一.需求分析
面向HR的人岗匹配功能,帮助HR高效挑选简历。模型能够根据给出的不同岗位需求,在简历库中挑选出与岗位需求最匹配的几个简历推荐给HR。岗位的常见需求包括:年龄、学历、工作年限三方面。简历也具有以下几个特征:应聘人的年龄、学历、毕业院校、工作年限、目标职位。模型要根据岗位的需求和简历的特征做出匹配和推荐。
二.算法选择
问题本质上属于推荐问题,常见的推荐系统包括以下三类:协同过滤推荐、基于内容的推荐以及混合推荐。传统的推荐算法虽然可以解决大部分信息过滤的问题,但是无法解决数据稀疏、冷启动、重复推荐等问题。[1] 本项目作者观察到深度强化学习可以达到更好的简历推荐效果。
三.深度强化学习
1.强化学习
强化学习的依据来自马尔可夫决策模型。它的基本思想就是驱动一个智能体代理在环境中采取行动以最大限度地提高其累积回报。智能体代理会受到对不良行为的惩罚和对良好行为的奖励的激励。
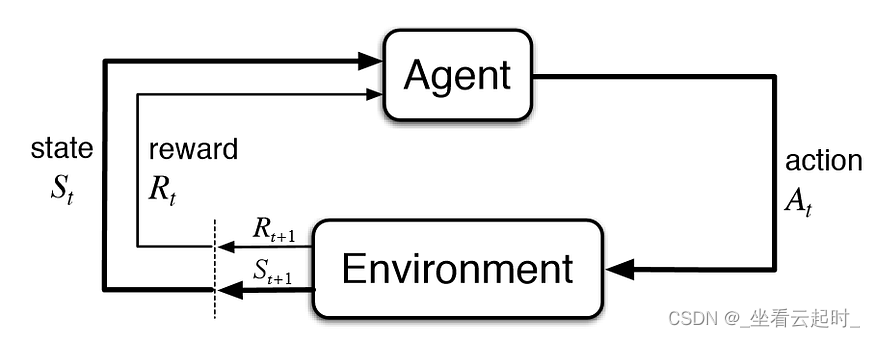
图1 马尔可夫决策模型
我们让智能体代理从一个初始环境开始。它还没有任何相关的奖励,但它有一个状态(S_t)。
然后,对于每次迭代,代理获取当前状态(S_t),选择最佳(基于模型预测)动作(A_t),并在环境中执行。随后,环境返回给定动作的奖励(R_t+1)、新状态(S_t+1)以及如果新状态是终端的信息。该过程重复进行,直到终止。
更多关于强化学习的细节可参看:
文献[2]:
https://gsurma.medium.com/cartpole-introduction-to-reinforcement-learning-ed0eb5b58288![]() https://gsurma.medium.com/cartpole-introduction-to-reinforcement-learning-ed0eb5b58288
https://gsurma.medium.com/cartpole-introduction-to-reinforcement-learning-ed0eb5b58288
文献[3]
https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-3-model-free-solutions-step-by-step-c4bbb2b72dcf![]() https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-3-model-free-solutions-step-by-step-c4bbb2b72dcf
https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-3-model-free-solutions-step-by-step-c4bbb2b72dcf
文献[4]
基于强化学习的智能机器人路径规划算法研究(附代码)_强化学习路径规划__坐看云起时_的博客-CSDN博客![]() https://blog.csdn.net/qq_53162179/article/details/128356575
https://blog.csdn.net/qq_53162179/article/details/128356575
强化学习中最常用的是Q-learning算法。
Q-learning算法使用状态-动作值的Q表(Qtable)。这个Q表为每一行代表一个状态,每一列代表一种动作。每个单元包含对应状态-动作对的估计Q值。
我们首先将所有Q值初始化为零。当代理与环境交互并获得反馈时,算法迭代地改进这些Q值,直到它们收敛到最优Q值。
关于Q-learning算法的细节理论可参看:
文献[5]
