介绍
TDengine™ 是一种开源的云原生时序数据库(Time Series Database,TSDB),专为物联网(IoT)、连接汽车和工业物联网进行了优化。它能够高效地实时摄取、处理和监控一天内由数十亿个传感器和数据收集器产生的PB级别的数据。
许多用户将由物联网设备、汽车或 IT 基础设施生成的海量数据实时存储到 TDengine 中,并使用标准的 SQL 命令从 TDengine 中查询数据。TDengine 支持过滤、分组、窗口、连接和许多聚合函数以查询数据,帮助用户根据其目的查询数据。
许多用户也希望更深入地了解现有数据。例如,根据当前趋势,未来将会发生什么情况?随着 AI 时代的到来,最近出现了许多新技术或方法,例如新的机器学习和深度学习算法。那么如何使用机器学习和深度学习算法针对存储在 TDengine 的数据预测未来趋势呢?
幸运的是,TDengine 支持多种流行的编程语言连接器,如 Java、Python、Go、Rust、C#、NodeJS 等,用户可以使用他们喜欢的语言连接器访问 TDengine。这些连接器提供符合规范的接口,使连接器易于与其他软件或框架集成。
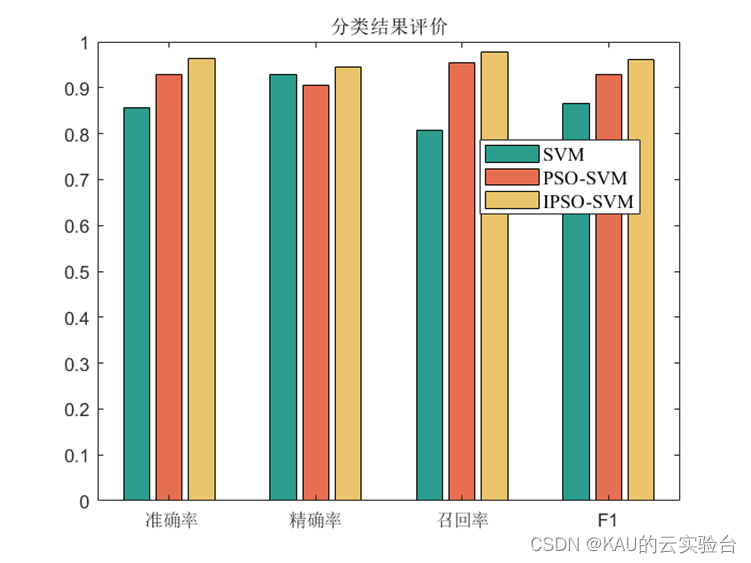
本文介绍如何使用存储在 TDengine 中的现有数据来预测未来数据。我们将模拟一些测试数据以反映真实的电力系统,并演示如何使用 TDengine 和一些 Python 库来预测未来一年的数据。
假设用户是一个电力系统公司,用户每天从电站仪表收集用电量数据,并将其存储在 TDengine 集群中。现在用户想要预测电力消耗将会如何发展,并购买更多设备来支持它。
随着经济增长,每年用电成一定比例上涨。另外考虑到季节变化,电力消耗量会有所不同。这个城市位于北半球,所以许多家庭在夏天会使用更多的电力。我们模拟数据来反映这些假定。
源代码托管在 https://github.com/sangshuduo/td-forecasting。
演示
步骤1:部署 TDengine 并在您的系统上运行 TDengine 服务器。
请参阅官方文档https://docs.tdengine.com/get-started/了解详细说明。
步骤2:克隆源代码
git clone https://github.com/sangshuduo/td-forecasting步骤3:安装所需的Python软件包
# if you are using Ubuntu 20.04 Linux
sudo apt install python3-pyqt5
# 如果 PyQT5 运行失败,可能需要安装
sudo apt-get install libxcb-xinerama0
python3 -m pip install -r requirements.txt请注意,Python 的最小版本为 3.8。
步骤4:模拟一些数据
python3 mockdata.py步骤5:预测明年的数据
python3 forecast.py输出结果
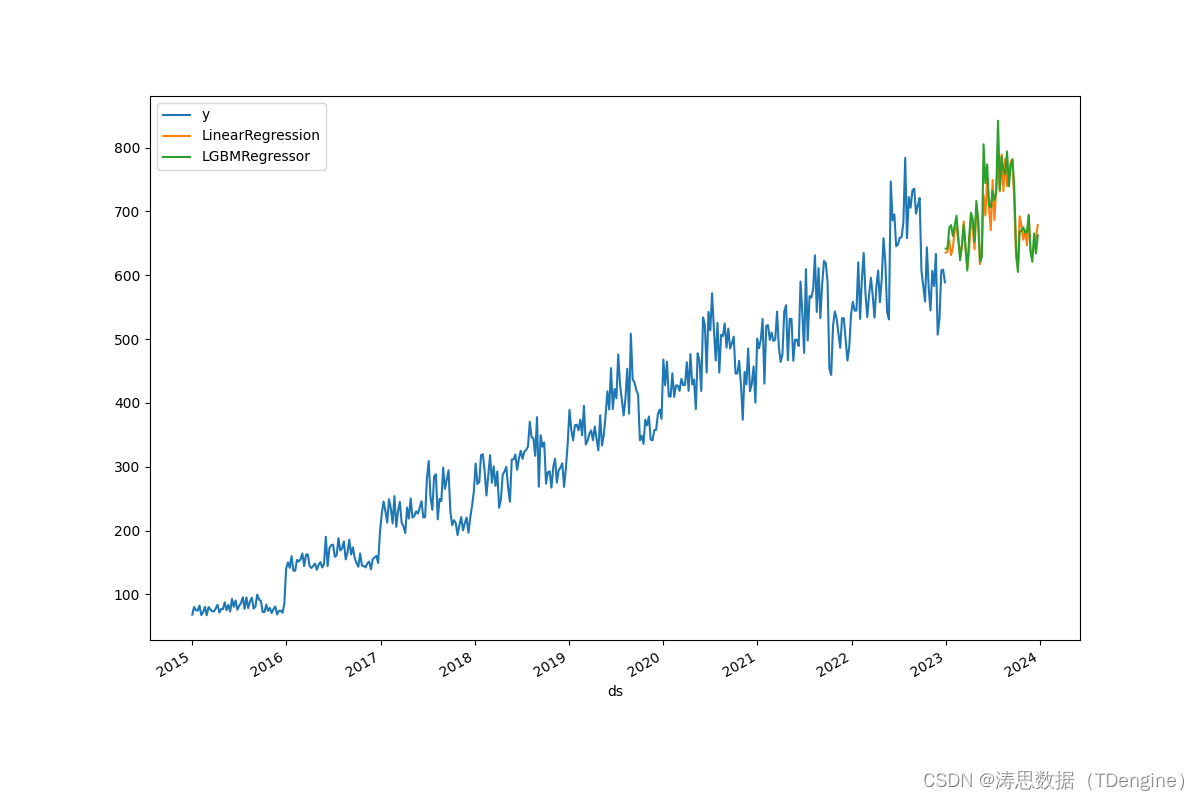
如果一切顺利,图像将显示如下。
工作原理介绍
mockdata.py
...
