文章目录
- 前言
- 突然崩了
- 排查问题
- 关于go的json库
- 什么是反射
- 解决大结构体序列化的性能问题
- 干掉大结构体
- 减少反射使用
- 一些好用的第三方序列化包
- 自定义序列化
- 写在最后
前言
一个风和日丽的下午,线上系统突然开始报警(系统温馨提示,您的服务接口响应耗时已突破1s )
(-_-|||)
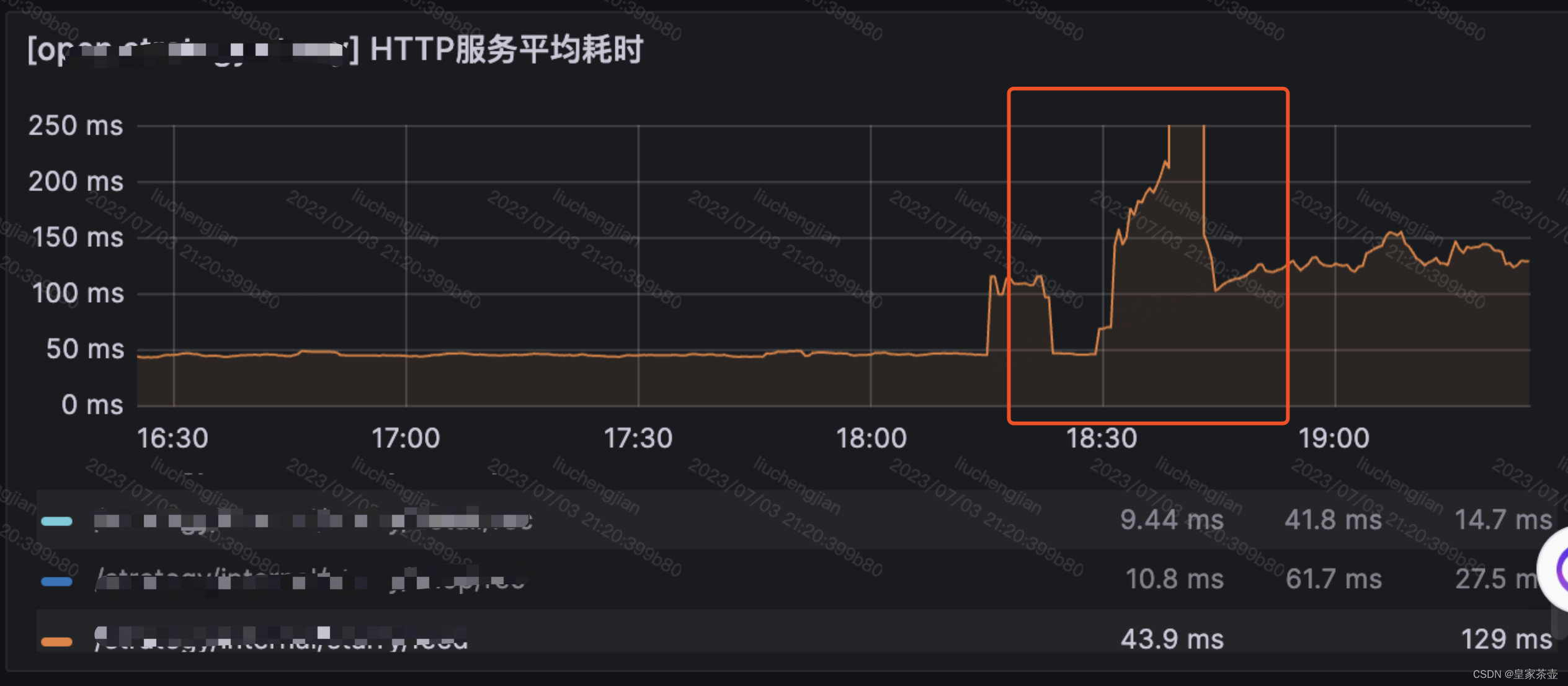
突破天际的耗时线(并且伴随着实例OOM重启问题)!!!
