-
一个AI中台覆盖从数据管理、数据标注、模型开发、部署上线到运营管理的AI能力研发与应用全生命周期建设和管理。作为企业AI能力的生产、应用和集中化管理平台,AI中台包括智能数据、模型开发、模型中心、预测服务、AI集市和平台管理等部分。
-
智能数据:提供样本数据采集、标注、清洗、加工等一站式数据服务。
-
模型开发:面向不同建模水平的人员提供全功能开发和零代码开发产品。
-
全功能开发:包括Notebook建模(JupyterLab代码式开发环境)、可视化建模(拖拉拽组件方式)、AutoML自动化建模、作业式建模、生产线建模(场景化建模工作流,内置PaddlePaddle预训练模型)等灵活的建模方式、丰富的开发套件。
-
零代码开发面向算法零基础或者追求高效率开发AI的企业用户。经零代码开发训练的模型,可部署在服务器、通用小型设备和专项适配硬件。
-
-
模型中心:提供对模型的统一纳管、转换和优化等能力,支持对平台自训练模型、第三方模型和镜像的管理。
-
服务中心:提供模型预测服务的统一接入、统一控管,支持在线预测、离线预测、端预测等多种服务部署形态,提供资源分配、调度、边缘服务管理和服务监控等功能;提高服务编排能力,加速企业智能化应用实施,通过将基础AI能力封装为通用场景服务,不同业务系统可以实现快速集成 。
-
AI集市:企业内的AI市场,支持样本数据、模型、服务等AI资产的发布与订阅,实现跨组织/跨平台的资产共享和交易,提升企业AI应用的协作效率,促进核心资产的共建和沉淀。
-
平台管理:提供组织用户、角色管理、权限审计、资源管理和调度、系统监控报警、日志管理等功能。满足平台建设内部管理要求,支持外部系统协同对接等IT管理诉求。
-
-
Notebook建模内置了完全托管的交互式编程环境CodeLab,实现数据处理和代码调试。Notebook建模支持集成ERNIE、PaddleX、PaddleOCR、PaddleHub组件,提升模型训练效率和效果。
-
多人标注:多人同时标注数据。管理员向标注成员派发任务,标注成员完成并提交任务后,管理员可进行验收。
-
智能标注:智能标注指用户只需人工标注数据集中的部分图片,而后系统自动标注其他图片,完成标注任务。启动智能标注后,系统会从数据集中筛选难例,让用户人工标注,而后系统自动标注未标图片。
-
数据清洗:数据清洗用于清洗图片和文本数据,例如对图片进行去模糊、去近似、旋转、镜像等操作,对文本进行去除emoji、繁体转简体等操作,提升数据质量。
-
数据回流:在智能数据对接预测服务产品的前提下,数据回流支持将预测服务的结果保存至数据集,用于后续的训练等任务。
-
AI中台支持Pascal VOC及COCO这两种图像标注格式的导入和导出,同时也支持平台通用Json的导入和导出。Pascal VOC及COCO是国际通用的主流图像标注格式,具有跨平台特性,建议用户首选使用。
-
PASCAL VOC格式:包含JPEGImages和Annotations这两个文件夹,分别包括图片文件和标注文件。
-
JPEGImages:包括是所有图片信息,包括训练图片、测试图片,这些图像就是用来进行训练和测试验证的图像数据。
-
Annotations:包括xml格式的标签文件,每个xml对应JPEGImage中的一张图片,用于描述图像中的标注信息。
-
├── Annotations │ ├── 1.xml │ └── 2.xml └── Images ├── 1.jpeg └── 2.jpeg -
# 单标签 <?xml version='1.0' encoding='UTF-8'?> <annotation> # 文件名 <filename>1.jpeg</filename> <object_num>1</object_num> <size> <width>1044</width> <height>915</height> </size> <object> # 标注名 <name>aircraft</name> </object> </annotation> # 多标签 <?xml version='1.0' encoding='UTF-8'?> <annotation> <filename>1.jpeg</filename> <object_num>1</object_num> <size> <width>1044</width> <height>915</height> </size> <object> <name>aircraft</name> </object> <object> <name>car</name> </object> </annotation>
-
-
COCO类别及格式coco2017数据集80类别名称与id号的对应关系_coco2017类别中文_Dreaming_of_you的博客-CSDN博客:
-

-
├── Annotations │ └── coco_info.json └── Images ├── 1.jpeg ├── 2.jpeg ├── 3.jpeg └── 4.jpeg -
# coco_info.json 必须同名 # 单标签 { "images": [{"file_name": "1.jpeg", "height": 915, "width": 1044, "id": 1}, {"file_name": "2.jpeg", "height": 915, "width": 1044, "id": 2}, {"file_name": "3.jpeg", "height": 915, "width": 1044, "id": 3}, {"file_name": "4.jpeg", "height": 915, "width": 1044, "id": 4}], "annotations": [ //iscrowd: <不使用> iscrowd=0那么segmentation就是polygon格式;只要iscrowd=1那么segmentation就是RLE格式 //category_id: 标注id //area: <不使用> {"segmentation": null, "area": 1.1, "iscrowd": 0, "bbox": null, "category_id": 0, "image_id": 1, "id": 0}, {"segmentation": null, "area": 1.1, "iscrowd": 0, "bbox": null, "category_id": 0, "image_id": 2, "id": 1}, {"segmentation": null, "area": 1.1, "iscrowd": 0, "bbox": null, "category_id": 0, "image_id": 3, "id": 2}, {"segmentation": null, "area": 1.1, "iscrowd": 0, "bbox": null, "category_id": 0, "image_id": 