https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-4-q-learning-step-by-step-b65efb731d3e![]() https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-4-q-learning-step-by-step-b65efb731d3e
https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-4-q-learning-step-by-step-b65efb731d3e
以及文献[4]。
2.深度强化学习
该部分是本文的重点,深度强化学习共有三大类:(1)基于价值的深度Q网络:DQN等算法 (2)Policy Gradient算法 (3)Actor-Critic算法
本文项目的算法采用的是深度强化学习中的Deep Q Network(DQN),为什么会有DQN这种理论,还要从Q-learning算法说起,Q-learning中,采用了一种数据结构-Qtable来记录由状态和动作决定的Q值,但是现实场景中往往状态空间很大,动作空间也可能很大,组织一张庞大的Q表需要很大的系统开销。

图 2 Qtable
如果能用一个函数(Q-function),输入状态-动作对,就能输出对应的Q值,将一个状态映射到可以从该状态执行的所有操作的Q值,那么将会大大提高性能,如图:

图 3 Q-function
神经网络充当这个函数再适合不过了,DQN算法就是用深度学习中的神经网络来优化强化学习算法。

图4 深度Q网络(DQN)
该算法有两大精彩之处,一个叫经验回放(experience replay),另一个就是双神经网络:Q Network和Target Network。
2.1 经验回放
我们知道,训练一个AI决策模型需要不断采集该模型在环境中做出动作后的反馈数据,但是如何采集数据,采集哪些数据都会直接影响到该模型的训练效果。如果采集的数据是单一样本,每个样本以及对应的梯度都会有太大的方差,神经网络的权重不会收敛。那顺序地采集一批样本呢?也有缺陷,会导致“灾难性遗忘”,举个例子,如果一个大工厂地一个角落有一个机器人,这个机器人每次行走都是在这个小角落学习经验,采集的数据、学习的经验都是局限于这个小角落,这就类似于我们所说的顺序批量样本。这时如果把这个机器人拿到工厂另一个截然不同的角落,机器人会在新的角落开始学习经验,之前在原来角落学习到的经验很快就会彻底遗忘,这就是训练样本之间依赖性太强的原因。
如果我们采用一个池,每次装入采集的批量样本,当池中积累了一定量的样本之后,每次从池中随机采集一批样本,送入神经网络学习,这样每次学习的样本多样丰富,就会大大降低样本的依赖度,提高学习的效果。
就好像家长每次把孩子做过的错题收集在一起,让孩子重做,收集的错题类型越丰富,越利于孩子吸取不同题型的经验,从而更好的做新的习题。
2.2 双神经网络——Q-Network and Target Network
最原本的DQN算法只有单一的Q Network,Q Network负责每次在一个状态下预测每一个动作的Q值,然后智能体代理会根据不同行为的Q值大小做出决策,但是我们训练神经网络,每次要计算损失值来反向传播更新各神经元的权重,如果采用单一神经网络,会发生一个叫作“自举”的现象,每次迭代Q Network都会去逼近它自身,把它自己作为一个目标,去不断地追逐,因为权重发生变化,Q Network每次都被训练,拿训练之前的自己去追赶训练后的自己,永远都追不上,就好像自己举起自己,自己追逐自己的影子一样,给模型训练带来了很大的不稳定性。