当时脑门汗蹭的一下的就冒出来了,趁老板没杀过来之前立马开始紧急排查处理~
突然崩了
由于最近没有发布,这波服务崩的莫名其妙,为了不影响线上业务,观察服务异常情况和资源监控后,首先对每个实例的资源配置进行了提升。
重新发布之后,系统算是稳定下来了,然而接口耗时仍然比出问题之前要高了接近2倍。
排查问题
针对服务性能异常的排查,笔者在之前的文章《线上GO服务出现GC故障,我当时就急了》 中已经提到过,这里就不再赘述。
通过pprof采样线上cpu耗时之后,锁定了有问题的代码片段
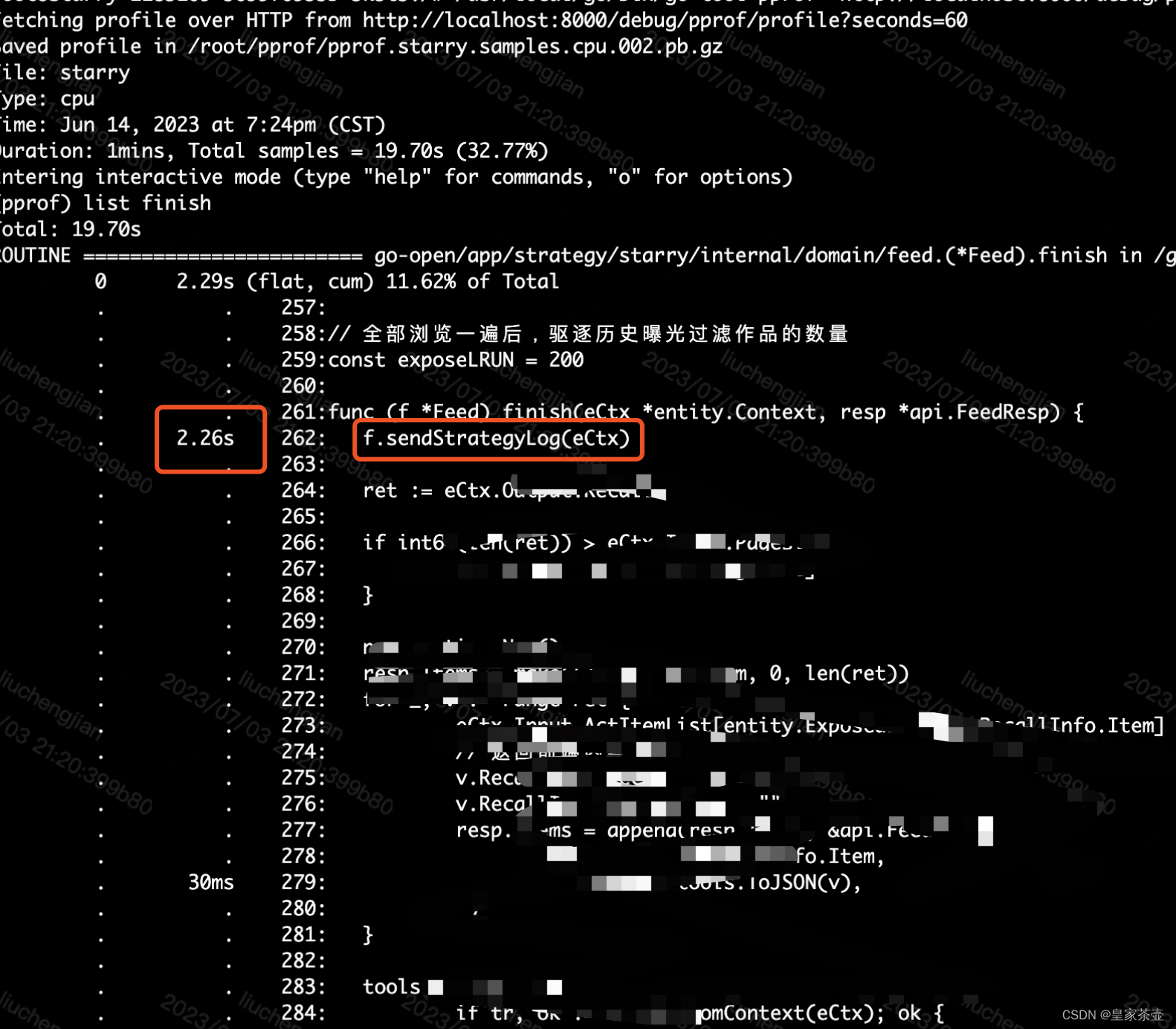
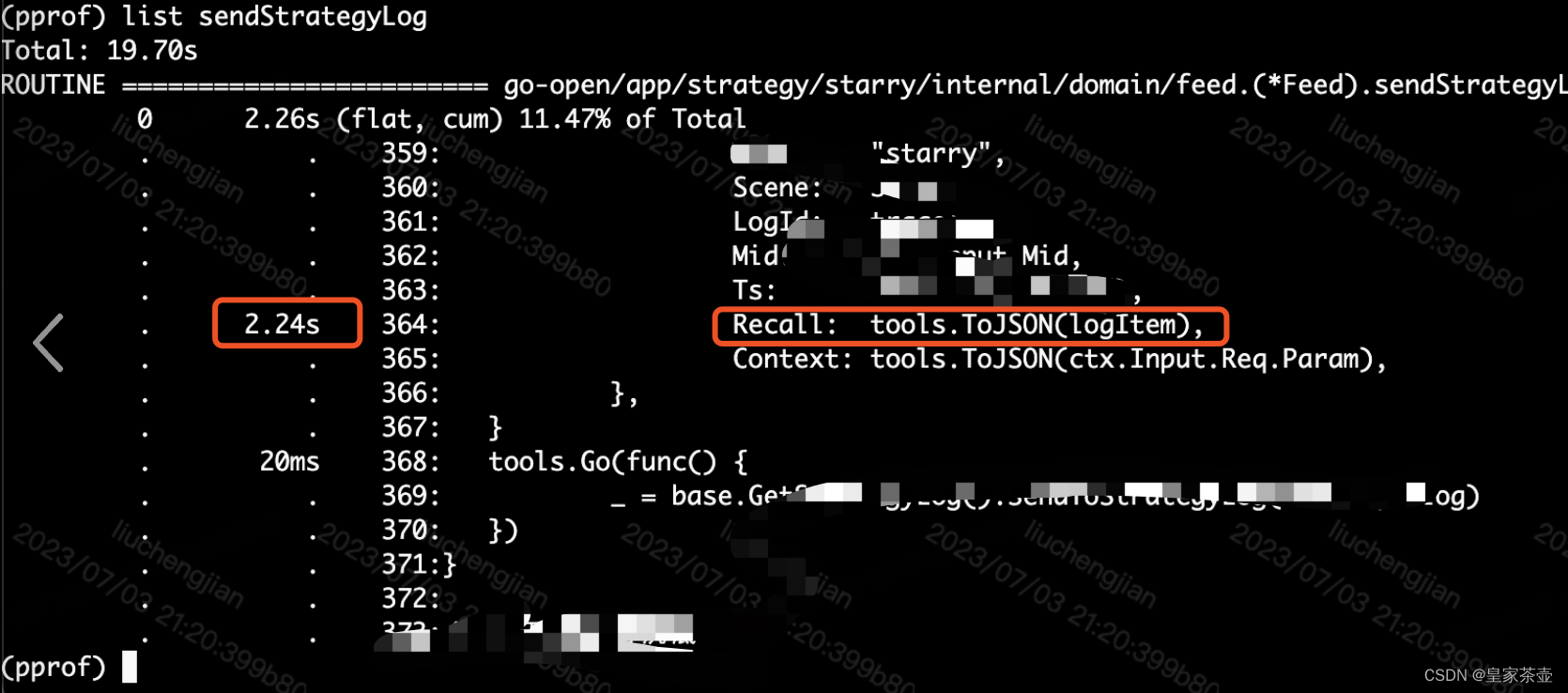
问题已经很明显了,由于上报结果集中需要序列化的结构体太大,占用了过多的CPU和内存资源,导致线上服务性能急剧下降,并且产生了OOM问题。
问题很快被修复了,但是也引发了笔者对于json序列化性能的思考:抛开常规的优化手段不谈,单从json序列化本身是否还有优化空间呢?