4, "id": 3}], "info": "info", "licenses": "licenses", "image_nums": 4, "categories": [{"id": 0, "name": "aircraft"}] } # 多标签 { "images": [{"file_name": "1.jpeg", "height": 915, "width": 1044, "id": 1}, {"file_name": "2.jpeg", "height": 915, "width": 1044, "id": 2}, {"file_name": "3.jpeg", "height": 915, "width": 1044, "id": 3}, {"file_name": "4.jpeg", "height": 915, "width": 1044, "id": 4}], "annotations": [ {"segmentation": null, "area": 1.1, "iscrowd": 0, "bbox": null, "category_id": 0, "image_id": 1, "id": 0}, {"segmentation": null, "area": 1.1, "iscrowd": 0, "bbox": null, "category_id": 1, "image_id": 2, "id": 1}, {"segmentation": null, "area": 1.1, "iscrowd": 0, "bbox": null, "category_id": 0, "image_id": 3, "id": 2}, {"segmentation": null, "area": 1.1, "iscrowd": 0, "bbox": null, "category_id": 1, "image_id": 4, "id": 3}], "info": "info", "licenses": "licenses", "image_nums": 4, #标签列表 "categories": [{"id": 0, "name": "aircraft"}, {"id": 1, "name": "car"}] }
-
-
-
针对图像分类/ 物体检测/ 图像分割数据集,在“数据集管理”页面,选择操作列中的“发布”。数据集发布成功后,点击操作列中的“去训练”, 跳转到“全功能开发” 或 “零代码开发”中训练模型。或者用户也可以直接至全功能开发” 或 “零代码开发”菜单中,选择已发布的数据集训练模型。
-
智能标注功能通过智能模型+人工确认协同完成标注。主动学习指基于您的数据集训练专有智能标注底层模型,通过多轮次筛选难例,帮助您持续提升标注效果。启动后,系统会从数据集所有图片中筛选出最关键的图片并提示需要优先标注。通常情况下,只需标注数据30%左右的数据就等同标注所有数据后训练的模型效果,若发现系统预标注的框非常精准时,您可手动结束标注,节省标注时间和资源。
-
启动智能标注前,请先检查一下是否已满足以下条件:
-
所有需要识别的标签都已创建。
-
每个标签的标注框数不少于10个。
-
所有需要标注的图片都已加入数据集,且所有不相关的图片都已删除。
-
针对主动学习任务,由于系统筛选图片需一定时间,该功能将在未标图片数大于100且每个标签的标注框数都达到10个时方可启动。
-
-
平台提供多人标注的数据标注方式,提高数据标注效率。
-

-
管理员创建多人标注任务,系统会生成标注子任务并派发给多人标注团队中的成员,并根据团队成员数自动分发任务量;也可选择由标注管理员分配任务。
-
标注员开始标注数据,完成标注后提交任务,管理员验收标注结果。
-
如果开启审核功能,在标注员提交标注任务后,系统会自动将任务分发给审核员。审核员开始审核,审核通过后,管理员进行验收。
-
管理员验收通过后,方可对该数据集进行后续清洗、导出等更多数据处理操作。支持查看标注员或审核员的绩效报告,标注管理员也可查看标注员或审核员的绩效报告。
-
-
术语 解释 Notebook建模 内置了完全托管的交互式编程环境JupyterLab,实现数据处理和代码调试。 可视化建模 提供可视化的实验开发环境,用户根据场景和业务需求在交互式画布上直观地连接数据处理、特征工程,算法,模型预测和模型评估等组件,开始训练模型。 自动化建模 一款自动化程度比较高的建模方式。用户只需提交数据、选择真实标签列,平台自动进行特征工程、算法选择和参数调优,进而构建高精度模型。 作业建模 一种大规模训练任务提交的建模方式,支持同一作业不同参数组合的多版本的批量提交、追踪和参数指标对比。 产线建模 一种零代码、全自动、内置预训练模型的深度学习建模方式,支持对图像、文本等非结构化数据进行建模训练。 计算机视觉 属于生产线建模的一种,提供计算机视觉(Computer Vision,简称CV)相关领域的建模, 支持图片分类、物体检测、语义分割、实例分割等场景。 自然语言处理 属于生产线建模的一种,提供自然语言处理(Natural Language Processing,简称NLP)相关领域的建模,支持命名实体识别、实体属性、实体关系、情感倾向分析、文本分类、短文本匹配、词性标注等场景。 工作流 本质是业务流的调度,用户可以灵活自定义业务节点,并且把不同的业务节点所需要的资源从实验环境中调度,单次或定期执行。 实验 使用自动化建模、可视化建模、生产线建模等方式的集合。 运行 记录实验的一次运行过程,包括依赖的数据集、dag图等。 DAG 指有向无环图,可视化建模提供DAG的方式训练模型。 自定义组件 指在可视化建模中,用户基于TensorFlow、PySpark、Sklearn、MXNet等常用框架而创建的数据处理、特征工程、算法等各类组件。 分布式训练 作业建模支持分布式训练(多机训练),采用数据并行模式,将数据集均等地分配到平台创建的各个作业实例中。 -
数据探索模块支持您分析数据集中数据的特征,查看数据特征之间的相关性,查看特征对类别的影响,帮助您更好地进行特征分析和特征选择。如果您不确定基于业务情况,应该选择哪个图表,可参考以下指南:
-
Notebook集成了VisualDL工具。VisualDL是飞桨可视化分析工具,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、直方图、PR曲线及高维数据分布,帮助用户更清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型优化。
-
训练代码中增加 Loggers 来记录不同种类的数据。
-