如果我们再创造一个与它一模一样的神经网络,只是不像Q Network每次都更新权重,该网络间隔一定步数才更新权重(把Q Network的权重赋给它)被训练,这样的话用Q Network去追赶,就可以逐渐逼近,我们把这个神经网络称为“Target Network”。
举一个例子:一个人很穷,此时他的财富为M1,此时他对拥有100万的满足程度为A1,现在他突然有了80万,那么他对拥有100万的满足程度就会大大降低,他就会不满足于100万,想有1000万,那么每次他都会追逐更高的目标,永远不会满足。假如他有80万的时候,他达到满足的量还是一无所有时候对100万的满足程度,那么他只要再获得20万就会达到满足。Target Network就好比他一无所有时候对100万的满足程度,让他每次收入都能逼近满足。
2.3 DQN算法流程
初始时,状态被送入Q Network,神经网络预测出该状态下各个动作的Q值,根据ε-Greedy方法,有一定概率随机选择动作执行,否则选择Q值最大的动作执行。执行后,环境会给该动作一个反馈值reward,此时将该次行动的数据(本次状态(current state)、本次动作(action(i))、反馈值(reward)、下次状态(next state))送入经验回放池。重复上述过程,直到智能体代理到达终止状态时,更新Q网络权重,更新过程为:从经验回放池采一批样本,送入Q Network和Target Network,Q Network分别用这批样本各自的current state和action(i)计算该样本的Q值——QValue。Target Network分别用这批样本各自的next state和reward,计算出该样本的target value,target value的计算方法为:
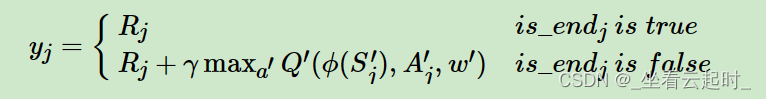
图5 Target Value的计算
Is_endj用来判断智能体是否到达最终状态,也就是终点,如果到达,target value值就是该状态下选择动作action(i)的反馈值,如果没到终点,则target value等于反馈值加上下一状态时各动作的target value中最大的值乘折扣因子,每个样本按以上方法计算。
得到Q Network的预测值和Target Network预测得到的target value之后,利用均方误差公式(MSE):

图6 均方误差公式
计算Q Network的损失值,然后利用梯度计算优化器,反向传播更新Q Network的权重。以下是整个模型的流程:

图7 DQN算法流程
文献[6]中详细描述了DQN算法,进行分步剖析,还有精彩插图:
文献[6]
https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-5-deep-q-networks-step-by-step-5a5317197f4b![]() https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-5-deep-q-networks-step-by-step-5a5317197f4b
https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-5-deep-q-networks-step-by-step-5a5317197f4b
四.人岗匹配模型建模
因为该功能是面向HR开发,那么我们可以把人岗匹配过程视为用一个岗位去匹配简历集中的简历,每匹配一份简历就视为一个动作,动作空间中动作的数量就是简历的数量,也就是说每一份简历对应着一种动作,按照简历特征与岗位特征的匹配度,给出反馈,匹配度越高的简历反馈值越好。在这个模型中,岗位可以视为智能体,每去匹配一份简历就是一个动作。
需要说的是状态:
初始状态是从简历集中随机抽取一份简历作为初始状态,模型训练过程中,该次决策做出的动作作为下一状态,也就是说,每一个状态实际上是一份简历。
- 状态空间S:简历集合
- 动作空间A:简历集合
- 招聘方反馈R:根据简历与岗位特征的匹配程度,给出反馈
- 折扣因子γ:表示不同时间回报的折扣
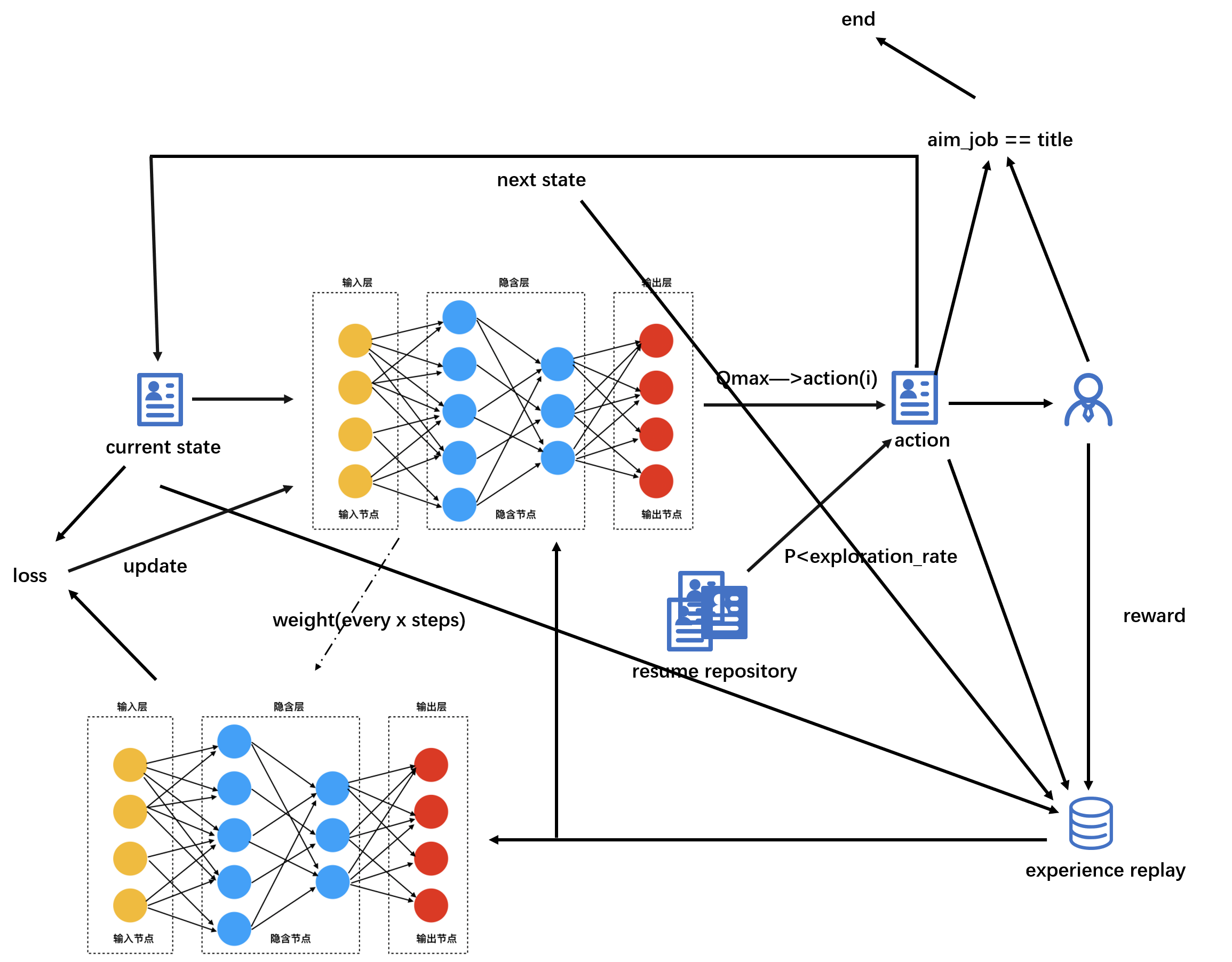
图8 算法示意图
五.编码以及调试过程中遇到的问题
1.如果一份简历中的求职者有两个目标岗位,如何解决?
数据集是一份excel文件,目标岗位都存在一个单元格中,比如:

图9 目标岗位栏出现的问题
可以利用spite函数,遇到“、”就分开,再将原来的一个目标岗位列分为两列(aim_job1、aim_job2)。如果该简历没写出目标岗位,这两列相应的位置置为none,如果给出一个目标岗位,放到aim_job1处,aim_job2处置为none,如果给出两个目标岗位,依次放入aim_job1、aim_job2。
2.如何设计奖惩函数?
要根据岗位特征值和简历特征值的匹配程度决定奖惩:
首先要对简历的特征值和岗位特征值进行编码,以数字代替字符串:
学历的对应编码:'中专': 1, '大专': 2, '本科': 3, '硕士': 4, '博士': 5
目标岗位的对应编码:'产品运营': 0, '平面设计师': 1, '财务': 2, '市场营销': 3, '项目主管': 4, '开发工程师': 5, '文员': 6, '电商运营': 7, '人力资源管理': 8, '风控专员': 9, 'None': 10
(1)如果该简历的目标岗位不是该岗位,reward为-30
(2)如果该简历的目标岗位是该岗位,但是学历、工作年限、年龄任一样不满足岗位需求,reward根据权重扣分,这里对于学历(education)的权重为2,工作年限(experience)的权重为1,reward的计算方式为:
self.reward = -5 + self.W[0] * (resume_experience - experience_min) + self.W[1] * (
resume_education - education_required)
(3)如果如果该简历的目标岗位是该岗位,且学历、工作年限、年龄都满足岗位要求,则学历越高、工作年限越长的简历reward值越大,这点可以通过用简历的学历、工作年限数值与岗位所需的学历、工作年限对应的数值做差,差值越大代表学历越高、工作年限越长,且计算reward时同样融入权重。
5 + 1 * (resume_experience – job_experience_min) + 2 * (resume_education – job_education_required)
3.如何取样本计算loss反向更新权重?
从经验回放池中取一批样本,分别取出一批样本中的同一个量,比如current state,打包为数组,这样可以得到四个数组,将存有next state的数组送入target network,将存有current state的数组送入Q Network,利用独热掩码提取出对应动作的QValue,与target network计算出的target value以及reward一起计算损失值。
4.报错:ValueError: You called set_weights(weights) on layer "match_model_1" with a weight list of length 4, but the layer was expecting 0 weights. Provided weights: [array([[-1.56753018e-01, 5.38734198e-02, 2.8747...