关于go的json库
这里不得不先向不了解的朋友们简单介绍一下go的标准json库 : )
Go 语言的标准 json 库是一个 encoding/json 包,它提供了一系列的 API 函数,用于从 Go 对象生成 json 文档,以及从 json 文档中填充 Go 对象。它的序列化和反序列化主要通过包中的 json.Marshal() 和 json.Unmarshal() 方法实现。
Go 语言中的 json 序列化过程不需要被序列化的对象预先实现任何接口,它会通过反射获取结构体或者数组中的值并以树形的结构递归地进行编码。
那么问题来了,首先需要明确的是,go中反射操作的性能是比较差的,而标准库恰好又大量使用反射获取值,较为耗费 CPU 配置;其次频繁分配对象,也会带来内存分配和 GC 的开销;
什么是反射
前面提到了go语言的反射,反射是什么,为什么反射操作会带来性能问题,这里给出一些简单的解释;
Go 的反射是指在运行时动态地获取和操作对象的类型和值的能力,它主要通过 reflect 包中的 Type 和 Value 类型来实现。Go 的反射比较耗性能的原因主要有以下几点:
- 反射操作需要调用一系列的函数,而不是直接访问内存地址,这会增加函数调用的开销和栈空间的占用。
- 反射操作需要使用类型断言和类型转换,这会增加运行时的类型检查和内存分配的开销。
- 反射操作需要使用反射包中的方法,而不是编译器优化过的内置方法,这会降低执行效率和缓存命中率。
- 反射操作需要使用递归和状态机等技术,这会增加逻辑复杂度和计算量。
根据一些性能测试,Go 的反射操作可能比正常操作慢几十倍甚至几百倍。因此,在不必要的情况下,应该尽量避免使用反射,或者使用一些高性能的反射库来优化反射性能。
解决大结构体序列化的性能问题
干掉大结构体
是的没错,如果解决不了问题,那么我们考虑解决引发问题的对象~(听着怪怪的)
思考一下为什么业务中会出现需要序列化大结构体的场景,是不是所有字段都是被需要的?服务中我们提倡按需加载,对于序列化也是一样的。
我们可以根据需要定一个专门用于序列化的结构体,该结构体中只包含我们需要的字段;
对于可迭代的数据结构来说,我们还可以进行分批处理,减少单次序列化的压力;
减少反射使用
如何这样还不够,又或者被序列化对象确实很大,那么我们可以考虑不使用标准json库,替换成其他底层实现中反射使用少或者完全不使用反射的第三方json库;
一些好用的第三方序列化包
关于第三方高性能json库的详细评测和使用建议,可以参考这篇文章:《探究|Go JSON 三方包哪家强?》
自定义序列化
如果不考虑泛用性,追求极致的性能的情况下,我们还可以祭出终极杀招,自定义序列化协议。
由于使用场景很小,这里简单抛砖引玉给出一个例子,我们可以基于go语言 encoding/binary 库对结构体进行轻量级序列化和反序列化。这种方式的优点是简单高效,缺点嘛也很明显,有一定的开发和维护成本
关于encoding/binary的更多使用姿势本篇就不多赘述了,下面上一个简单的序列化例子,小伙伴们自行感受下
package main
import (
"bytes"
"compress/gzip"
"encoding/base64"
"encoding/binary"
"fmt"
"io"
)
type User struct {
Name string
Age int64
IsSingle bool
}
type Encoder struct {
w io.Writer
}
func NewEncoder(w io.Writer) *Encoder {
return &Encoder{w: w}
}
func (e *Encoder) encode(user *User) {
_ = binary.Write(e.w, binary.LittleEndian, uint16(len(user.Name))) // 非固定长度数据需要定义读取长度
_ = binary.Write(e.w, binary.LittleEndian, []byte(user.Name))
_ = binary.Write(e.w, binary.BigEndian, user.Age)
_ = binary.Write(e.w, binary.LittleEndian, user.IsSingle)
}
type Decoder struct {
r io.Reader
}
func NewDecoder(r io.Reader) *Decoder {
return &Decoder{r: r}
}
func (d Decoder) decode(user *User) {
var namelen uint16
_ = binary.Read(d.r, binary.LittleEndian, &namelen)
nameBytes := make([]byte, namelen)
_ = binary.Read(d.r, binary.LittleEndian, &nameBytes)
user.Name = string(nameBytes)
var age int64
_ = binary.Read(d.r, binary.BigEndian, &age)
user.Age = age
var single bool
_ = binary.Read(d.r, binary.LittleEndian, &single)
user.IsSingle = single
}
func main() {
user1 := &User{
Name: "小A",
Age: 20,
IsSingle: true,
}
var buf bytes.Buffer
base64Writer := base64.NewEncoder(base64.StdEncoding, &buf)
compressor := gzip.NewWriter(base64Writer)
encoder := NewEncoder(compressor)
encoder.encode(user1) // 编码
_ = compressor.Close()
bin := buf.Bytes()
base64Reader := base64.NewDecoder(base64.StdEncoding, bytes.NewReader(bin))
decompressor, _ := gzip.NewReader(base64Reader)
decoder := NewDecoder(decompressor)
var newUser1 User
decoder.decode(&newUser1) // 解码
fmt.Println(newUser1)
}
写在最后
日常业务流程中,我们不可避免的需要与各种各样的序列化场景打交道(最常见的,日志上报),在使用序列化的过程中,我们需要时刻做到对数据量的把控,做到心中有数。避免出现因序列化缓影响线上正常业务请求。
问题解决,可以安心睡一觉了~~