from visualdl import LogWriter if __name__ == '__main__': value = [i/1000.0 for i in range(1000)] # 初始化一个记录器 with LogWriter(logdir="./log/scalar_test/train") as writer: # 训练过程中插入数据打点语句,将结果储存至日志文件中。 for step in range(1000): # 向记录器添加一个tag为`acc`的数据 writer.add_scalar(tag="acc", step=step, value=value[step]) # 向记录器添加一个tag为`loss`的数据 writer.add_scalar(tag="loss", step=step, value=1/(value[step] + 1)) -
日志文件适用于scalar, image, histogram, pr curve, high dimensional五种组件。日志文件可多选,模型文件一次只能上传一个,且模型文件暂只支持模型网络结构,不支持展示各层参数。
-
-
组件名称 展示图表 作用 Scalar–标量组件 折线图 动态展示损失函数值、准确率等标量数据 Image–图片可视化组件 Image–图片可视化组件 显示图片,可显示输入图片和处理后的结果,便于查看中间过程的变化 Audio–音频播放组件 音频可视化 播放训练过程中的音频数据,监控语音识别与合成等任务的训练过程 Graph–网络结构组件 网络结构 展示网络结构、节点属性及数据流向,辅助学习、优化网络结构 Histogram–直方图组件 直方图 展示训练过程中权重、梯度等张量的分布 PR-Curve–PR曲线组件 折线图 权衡精度与召回率之间的平衡关系 High-Dimensional–数据降维组件 数据降维 将高维数据映射到 2D/3D 空间来可视化嵌入,便于观察不同数据的相关性 -
为方便跨平台调用,Notebook建模支持将模型转换为PMML格式,支持将sklearn模型转换为Joblib格式。
-
预言模型标记语言(Predictive Model Markup Language,PMML)是一种利用XML描述和存储数据挖掘模型的标准语言。PMML适用于跨平台的机器学习模型部署。当模型需要跨平台部署或反复调用时,您可把模型保存为PMML文件。例如,您最近要上线一个反欺诈模型(GBDT),训练模型时用的Python语言,生产调用用的是Java语言,这时您可把在Python中把训练好的模型保存为PMML文件,到Java中直接调用预测。
-
在Python转换为PMML文件的过程中,仅支持sklearn中自带的特征工程,不支持自定义函数。
-
import pandas from sklearn.datasets import load_iris iris_df = load_iris() iris_X = iris_df.data iris_y = iris_df.target from sklearn.tree import DecisionTreeClassifier from sklearn2pmml.pipeline import PMMLPipeline pipeline = PMMLPipeline([ ("classifier", DecisionTreeClassifier()) ]) pipeline.fit(iris_X, iris_y) from sklearn2pmml import sklearn2pmml sklearn2pmml(pipeline, "DecisionTreeIris.pmml", with_repr = True)
-
-
可将训练好的模型发布到模型中心,方便后续发布预测服务。模型中心是AI模型的集中纳管、评估、优化转换处理场所,提供模型纳管、评估、优化、端适配及加密等功能。需要编写预测代码,定义模型的加载和预测方式,并命名为 “model.py",请确保预测文件 “model.py” 和模型文件在同一个目录中。
-
Tips: 新建Notebook任务后,进入CodeLab,选择 ”help"文件夹。文件夹中的“model.py"文件包含了预测代码示例。
-
import pandas as pd import joblib LABEL_NAME = 'class' class PyModel(object): """ Sklearn 自定义算法代码 """ def __init__(self): """ 类的构造函数 """ self.feature_name = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] self.load() def load(self): """ load the real model :return: """ # model_path the relative path of model, must in the same path of this code file model_path = 'model.joblib' self.model = joblib.load(model_path) def transform(self, dataset): # type:(pd.DataFrame)->pd.DataFrame """ :param dataset: :return: """ # 使用和训练时相同的 feature name prediction = self.model.predict(dataset[self.feature_name]) if LABEL_NAME in dataset: return pd.DataFrame({'prediction': prediction, LABEL_NAME: dataset[LABEL_NAME]}) else: return pd.DataFrame({'prediction': prediction}) -
平台提供了预测脚本样例,帮助您判断model.py文件是否编写正确。进入 ”help"文件夹,找到"help_model.py"文件,参考示例编写脚本,测试模型。
-
#Notebook训练的模型发布至预测服务后,如何编写测试用途的输入示例 ? # 前置概念解释 # 预测服务输出是一个dataframe对应的json # 预测服务输入也是一个dataframe对应的json # 假设输入的参数有三个:input_param_01、input_param_02、img_base64 # 客户自定义实现的预测服务的入口文件:model.py transform()函数接收输入参数示例: # 此函数对应的接收为在预测服务请求json 通过dataframe转换后的结果 ,返回值也需要通过pd.DataFrame进行格式转换显示 def transform(self, dataset): # type:(pd.DataFrame)->pd.DataFrame #接受dataFrame类型数据 input_param_01 = dataset['input_param_01'] input_param_02 = dataset['input_param_02'] img_base64 = dataset['img_base64'] #模拟预测操作 