经过多次调试,作者发现是Q Network把权重赋值给Target Network的步数间隔与每次从经验回放池中采集的样本数量值之间不协调导致的,如果每次从经验回放池中采集的样本数量值过大,而Q Network把权重赋值给Target Network的步数间隔过小,就会报这个错误,但是理论原因作者暂时还解释不清,如果有大佬能解释,希望在评论区指出,这个报错在后面间接被解决。
5.算法陷入局部最优且收敛过慢问题
我们设置训练次数为5000次迭代:
设置训练参数为:
learning_rate=0.10, discount_factor=0.85, exploration_rate=0.5

我们可以看到平均奖励值一直在发生大幅度振荡,而且各简历的Q值排名发生下面情况:
Q值排序结果:
1 Num: 38,Name: 洪紫芬, Age: 38,Experience: 12,Education: 3,School: 北京师范大学, aim_job_1: 3, aim_job_2: 4 Q值为: 0.91416574
2 Num: 22,Name: 雷进宝, Age: 38,Experience: 9,Education: 4,School: 中国地质大学, aim_job_1: 4, aim_job_2: 10 Q值为: 0.826052
3 Num: 16,Name: 刘姿婷, Age: 36,Experience: 10,Education: 3,School: 武汉大学, aim_job_1: 3, aim_job_2: 4 Q值为: 0.77591
4 Num: 23,Name: 吴美隆, Age: 37,Experience: 6,Education: 4,School: 湖南大学, aim_job_1: 4, aim_job_2: 10 Q值为: 0.7495003
5 Num: 18,Name: 吕致盈, Age: 38,Experience: 12,Education: 3,School: 武汉理工大学, aim_job_1: 3, aim_job_2: 4 Q值为: 0.73388803
6 Num: 48,Name: 林盈威, Age: 34,Experience: 7,Education: 3,School: 南开大学, aim_job_1: 4, aim_job_2: 10 Q值为: 0.61048335
7 Num: 21,Name: 郑伊雯, Age: 39,Experience: 8,Education: 4,School: 华中农业大学, aim_job_1: 4, aim_job_2: 10 Q值为: 0.604043
8 Num: 55,Name: 姚扬云, Age: 35,Experience: 6,Education: 4,School: 中国传媒大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
9 Num: 58,Name: 唐欣仪, Age: 34,Experience: 11,Education: 1,School: 河北工业职业技术学院, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
10 Num: 53,Name: 郑星钰, Age: 26,Experience: 3,Education: 1,School: 新疆农业职业技术学院, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
11 Num: 35,Name: 林家纶, Age: 28,Experience: 5,Education: 2,School: 上海交通大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
12 Num: 45,Name: 胡泰, Age: 33,Experience: 10,Education: 2,School: 中山大学, aim_job_1: 0, aim_job_2: 4 Q值为: 0.0
13 Num: 59,Name: 陈政圣, Age: 32,Experience: 10,Education: 1,School: 北京医学高等专科学校, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
14 Num: 60,Name: 李淑淑, Age: 28,Experience: 5,Education: 1,School: 福建船政交通职业学院, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
15 Num: 44,Name: 郑雅茜, Age: 36,Experience: 7,Education: 4,School: 哈尔滨工业大学, aim_job_1: 4, aim_job_2: 10 Q值为: 0.0
16 Num: 41,Name: 任郁文, Age: 29,Experience: 3,Education: 3,School: 上海交通大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
17 Num: 100,Name: 林钰婷, Age: 31,Experience: 7,Education: 2,School: 北京师范大学, aim_job_1: 0, aim_job_2: 10 Q值为: 0.0
18 Num: 25,Name: 王美珠, Age: 35,Experience: 4,Education: 4,School: 湖南师范大学, aim_job_1: 4, aim_job_2: 10 Q值为: 0.0
19 Num: 32,Name: 吴美玉, Age: 34,Experience: 8,Education: 2,School: 电子科技大学成都学院, aim_job_1: 4, aim_job_2: 10 Q值为: 0.0