def insert_rec_per_month(conn, db_name, table_name, year, month):
increment = (year - 2014) * 1.1
base = int(10 * increment)
if month < 10 and month > 5:
factor = 10
else:
factor = 8
for day in range(1, monthrange(year, month)[1] + 1):
num = base * randint(5, factor) + randint(0, factor)
sql = f"INSERT INTO {db_name}.{table_name} VALUES ('{year}-{month}-{day} 00:00:00.000', {num})"
try:
conn.execute(sql)
except Exception as e:
print(f"command: {sql}")
print(e)
...这个文件的核心功能是模拟随机数据,并进行一些调整以实现假设。
forecast.py
这个文件实现了预测功能,以下为实现过程详解:
步骤 1:导入预测需要的 Python 模块
import argparse
import lightgbm as lgb
import matplotlib.pyplot as plt
import mlforecast
import pandas as pd
from mlforecast.target_transforms import Differences
from sklearn.linear_model import LinearRegression
from sqlalchemy import create_engine, text
...下面我们解释一下它们是什么,以及它们的作用:
• Lightgbm 是一个 Python 模块,支持 LightGBM 算法,它是一个使用基于树的学习算法的梯度提升框架。
• Matplotlib 是最流行的 Python 模块之一,用于可视化。
• Mlforecast 是一个框架,用于使用机器学习模型执行时间序列预测。
• Pandas 是支持数据操作的最流行的模块。
• Sklearn 是一个支持流行的数据科学/机器学习算法的模块。
• SQLAlchemy 是 Python SQL 工具包和对象关系映射器,它为应用程序开发人员提供了完整的 SQL 功能和灵活性。
步骤 2:连接到 TDengine 并查询数据
...
engine = create_engine("taos://root:taosdata@localhost:6030/power")
conn = engine.connect()
print("Connected to the TDengine ...")
df = pd.read_sql(
text("select _wstart as ds, avg(num) as y from power.meters interval(1w)"), conn
)
conn.close()
...TDengine Python 连接器提供符合 Python 数据库 API 规范 v2.0(PEP 249)的接口。DBAPI 是“Python 数据库 API 规范”的缩写。这是 Python 中广泛使用的规范,用于定义所有数据库连接包的常用用法模式。DBAPI 是一个“低级别”API,通常是 Python 应用程序中用于与数据库交互的最低级别系统。SQLAlchemy 的方言系统是围绕DBAPI 的操作构建的,提供适用于特定数据库引擎的特定 DBAPI 的各个方言类。
我们可以使用 SQLAlchemy 连接 TDengine集群,并使用 Pandas 将数据查询转换成数据帧格式。
在这里,我们假设用户关心的是周平均用电量,而不是每天的用电量,以减少异常值。我们可以使用 AVG() 函数和 INTERVAL(1w)子句命令从 TDengine 集群中查询数据。
稍后我们将以数据帧格式操纵数据。
步骤 3:预测
...
df.insert(0, column="unique_id", value="unique_id")
print("Forecasting ...")
forecast = mlforecast.MLForecast(
models=[LinearRegression(), lgb.LGBMRegressor()],
freq="W",
lags=[52],
target_transforms=[Differences([52])],
)
forecast.fit(df)
predicts = forecast.predict(52)
pd.concat([df, predicts]).set_index("ds").plot(figsize=(12, 8))
...通过 mlforecast 模块的特性,我们可以设定一些参数进行预测。在这里,我们使用线性回归算法和 LightGBM 算法来进行预测并在同一图中显示它们的结果,以便可视化不同算法的效果。
步骤 4: Show up or dump to file
...
if args.dump:
plt.savefig(args.dump)
else:
plt.show()Python 代码提供了一个参数"--dump",让用户可以决定将结果转储到图片中进行后续处理,或者立即在屏幕上显示结果。
以上步骤在 Ubuntu 20.04、Ubuntu 22.04、Windows 10 和 macOS 环境经过验证。
总结
这样一来,我们现在就拥有了一个非常简单的程序,演示了如何使用存储在 TDengine 中的电力系统历史数据的电表数值来预测未来的电力消耗数值。