model为自定义加载的模型文件 prediction = self.model.predict(dataset[self.feature_name]) #返回需要是dataFrame格式 return pd.DataFrame({'prediction': prediction}) # 客户自测model.py 示例 # 对应的测试模型的测试文件app.py,可以是: from model import PyModel import pandas as pd m = PyModel() dataset = pd.DataFrame({ "data": { "input_param_01": "shebeishishu111.jpeg", "input_param_02": 2222, "img_base64": "image的base64编码" } }) # 观察是否符合预测结果 print(m.transform(dataset)) # 预测服务默认Json最上层为两层data嵌套,即第二层data内数据为用户自定义 # 根据以上文件,在预测服务请求框对应的输入示例json应为: { "data": { "data": { "input_param_01": "xxxxxx", "input_param_02": 2222, "img_base64": "img_base64" } } }
-
-
百度智能云-AI中台 (jxpaddle.com)
-
术语 解释 模型导入-模型文件 将标准框架的模型文件导入模型中心。标准框架包括深度学习框架(例如TensorFlow、PaddlePaddle)、传统机器学习框架(例如Sklearn)以及PMML、ONNX等通用框架。 模型导入-镜像 将模型镜像文件导入模型中心。镜像中需包含预测推理服务所需的全部资源,例如模型文件、基础镜像、环境依赖、预处理/后处理代码、启动脚本等。 部署包 将模型文件及预测推理服务所需的基础镜像、环境依赖、前/后处理代码、启动脚本等资源或配置信息打包所生成的模型镜像或SDK文件。可用于部署至运行环境或进行二次开发,并对外提供预测推理服务。 Helm Chart 基于Helm Chart文件及Key-value参数来配置部署包的方式,适用于复杂AI场景。例如:当一个预测推理服务包含多个镜像的情况。 模型评估 通过推理实验,对模型的效果(推理精度)和性能(推理效率)进行测试的过程 模型加速 也称为模型压缩,属于性能优化的一种方式。可在不降低模型效果或小幅降低模型效果的情况下显著提升模型性能 模型部署 将模型部署到运行环境中,并对外提供预测推理服务的过程。当部署在在服务器或服务器集群环境中时,一般称之为云部署;当部署在边缘设备上时,则称之为边缘部署,对应的部署动作也可称为模型下发。 模型下发 也称为边缘部署,属于模型部署的一种类型,特指将模型部署至边缘设备 公共模型 在某个组织或整个平台范围内共享的模型。用户将项目模型共享至组织或全局后,该模型就变为公共模型,支持组织或整个平台内具有相应权限的用户查看并使用该模型。 -
模型评估用于统一评价所纳管的模型能力,帮助用户选择最佳模型进行部署。支持在云端和边缘环境下进行评估,并支持对模型效果(推理准确性)、模型性能(推理效率和资源消耗)进行评估。评估指标支持准确率、召回率、F1分数、混淆矩阵、P-R曲线、推理时延等参数,给予用户完善的模型评估体验。
-

-
在“智能数据”中,新建并导入数据集
-
在“模型开发”中,训练模型
-
模型训练完成后,将模型发布至模型中心;或者导入第三方/离线开发的模型至模型中心,支持通过模型文件或镜像的方式导入
-
在模型中心,评估模型,并查看评估结果。根据评估指标及建议,可线下进行模型调优或重训
-
模型评估完成后,对模型进行云部署或边缘部署。如果要将模型部署至边缘节点上,还需提前在“智能边缘“上管理边缘节点
-
# 图像分类 #!/usr/bin/env python3 # -*- coding: utf-8 -*- """ 自定义出入参脚本:输入处理/输出处理 """ # 运行环境已安装如下依赖库,可直接使用: # pyparsing,pyarrow,shapely,pycocotools,chardet,pandas,scipy # scikit-learn,numpy,opencv-python,Pillow def input_func(sample_content): """ 自定义输入处理过程:基于样本内容,给出发起预测请求所需的: 1. query:请求参数 2. header:请求头信息 3. body:请求消息体 :param sample_content: 样本内容 :type sample_content: bytes """ query = {} # dict形式 header = {} # dict形式 body = b'' # bytes or str # 如base64 # import base64 # body = base64.b64encode(sample_content).decode() # 补充处理代码 return query, header, body def output_func(infer_result_body): """ 自定义输出处理过程: 1. 解析模型预测结果 2. 参考平台各模型类型对应的结果样例,将预测结果转换为对应格式 3. 如模型训练用的标签,和评估数据集不一致,也可在此将预测结果标签映射为评估数据集中对应的标签 :param infer_result_body: 预测结果 :type infer_result_body: bytes 图像分类模型期望的返回格式如下: [ { 'index': 1, # 预测结果:标签索引 'label': 'orange', # 预测结果:标签值 'confidence': 0.9, # 预测结果:置信度 }, # 更多预测结果 ] """ res = [] # 下面补充处理代码 return res # 物体检测 #!/usr/bin/env python3 # -*- coding: utf-8 -*- """ 自定义出入参脚本:输入处理/输出处理 """ # 运行环境已安装如下依赖库,可直接使用: # pyparsing,pyarrow,shapely,pycocotools,chardet,pandas,scipy # scikit-learn,numpy,opencv-python,Pillow def input_func(sample_content): """ 自定义输入处理过程:基于样本内容,给出发起预测请求所需的: 1. query:请求参数 2. header:请求头信息 3. body:请求消息体 :param sample_content: 样本内容 :type sample_content: bytes """ query = {} # dict形式 header = {} # dict形式 body = b'' # bytes or str # 如base64 # import base64 # body = base64.b64encode(sample_content).decode() # 补充处理代码 return query, header, body def output_func(infer_result_body, sample_shape): """ 自定义输出处理过程: 1. 