20 Num: 29,Name: 曹敏佑, Age: 29,Experience: 6,Education: 2,School: 山东大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
21 Num: 69,Name: 刘亭宝, Age: 26,Experience: 6,Education: 0,School: 济南传媒学校, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
22 Num: 24,Name: 吴心真, Age: 36,Experience: 7,Education: 4,School: 中南大学, aim_job_1: 4, aim_job_2: 10 Q值为: 0.0
23 Num: 20,Name: 黎芸贵, Age: 40,Experience: 14,Education: 3,School: 华中师范大学, aim_job_1: 3, aim_job_2: 4 Q值为: 0.0
24 Num: 19,Name: 方一强, Age: 39,Experience: 13,Education: 3,School: 中南财经政法大学, aim_job_1: 3, aim_job_2: 4 Q值为: 0.0
25 Num: 17,Name: 荣姿康, Age: 37,Experience: 11,Education: 3,School: 华中科技大学, aim_job_1: 3, aim_job_2: 4 Q值为: 0.0
26 Num: 11,Name: 李中冰, Age: 24,Experience: 5,Education: 0,School: 顺德中专学校, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
27 Num: 5,Name: 江奕云, Age: 28,Experience: 5,Education: 2,School: 华南理工大学, aim_job_1: 4, aim_job_2: 10 Q值为: 0.0
28 Num: 3,Name: 林玟书, Age: 28,Experience: 4,Education: 2,School: 南方科技大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
29 Num: 2,Name: 林国瑞, Age: 34,Experience: 11,Education: 2,School: 中国传媒大学, aim_job_1: 3, aim_job_2: 10 Q值为: 0.0
30 Num: 68,Name: 林承辰, Age: 25,Experience: 7,Education: 0,School: 济南新技术应用学校, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
31 Num: 50,Name: 李秀玲, Age: 32,Experience: 7,Education: 2,School: 中国传媒大学, aim_job_1: 0, aim_job_2: 4 Q值为: 0.0
32 Num: 84,Name: 刘小紫, Age: 30,Experience: 6,Education: 2,School: 东南大学, aim_job_1: 4, aim_job_2: 10 Q值为: 0.0
33 Num: 96,Name: 杜怡, Age: 30,Experience: 8,Education: 2,School: 北京城市学院, aim_job_1: 2, aim_job_2: 10 Q值为: 0.0
34 Num: 92,Name: 沈慧美, Age: 30,Experience: 6,Education: 2,School: 上海海洋大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
35 Num: 75,Name: 连书忠, Age: 32,Experience: 8,Education: 3,School: 中山大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
36 Num: 90,Name: 黄康刚, Age: 29,Experience: 8,Education: 2,School: 北京科技大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
37 Num: 88,Name: 吴婷婷, Age: 29,Experience: 3,Education: 3,School: 中央财经大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
38 Num: 87,Name: 林怡紫, Age: 26,Experience: 0,Education: 3,School: 中国人民大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
39 Num: 89,Name: 杨怡君, Age: 27,Experience: 4,Education: 2,School: 北京清华大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
40 Num: 97,Name: 潘孝东, Age: 23,Experience: 0,Education: 2,School: 中央戏曲学院, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
