1
−
1
m
)
m
=
1
e
≈
0.368
\lim\limits_{m\rightarrow\infty}(1-\frac{1}{m})^m=\frac{1}{e}\approx0.368
m→∞lim(1−m1)m=e1≈0.368
所以在D中大约有36.8%的样本没有出现在D’中,所以我们可以用D’作为训练集,D/D’作为测试集。这样,实际评估与期望评估的模型都有m个样本,而我们仍有约三分之一的数据没在训练集中出现,方便用于测试。这样的测试结果,亦称“包外估计”。
2.2.4 调参与最终模型
众所周知,一个好的模型必然是通过不断调整参数而找出最优模型。
2.3 性能度量
对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量。
对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果,这意味着模型好坏时相对的,模型的好坏不取决于算法和数据,而取决于任务需求。
回归任务最常用的性能度量是“均方误差”
E
(
f
;
D
)
=
1
m
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
E(f;D)=\frac{1}{m}\sum_{i=1}^{m}(f(x_i)-y_i)^2
E(f;D)=m1i=1∑m(f(xi)−yi)2
其中
y
i
y_i
yi为
x
i
x_i
xi的真实标记,
f
(
x
i
)
f(x_i)
f(xi)为
x
i
x_i
xi的预测值。
更一般的,对于数据分布
D
D
D和概率密度
p
(
⋅
)
p(·)
p(⋅),均方误差可描述为
E
(
f
;
D
)
=
∫
x
→
D
(
f
(
x
)
−
y
)
2
p
(
x
)
d
x
E(f;D)=\int_{x\rightarrow D}(f(x)-y)^2p(x)dx
E(f;D)=∫x→D(f(x)−y)2p(x)dx
下面介绍分类任务中常用的性能度量。
2.3.1 错误率与精度
在本章开头给出错误率与精度的定义,不再赘述
更一般的,对于数据分布D和概率密度p(·),错误率与精度可分别描述:
E
(
f
;
D
)
=
∫
x
→
D
Ⅱ
(
f
(
x
)
≠
y
)
p
(
x
)
d
x
E(f;D)=\int_{x\rightarrow D}Ⅱ(f(x)\ne y)p(x)dx
E(f;D)=∫x→DⅡ(f(x)=y)p(x)dx
其中Ⅱ(·)是指示函数,在·为真和假时分别取直1和0。
a
c
c
(
f
;
D
)
=
∫
x
→
D
Ⅱ
(
f
(
x
)
=
y
)
p
(
x
)
d
x
=
1
−
E
(
f
;
D
)
acc(f;D)=\int_{x\rightarrow D}Ⅱ(f(x)=y)p(x)dx\newline=1-E(f;D)
acc(f;D)=∫x→DⅡ(f(x)=y)p(x)dx=1−E(f;D)
2.3.2 查准率、查全率与F1
假设对于二分类问题,根据情况划分为真正例TP,假正例FP,真反例TN,假反例FN。
真正例即预测结果和真实情况都为真
真反例即预测结果和真实情况都为假
假正例即预测结果为真,真实情况为假
假反例即预测结果为假,真实情况为真
查准率P和查全率R定义为:
P
=
T
P
T
P
+
F
P
P=\frac{TP}{TP+FP}
P=TP+FPTP
R
=
T
P
T
P
+
F
N
R=\frac{TP}{TP+FN}
R=TP+FNTP
以查全率和查准率为xy周给出坐标图
借用该博客的图片进行理解:
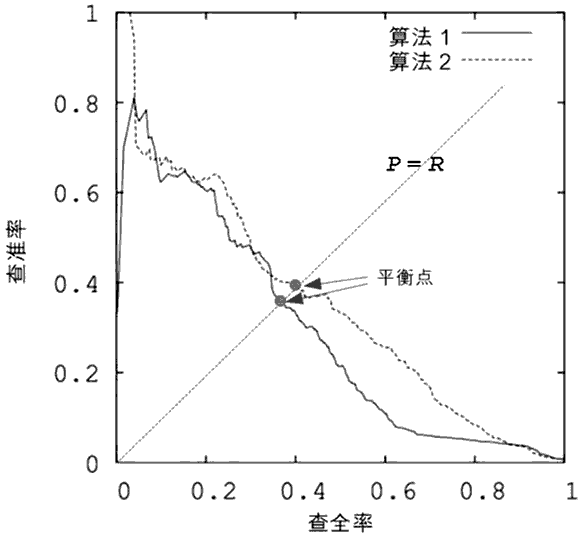
在比较时,若一个学习器的P-R曲线被另一个学习器的曲线完全保住,则可断言后者性能优于前者。其次,在不好比较时,平衡点可以作为一个度量。
上述比较方法过于简化,因此引入F1度量:
F
1
=
2
∗
P
∗
R
P
+
R
=
2
∗
T
P
样
例
总
数
+
T
P
−
T
N
F1=\frac{2*P*R}{P+R}=\frac{2*TP}{样例总数+TP-TN}
F1=P+R2∗P∗R=样例总数+TP−TN2∗TP
F1是基于查全率和查准率的调和平均定义的,而
F
β
F_\beta
Fβ则是加权调和平均。
因为我们在实际应用中,对查准率和查全率的侧重程度有所不同,所以常用加权调和平均。
F
β
=
(
1
+
β
2
)
∗
P
∗
R
(
β
2
∗
P
)
+
R
F_\beta =\frac{(1+\beta^2)*P*R}{(\beta^2*P)+R}
Fβ=(β2∗P)+R(1+β2)∗P∗R
其
中
β
>
0
度
量
了
查
全
率
对
查
准
率
的
相
对
重
要
性
,
当
b
e
t
a
=
1
退
化
为
标
准
的
F
1
,
β
>
1
时
查
全
率
有
更
大
影
响
,
β
<
1
时
,
查
准
率
有
更
大
影
响
其中\beta>0度量了查全率对查准率的相对重要性,当beta=1退化为标准的F1,\beta>1时查全率有更大影响,\beta<1时,查准率有更大影响
其中β>0度量了查全率对查准率的相对重要性,当beta=1退化为标准的F1,β>1时查全率有更大影响,β<1时,查准率有更大影响。
当我们用一个算法进行多个模型的测试,得到n个二分类结果,但我们希望对算法也就是这n个结果进行综合考量查准率和查全率。
一种直接的做法是在各矩阵上分别计算出查准率和查全率,再计算出平均值,得到了宏查全率,宏查准率和相应的宏F1。
上述是计算出各查全率和查准率再求平均值,我们也可以先求各矩阵中的对应元素进行平均,然后再求出查全率和查准率以及F1,这时我们称为微查全率、微查准率、微F1。