解析模型预测结果 2. 参考平台各模型类型对应的结果样例,将预测结果转换为对应格式 3. 如模型训练用的标签,和评估数据集不一致,也可在此将预测结果标签映射为评估数据集中对应的标签 :param infer_result_body: 预测结果 :type infer_result_body: bytes :param sample_shape: 原始样本图片的宽高 (im_w, im_h) :type sample_shape: tuple :rtype: list 物体检测模型期望的返回格式如下: [ { 'index': 1, # 预测结果:标签索引 'label': 'orange', # 预测结果:标签值 'confidence': 0.9, # 预测结果:置信度 'x1': 120, # bbox左上角坐标 'y1': 120, # bbox左上角坐标 'x2': 180, # bbox右下角坐标 'y2': 180, # bbox右下角坐标 }, # 更多预测结果 ] """ res = [] # 下面补充处理代码 return res # 实例分割 #!/usr/bin/env python3 # -*- coding: utf-8 -*- """ 自定义出入参脚本:输入处理/输出处理 """ # 运行环境已安装如下依赖库,可直接使用: # pyparsing,pyarrow,shapely,pycocotools,chardet,pandas,scipy # scikit-learn,numpy,opencv-python,Pillow def input_func(sample_content): """ 自定义输入处理过程:基于样本内容,给出发起预测请求所需的: 1. query:请求参数 2. header:请求头信息 3. body:请求消息体 :param sample_content: 样本内容 :type sample_content: bytes """ query = {} # dict形式 header = {} # dict形式 body = b'' # bytes or str # 如base64 # import base64 # body = base64.b64encode(sample_content).decode() # 补充处理代码 return query, header, body def output_func(infer_result_body, sample_shape): """ 自定义输出处理过程: 1. 解析模型预测结果 2. 参考平台各模型类型对应的结果样例,将预测结果转换为对应格式 3. 如模型训练用的标签,和评估数据集不一致,也可在此将预测结果标签映射为评估数据集中对应的标签 :param infer_result_body: 预测结果 :type infer_result_body: bytes :param sample_shape: 原始样本图片的宽高 (im_w, im_h) :type sample_shape: tuple :rtype: list 实例分割模型期望的返回格式如下: [ { 'index': 1, # 预测结果:标签索引 'label': 'orange', # 预测结果:标签值 'confidence': 0.9, # 预测结果:置信度 'x1': 120, # bbox左上角坐标 'y1': 120, # bbox左上角坐标 'x2': 180, # bbox右下角坐标 'y2': 180, # bbox右下角坐标 'mask': '<游程编码>', # Run Length Encoding,游程编码的mask,参考:https://github.com/Baidu-AIP/EasyDL-Segmentation-Demo }, # 更多预测结果 ] """ res = [] # 下面补充处理代码 return res
-
-
图像类模型评估指标
-
图像分类
-
指标 说明 准确率(%) 正确预测的样本数与总样本数的比例 精确率(%) 被预测为正样例中真实为正的比例,取各类别平均值 召回率(%) 真实正样本中被预测为正(正确预测)的比例,取各类别平均值;又称真阳性率 F1分数(%) 精确率和召回率的调和平均数
-
-
物体检测
-
指标 说明 mAP(%) 针对每个样本类别,计算各置信度阈值下的P-R曲线下面积,取平均值得到mAP (mean Average Precision) 精确率(%) 被预测为正样例中真实为正的比例,取各类别平均值 召回率(%) 真实正样本中被预测为正(正确预测)的比例,取各类别平均值;又称真阳性率 F1分数(%) 精确率和召回率的调和平均数
-
-
-
性能指标,平台也将自动输出模型预测性能指标供用户综合评价模型可用性。
-
指标 说明 模型体积 (MB) 模型文件所占存储空间的大小,可用来表征模型计算复杂性和参数数量 计算时延 (ms) 模型执行一次推理的平均时延,根据所选评估环境,可能还包括模型服务访问,模型前后预处理等时间。若被评模型为图像类模型,计算时延为单样本预测模式下的推理时延;若被评模型为结构化数据模型,计算时延为批量预测模式下的推理时延 CPU占用率 (%) 模型执行一次计算所占用的平均CPU资源比例。 GPU占用率 (%) 模型执行一次计算所占用的平均GPU资源比例。 AI芯片占用率 (%) 模型执行一次计算所占用的平均芯片资源比例。(仅适用边缘评估) 内存占用 (MB) 模型执行一次计算所占用的平均内存资源大小 显存占用 (MB) 模型执行一次计算所占用的平均显存资源大小 硬件功耗 (W) 模型执行一次计算所使用的平均硬件功耗。注意:该指标为硬件整体功耗,若硬件上有其他应用/进程正在运行,可能影响功耗指标结果。(仅适用边缘评估)
-
-
AI开发者完成模型开发后,往往需要对模型进行性能优化,以提高模型推理速度并匹配线上服务效率和部署资源限制要求。 为降低模型性能优化工作门槛,提高服务上线效率效果,模型加速功能通过预置多种推理优化工具,帮助用户快速完成模型性能优化。
-
加速配置的相关参数
-