41 Num: 98,Name: 周志合, Age: 27,Experience: 4,Education: 2,School: 深圳大学, aim_job_1: 0, aim_job_2: 4 Q值为: 0.0
42 Num: 43,Name: 林石美, Age: 34,Experience: 11,Education: 2,School: 重庆大学, aim_job_1: 3, aim_job_2: 4 Q值为: -0.17997088
43 Num: 4,Name: 林雅南, Age: 28,Experience: 5,Education: 2,School: 华南师范大学, aim_job_1: 4, aim_job_2: 10 Q值为: -0.35405895
44 Num: 42,Name: 李治, Age: 32,Experience: 9,Education: 2,School: 同济大学, aim_job_1: 4, aim_job_2: 10 Q值为: -0.36112082
……
我们发现有部分简历,目标岗位与该岗位匹配,但是Q值却是0,而且黎芸贵的experience和education都要优于排名第一的洪紫芬,但是他的Q值却是0,这说明这些Q值为0的简历根本没有被训练到,算法在某一时刻陷入局部最优,要防止局部最优问题,我们常做的就是调整超参数值,尤其是exploration_rate,因为该值决定算法有多大概率随机选取一个动作,把这个值调大一些,可能防止陷入局部最优,因为我们的exploration_rate也会随迭代次数衰减。
现在把参数调整为:
learning_rate=0.10, discount_factor=0.85, exploration_rate=1

图11 算法收敛结果
我们发现算法收敛的很快,但是收敛的并不是很完美,而且Q值排名又出现了陷入局部最优的现象:
Q值排序结果:
1 Num: 48,Name: 林盈威, Age: 34,Experience: 7,Education: 3,School: 南开大学, aim_job_1: 4, aim_job_2: 10 Q值为: 2.521024
2 Num: 20,Name: 黎芸贵, Age: 40,Experience: 14,Education: 3,School: 华中师范大学, aim_job_1: 3, aim_job_2: 4 Q值为: 2.4513242
3 Num: 19,Name: 方一强, Age: 39,Experience: 13,Education: 3,School: 中南财经政法大学, aim_job_1: 3, aim_job_2: 4 Q值为: 2.3784618
4 Num: 17,Name: 荣姿康, Age: 37,Experience: 11,Education: 3,School: 华中科技大学, aim_job_1: 3, aim_job_2: 4 Q值为: 2.372804
5 Num: 24,Name: 吴心真, Age: 36,Experience: 7,Education: 4,School: 中南大学, aim_job_1: 4, aim_job_2: 10 Q值为: 2.3390896
6 Num: 22,Name: 雷进宝, Age: 38,Experience: 9,Education: 4,School: 中国地质大学, aim_job_1: 4, aim_job_2: 10 Q值为: 2.235163
7 Num: 18,Name: 吕致盈, Age: 38,Experience: 12,Education: 3,School: 武汉理工大学, aim_job_1: 3, aim_job_2: 4 Q值为: 2.152625
8 Num: 38,Name: 洪紫芬, Age: 38,Experience: 12,Education: 3,School: 北京师范大学, aim_job_1: 3, aim_job_2: 4 Q值为: 2.1127188
9 Num: 16,Name: 刘姿婷, Age: 36,Experience: 10,Education: 3,School: 武汉大学, aim_job_1: 3, aim_job_2: 4 Q值为: 2.1125493
10 Num: 21,Name: 郑伊雯, Age: 39,Experience: 8,Education: 4,School: 华中农业大学, aim_job_1: 4, aim_job_2: 10 Q值为: 2.1001434
11 Num: 44,Name: 郑雅茜, Age: 36,Experience: 7,Education: 4,School: 哈尔滨工业大学, aim_job_1: 4, aim_job_2: 10 Q值为: 2.089555
12 Num: 25,Name: 王美珠, Age: 35,Experience: 4,Education: 4,School: 湖南师范大学, aim_job_1: 4, aim_job_2: 10 Q值为: 1.840682
13 Num: 23,Name: 吴美隆, Age: 37,Experience: 6,Education: 4,School: 湖南大学, aim_job_1: 4, aim_job_2: 10 Q值为: 1.2011623
14 Num: 83,Name: 彭正仁, Age: 25,Experience: 2,Education: 2,School: 华中科技大学, aim_job_1: 0, aim_job_2: 10 Q值为: 0.0
15 Num: 35,Name: 林家纶, Age: 28,Experience: 5,Education: 2,School: 上海交通大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