参数 说明 目标部署环境 选择加速后模型目标的部署环境,支持云端或边缘部署。 硬件/芯片类型 从下拉框中选择可用的硬件/芯片类型,根据所需模型框架和网络结构,自动生成可选支持范围 操作系统 根据所需模型框架和网络结构,自动生成可选支持范围 ;大多模型可选择Linux操作系统,部分模型还可选择iOS、Android系统 加速策略 当前版本支持量化压缩、模型剪枝、框架转换、智能加速策略。不同加速策略下有细化的配置可控选择,具体可选内容根据模型框架、网络结构、目标部署硬件自动生成。量化压缩:将原始的全精度32位浮点数分桶量化为位数更小的定点整数(FP16/INT8),从而提升计算速度,减少模型体积 ; 模型剪枝:通过裁剪神经网络部分卷积通道,降低模型参数量;剪枝比例过大时,模型效果可能伴随有较大损失 ; 框架转换:将模型框架转换为硬件芯片专用的高性能推理引擎,从而提升计算速度,一般不会造成模型效果损失; 智能加速:结合百度AI最佳实践,面向目标部署硬件和模型网络特点,智能选择最佳的加速策略组合,提升加速效果,减少人工调试成本 校正数据集 选择智能数据中符合所选模型类型的校正数据集,一般应选择训练集,可帮助降低模型精度损失。若不选择校正数据集,系统将使用平台默认数据集,加速模型效果可能受到轻微影响。
-
-
预测服务的名词解释
-
术语 解释 平台托管服务 指通过平台模型中心的模型或服务编排任务所创建的预测服务。 第三方服务 外部接口在平台内注册后形成的服务。 应用接入 应用接入是面向应用开发者的预测服务统一接入模块。应用是多个预测服务的集合,用户可将多个服务打包成一个AI应用分发给不同的应用开发者。每个应用会有独立的Access Key 和 Secret Key,以限制不同开发者的调用并方便后续的统计分析。 TPS Transactions Per Second, 即服务器每秒处理的请求事务数。 弹性伸缩 预测服务支持自动扩容,调整计算资源。当CPU、TPS和AI加速卡等的负载指标达到特定阈值时,可以启动新的副本。默认为水平伸缩。 预置服务 指客户购买后,系统内置的AI服务,包括人脸识别、文字识别、语音技术、自然语言处理等类型。 RPC 指Remote Procedure Call Protocol。远程过程调用RPC是把本地函数映射到API,即一个API对应的是一个函数。举例,本地有一个getAllUsers,远程也能通过某种约定的协议来调用这个getAllUsers。请求格式一般是json-rpc的形式。 服务编排 服务编排是面向AI应用开发者的AI能力可视化编排平台,提供拖拽式、可视化的工作流编排界面和代码编排方式,支持用户按照业务逻辑,以串行、并行和分支等结构编排多个服务为业务应用。
-
-
平台支持AB实验,您可以通过流量细分、随机实验等手段,监控并跟踪实验效果,以此判断实验所代表的模型策略的可行性和有效性。AB测试解决的是策略优化的问题,即从多个可选策略里找出最优策略,它可以帮助数据科学家或模型开发人员判断相比于已经发布部署的模型,新开发的变体模型在实际业务上的表现如何。
-
A/B实验基本思想是:
- 从线上流量中取出一小部分流量(较低风险),完全随机地分给原策略A和新策略B(排除干扰),再结合一定的统计方法,得到对于两种策略相对效果的准确估计(量化结果)。这一套基于小样本的实验方法同时满足了低风险,抗干扰和量化结果的要求,亦被称为“对照实验”或“小流量随机实验”。
-
实验组与对照组
- 实验组和对照组是一组相对的概念,A/B实验通常是为了验证一个新策略的效果。假设在实验中,所抽取的用户被随机地分配到A组和B组中,A组用户在产品中体验到新策略,B组用户在实验中体验的仍旧是旧策略。在这一实验过程中,A组便为实验组,B组则为对照组。
-
关注指标
- 在开始一个实验时,目的是对比对照组和实验组的某个或者某几个指标的差异。
-
假设检验
-
A/B实验的核心统计学理论是(双样本)假设检验。假设检验,即首先做出假设,然后运用数据来检验假设是否成立。需要注意的是 ,我们在检验假设时,逻辑上采用了反证法。通过A/B实验,我们实际上要验证的是一对相互对立的假设:原假设和备择假设。
-
原假设(null hypothesis):是实验者想要收集证据予以反对的假设。A/B实验中的原假设就是指“新策略没有效果”。
-
备择假设(alternative hypothesis):是实验者想要收集证据予以支持的假设,与原假设互斥。A/B实验中的备择假设就是指“新策略有效果”。 利用反证法来检验假设,意味着我们要利用现有的数据,通过一系列方法证明原假设是错误的(伪),并借此证明备择假设是正确的(真)。这一套方法在统计学上被称作原假设显著性检验 null hypothesis significance testing (NHST)。
-
-
第一类错误和显著性水平(α)
- 第一类错误,指原假设正确(真),但是我们假设检验的结论却显示原假设错误。这一过程中我们拒绝了正确的原假设,所以第一类错误是“弃真”。 第一类错误在实际操作中表现为:实验结论显示我的新策略有用,但实际上我的新策略没有用。 在统计学中,我们用显著性水平(α)来描述实验者犯第一类错误的概率。
-
第二类错误( β )和统计功效(statistics power)
- 第二类错误,指原假设错误(伪),但是我们假设检验的结论却显示“原假设正确(真)、备择假设是错误的”,这一过程中我们接受了错误的原假设,所以第二类错误是“取伪”。 第二类错误在实际操作中表现为:我的新策略其实有效,但实验没能检测出来。 在统计学中,统计功效 = 1 - 第二类错误的概率,统计功效在现实中表现为:我的新策略是有效的,我有多大概率在实验中检测出来。
-
-
在AB实验期间,应用侧仍调用基线服务(旧服务)的API地址即可,平台会自动按规则将流量分发至实验组的服务;
-
在AB实验结束后,如果确定要使用实验组服务(新服务)承接原有业务,则在A服务内新增版本,并执行更新操作即可;
-
目前该功能暂不支持编排服务与第三方服务,不支持异步服务。
-
-
术语 解释 组织 组织是平台用户的唯一属性。一个用户必须且只能属于一个组织。 项目 项目是用来横向管理为实现某目标而创建的数据、任务、服务的虚拟概念,按产品或工作任务进行划分,例如风控项目和推荐项目。 用户 一个用户只能属于一个组织,但可属于多个项目。 角色 角色是一组权限的集合。通过为用户授予角色,用户可以获取相应的权限。 机器池 对于有资源硬隔离需求的使用者,可通过机器池划分不同的硬件资源,以便硬件资源隔离使用。创建机器池后,可基于不同的机器池创建资源池并分配给所需的项目或服务。 资源池 指计算资源,提供对CPU、内存、AI加速卡的配额设置,同时支持设定资源池的可用服务,如某资源池仅可在Notebook建模中使用。 存储源 代表一个存储集群来源,包括访问存储集群的连接信息,表示一个存储集群来源和访问该存储集群的必要客户端部署信息。平台支持HDFS、NFS、GlusterFS、HDFSWithKerberos、BOS和PVC等存储源。 存储卷 存储卷代表一个存储空间,对应具体存储集群的某个子目录。存储卷用来保存平台上产生的输入输出数据。 共享存储卷 共享存储卷可由同组织或跨组织的多个项目使用。 私有存储卷 私有存储卷仅能由一个项目使用。 默认存储卷 默认存储卷用于存放各业务模块的产出数据,比如导入的数据集、训练产出的模型和中间结果、日志等。每个项目只有一个默认存储卷且必须有默认存储卷才能运行。 历史默认存储卷 当项目关联新的默认存储卷后,原有存储卷会自动变为“历史默认存储卷”,历史默认存储卷仍可作为该项目的存储卷使用,但由于保存了各个业务模块产生的数据,为避免项目内数据丢失,建议保留历史默认存储卷。 镜像 指模型训练镜像和服务运行所依赖的环境。平台支持Dockerfile、Tar包和Notebook导出的方式构建镜像。 公共镜像 在整个平台范围内共享的镜像。用户将镜像共享至全局后,该镜像就变为公共镜像,整个平台内具有镜像权限的用户可查看并使用该镜像。 vGPU 指虚拟化GPU技术。通过划分显存,实现多个实例共享GPU,能够大大提高并发量和资源利用率。 -