16 Num: 43,Name: 林石美, Age: 34,Experience: 11,Education: 2,School: 重庆大学, aim_job_1: 3, aim_job_2: 4 Q值为: 0.0
17 Num: 52,Name: 叶惟芷, Age: 34,Experience: 3,Education: 4,School: 中国传媒大学, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
18 Num: 62,Name: 林雅慧, Age: 24,Experience: 5,Education: 0,School: 广州市轻工职业学校, aim_job_1: 0, aim_job_2: 10 Q值为: 0.0
19 Num: 66,Name: 赖淑珍, Age: 27,Experience: 1,Education: 0,School: 长沙职业技术学院, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
20 Num: 15,Name: 洪振霞, Age: 23,Experience: 4,Education: 0,School: 深圳中专学校, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
21 Num: 8,Name: 林子帆, Age: 28,Experience: 6,Education: 1,School: 阳江职业学院, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
22 Num: 6,Name: 刘柏宏, Age: 31,Experience: 9,Education: 1,School: 广东师范专科学院, aim_job_1: 10, aim_job_2: 10 Q值为: 0.0
23 Num: 4,Name: 林雅南, Age: 28,Experience: 5,Education: 2,School: 华南师范大学, aim_job_1: 4, aim_job_2: 10 Q值为: 0.0
24 Num: 45,Name: 胡泰, Age: 33,Experience: 10,Education: 2,School: 中山大学, aim_job_1: 0, aim_job_2: 4 Q值为: -0.3499998
25 Num: 42,Name: 李治, Age: 32,Experience: 9,Education: 2,School: 同济大学, aim_job_1: 4, aim_job_2: 10 Q值为: -0.36110973
说明即便把探索率拉到1,也难以解决到达最后一轮迭代的终止状态时,部分动作的Q值并没有被成功预测,也就是该动作就没有被执行过,这里面就可能包含最优解。
解决办法是在第一轮迭代的时候,把达到终止状态的条件设置为执行到所有动作:
if episode == 0:
if set(range(12, 112)).issubset(set(action_union)):
done = True
else:
done = False这样让每一个动作充分执行,避免了奖励值过于稀疏。

图12 算法很快收敛

图13 三维状态-动作对应Q值图
6.准确度过低的问题
最后再测试的时候,发现准确率在迭代的很长一段时间之内都很低,与标准结果不完全吻合,作者考虑原因是每次从经验回放中取出的样本数量有限,迭代后期经验回放池中样本总量远大于每次取出的样本数量,所以作者设置了,每次命中标准结果,都让每次取样本的数量增加100,让神经网络学习到的样本更充分,预测更准确。
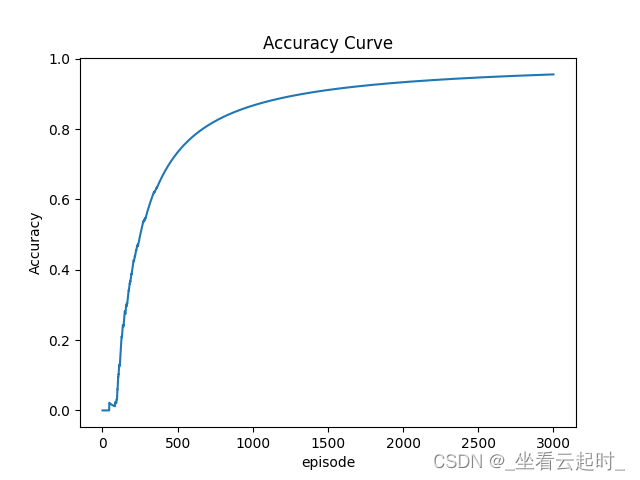
图14 算法准确度随迭代次数增加而递增
六.总结与展望
对于特征匹配的人岗匹配问题,个人认为DQN并不是优秀方案,应该采用自然语言处理方面的技术,由于项目时间有限,所以没有时间再更换方案从头开发模型,可以选用Actor-Critic算法开发人岗匹配模型,应该会有更好的效果。
七.参考文献
[1]吕亚珉.基于FM与DQN结合的视频推荐算法[J].计算机与数字工程,2021,49(09):1771-1776.
[2] https://gsurma.medium.com/cartpole-introduction-to-reinforcement-learning-ed0eb5b58288
[3]
https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-3-model-free-solutions-step-by-step-c4bbb2b72dcf
[4] 基于强化学习的智能机器人路径规划算法研究(附代码)_强化学习路径规划__坐看云起时_的博客-CSDN博客
[5] https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-4-q-learning-step-by-step-b65efb731d3e
[6]
https://medium.com/towards-data-science/reinforcement-learning-explained-visually-part-5-deep-q-networks-step-by-step-5a5317197f4b
[7] 强化学习(九)Deep Q-Learning进阶之Nature DQN - 刘建平Pinard - 博客园 (cnblogs.com)
[8]强化学习在e成科技人岗匹配系统中的应用 | 机器之心 (jiqizhixin.com)
[9] 强化学习在人才推荐中的应用 - 小析智能 (xiaoxizn.com)
[10]强化学习 DQN 经验回放 是什么_dqn经验回放_软件工程小施同学的博客-CSDN博客