计算资源为CPU、内存、AI加速卡资源配额的集合,规定了一组计算资源的可用能力及使用量上限。通过机器池,可实现资源硬隔离,确保训练和预测服务调度在不同的机器上,实现企业内部的管理要求。通过资源池,达到项目之间计算资源的软隔离,避免单个项目占用过多资源导致整个平台不可用。
-
存储模块主要用于存放用户在平台过程中需要使用或产生的数据。整体存储资源管理包括存储源和存储卷两部分。其中,存储源主要用于管理存储集群的连接信息,支持多种类型的存储接入及使用。存储卷对应存储集群的某个子目录,可绑定至组织或项目使用。客户可通过设置存储卷的“共享/私有”属性决定存储内部数据对不同项目的可见性,维护数据安全。系统卷(v-system-volume)在页面不可见,内置依赖包、公共数据集和模型、容器日志等。
-
平台会设置默认的机器池,默认将机器池中的资源分配给平台中的所有组织项目。如果您需要实现资源硬隔离,可新建机器池。一个项目必须关联资源池且有默认存储卷后,方可正常运行。下图介绍如何为项目分配计算资源和存储资源。
你可以对AI中台有所了解
news2026/2/14 23:51:24


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/718638.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
基于JavaSpringBoot+Vue+uniapp微信小程序实现鲜花商城购物系统
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…
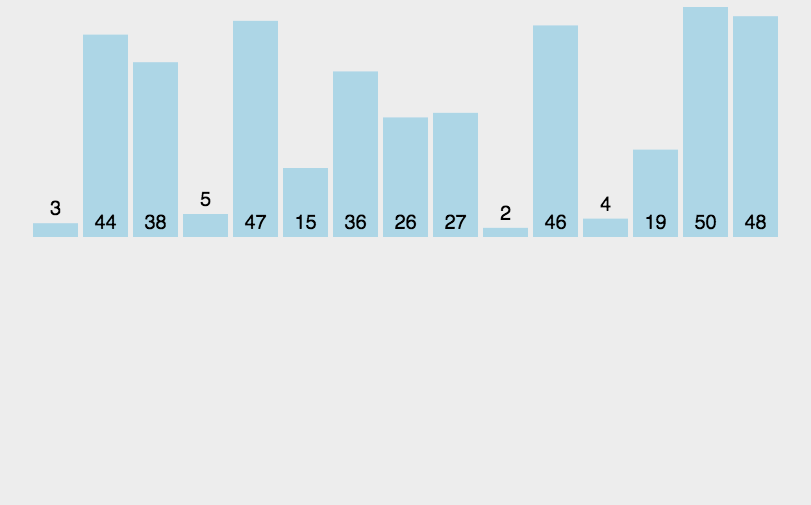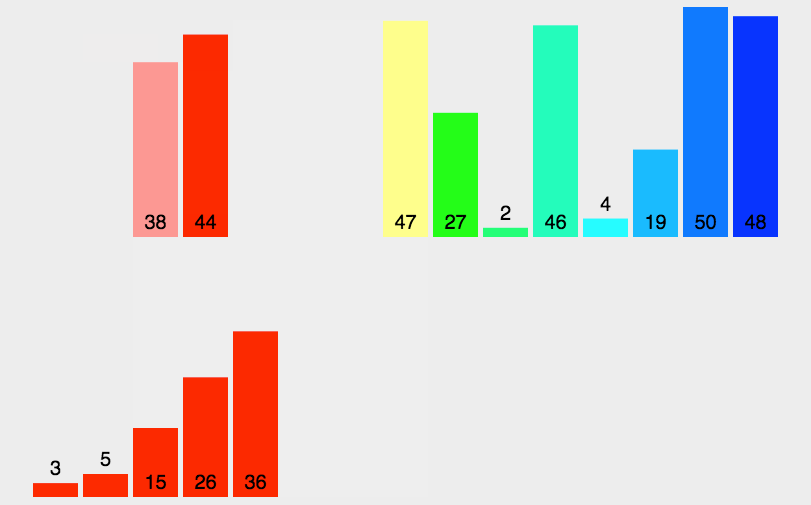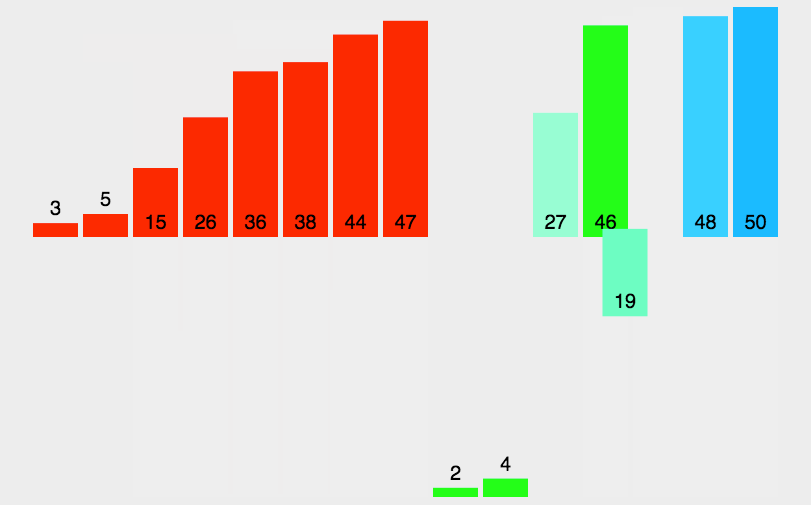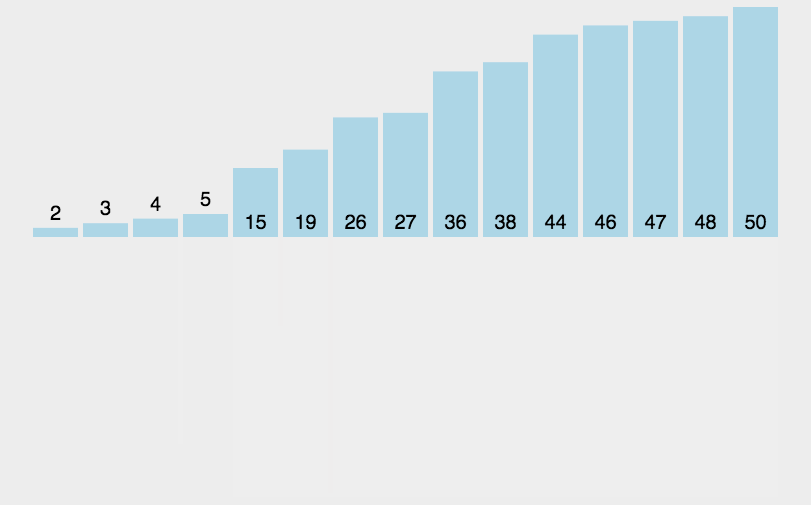
归并排序 与 逆序对数量
一、归并排序 题目: 给定你一个长度为 n 的整数数列,请你使用归并排序对这个数列按照从小到大进行排序,并将排好序的数列按顺序输出。
输入格式: 输入共两行,第一行包含整数 n。 第二行包含 n个整数(所有整…
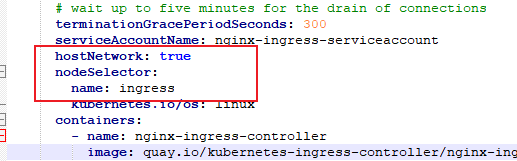
Kubernetes(k8s)入门:核心组件详解
文章目录 写在前面一、ReplicationController(RC)1、官方解释2、举个例子3、小总结 二、ReplicaSet(RS)1、官方解释2、举个例子 三、Deployment(用的最多)1、官方解释2、举个例子(1)创建nginx_deployment.yaml文件(2&a…
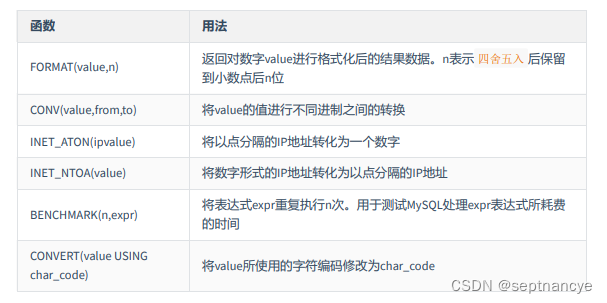
MySQL学习基础篇(七)---单行函数
MySQL学习基础篇(七)—单行函数
1 什么是函数
函数在计算机语言的使用中贯穿始终,函数的作用是什么呢?它可以把我们经常使用的代码封装起来,需要的时候直接调用即可。这样既 提高了代码效率 ,又 提高了可维护性 。在 SQL 中我们…
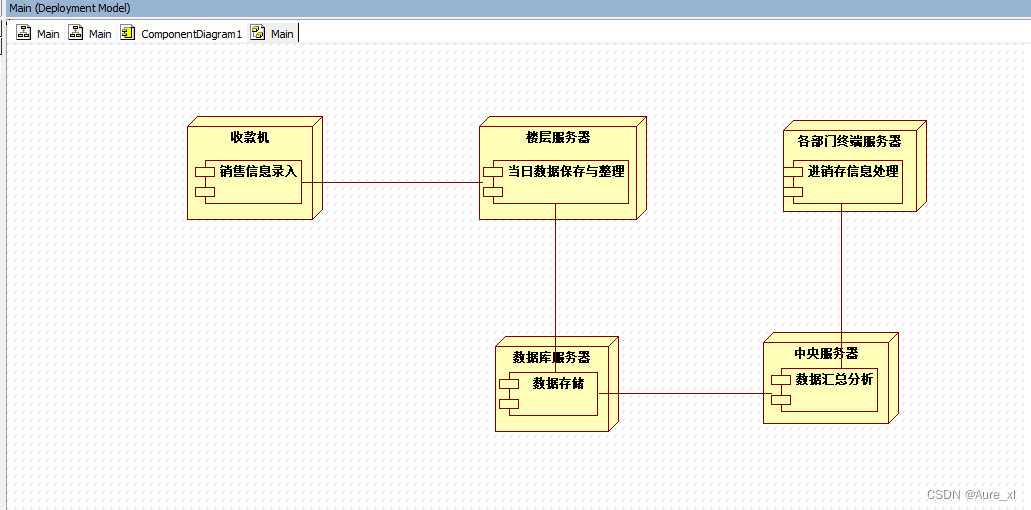
学习笔记整理-UML建模与应用复习4-构架建模
在一个更高的层次描述一个应用系统的结构,包括系统组件和组件之间的关系,组件的部署情况,以及硬件设备之间的关系。
1、组件图 用于描述功能所在的组件位置以及它们之间的关系。 包括:组件、接口、以及各种关系。可以显示…
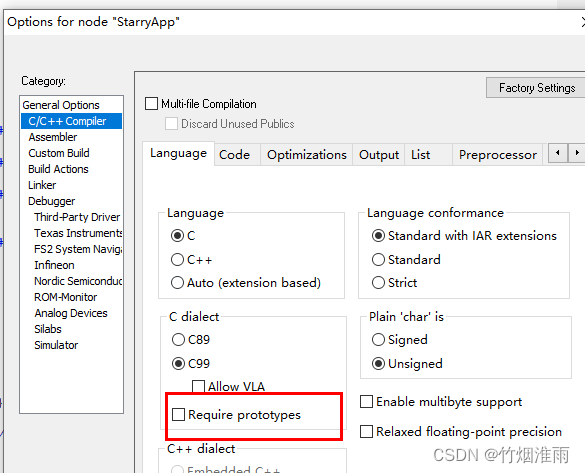
IAR中Zstack协议栈相关问题解决办法
IAR中Zstack协议栈相关问题解决办法
1、Warning[w52]: More than one definition for the byte at address 0x4b in common segment INTVEC.
如果遇到类似
Warning[w52]: More than one definition for the byte at address 0x4b in common segment INTVEC. It is defined i…
uniapp打包之配置MacOS虚拟机生成iOS打包证书
前言
uniapp是一款跨端开发框架,可用于快速开发iOS、Android、H5等多端应用。本文将详细介绍如何实现uniapp开发的iOS应用打包。
详细步骤
一、下载苹果原版镜像文件
点击此处下载
二、安装VMware
uniapp打包iOS应用需要生成相应证书和P2文件,这些都需要用到I…
android ChkBugReport 的安装
参考地址: https://github.com/sonyxperiadev/ChkBugReport/wiki/How-to-install-it
1:先下载下来 git clone https://github.com/sonyxperiadev/ChkBugReport.git
然后在把这两个下载下来
http://sonyxperiadev.github.io/ChkBugReport/download/chkbugreport (Launcher sh…
kotlin constructor init companion object 与初始化by lazy
kotlin constructor init companion object 与初始化by lazy class MyDemo(private var v: Int) {init {println("init $v")}constructor(m: Int, n: Int) : this(m) {println("constructor $m $n")}//只初始化一次companion object {private var TAG &qu…

spring工程的启动流程?bean的生命周期?提供哪些扩展点?管理事务?解决循环依赖问题的?事务传播行为有哪些?
1.Spring工程的启动流程:
Spring工程的启动流程主要包括以下几个步骤:
加载配置文件:Spring会读取配置文件(如XML配置文件或注解配置)来获取应用程序的配置信息。实例化并初始化IoC容器:Spring会创建并初…

台阶仪是干什么的?在太阳能光伏行业能测什么?
太阳能作为应用广、无排放、无噪声的环保能源,在近些年迎来快速发展,而在各类型的太阳能电池及太阳能充电系统中,多会镀一层透明的ITO导电薄膜,其镀膜厚度对电池片的导电性能有着非常重要的影响,因而需要对镀膜厚度进行…

IPETRONIK推出第三代测量模块,专为热管理、电动车测试打造
一 应用场景
车辆的热管理测试变得越来越重要,特别是在电动车领域,且精确的温度测量将给车辆的运行、性能以及乘客的舒适度带来直接影响。
• 热监测和验证;
• 气候控制系统的功能测试;
• 控制环路的监测;
• 发…
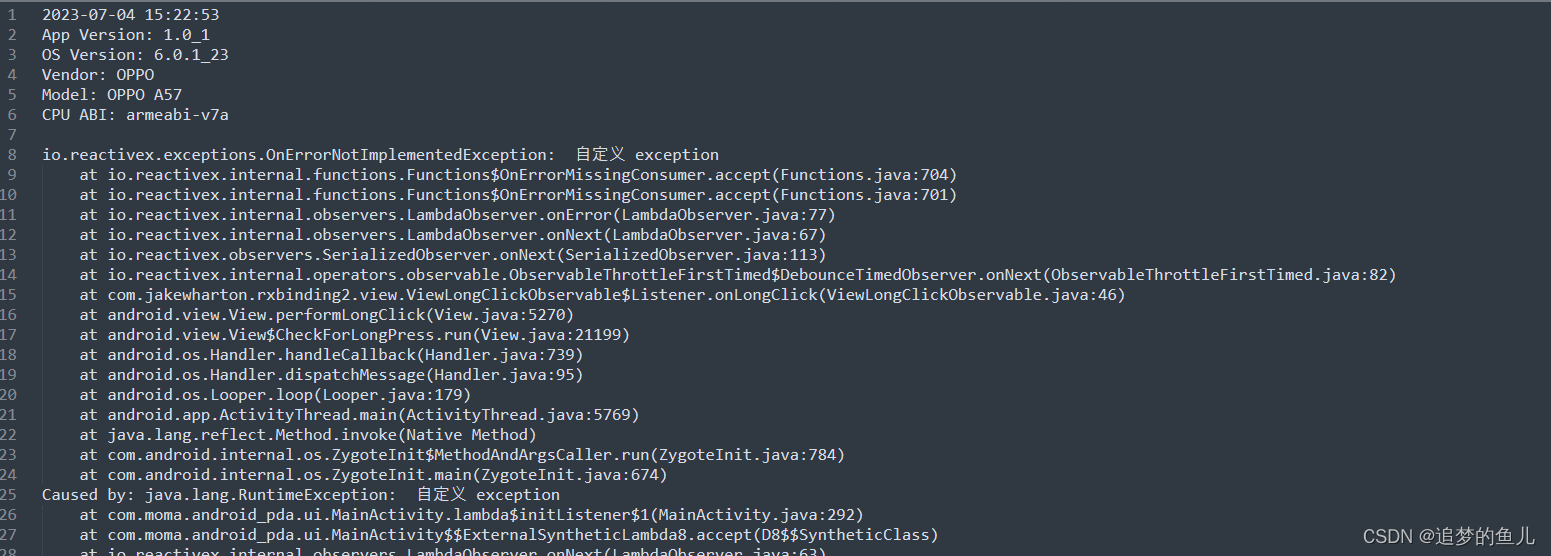
Android CrashHandler全局异常
CrashHandler 介绍
Android 应用不可避免的会发生crash 即崩溃,无论程序写的多好,都会不可避免的发生崩溃,可能是由底层引起的,也有可能是写的代码引起的。当crash发生时,系统会kill掉正在执行的程序,现象…

CMake静态库动态库的构建和链接
cmake的基础知识:CMakeLists常用命令,在这里不再赘述。 Windows平台下可用cmake-gui生成vs的.sln工程,Linux平台下可以运行cmake命令。
动态库和静态库的构建
现有C工程目录结构如下:
静态库的构建
add.h
#include <iost…

【kingbase数据库】kingbase查看所有表名
进入kingbase数据库,在数据库活动页面中选择要查询的数据库。 在SQL命令行工具中输入以下命令:
SELECT relname
FROM sys_class
WHERE relkind r
AND relnamespace (SELECT oid FROM sys_namespace WHERE nspname public);执行命令后,…
deeplabv3+源码之慢慢解析main.py(1)--get_argparser函数
deeplab v3源码 慢慢解析系列
本带着一些孩子们做,但本硕能独立看下来的学生不多。和孩子们一起再学一遍吧。希望孩子们和我自己都能坚持写下去吧。网上资料太多了,但不够慢,都是速成,没有足够的解释和补充,希望这次够…
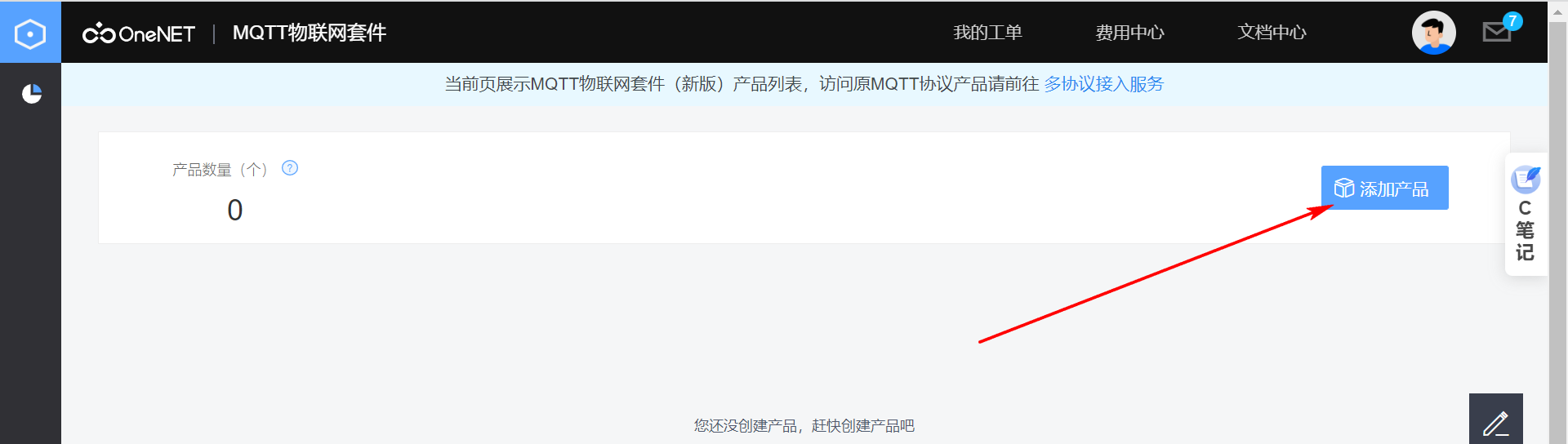
EC200u-cn-4G模块连接OneNet上传GPS定位数据(MQTT协议)
一、前言
这篇文章介绍EC200U-CN 4G模块通过MQTT协议上传GPS数据到OneNet平台,完成地图数据显示的过程。
当前的主控芯片采用MC9S12XS128MAA,通过串口连接EC200U-CN实现联网功能,通过内置的MQTT协议指令,将采集的GPS数据上传到OneNet平台,联合百度地图实现位置显示。
下…

C#(四十七)之关于流的异常
一:Try-catch-finally
声明文件对象要在 Try-catch-finally 结构体外边声明
声明在try中的对象有作用域问题,其并不能影响finally中的程序
在catch中显示程序错误代码。
在finally中释放程序,关闭文件流。
二:using语句
1&a…
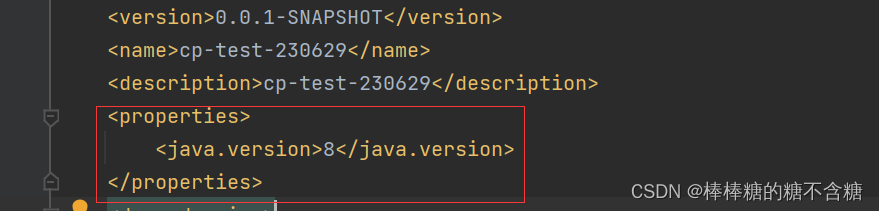
启动失败之JDK版本配置不一致
一、java: 警告: 源发行版 17 需要目标发行版 17
1.1.原因 :JDK 版本不对。 这里可以看到,项目需要的是JDK17,而我这里用的是JDK1.8。
1.2.修改 这里有两种操作,一种是修改项目版本,一种是修改JDK版本。无论是哪一种࿰…