目录
七、数值查找
1、Excel实现
2、Python实现
八、区间切分
1、Excel实现
2、Python实现
九、插入新的行或列
1、Excel实现
2、Python实现
十、行列互换
1、Excel实现
2、Python实现
十一、索引重塑
十二、长宽表转换
1、宽表转换为长表
(1)stack()方法实现
(2)melt()方法实现
2、长表转换为宽表
3、apply()与applymap()函数
七、数值查找
数值查找就是查看数据表中的数据是否包含某个值或者某些值。
1、Excel实现
在Excel中我们要想查看数据表中是否包含某个值可以直接利用查找功能。首先要把待查找区域选中,可以选择一列或者多列,如果不选,则默认在全表中查询,然后单击编辑菜单栏的查找和选择按钮,在下拉菜单中选择查找选项。.
可以使用快捷键Ctrl+F打开查找和替换对话框,在查找内容框输入要查找的内容即可,可以选择查找全部,这样就会把所有查找到的内容显示出来,也可以选择查找下一个,这样会把查找结果一个一个显示出来。
2、Python实现
在Python中查看数据表中是否包含某个值用到的是isin()方法,而且可以同时查找多个值,只需要在isin()方法后的括号中指明即可。
可以将某列数据取出来,然后在这一列上调用isin()方法,看这一列是否包含某个/些值,如果包含则返回True,否则返回False。
八、区间切分
区间切分就是将一系列数值分成若干份,比如现在有10个人,你要根据这10个人的年龄将他们分为三组,这个切分过程就称为区间切分。
1、Excel实现
在Excel中实现区间切分我们借助的是if函数,具体公式如下:
=if(D2<4,"<4",IF(D2<7,"4-6",">=7"))
2、Python实现
在Python中对区间切分咯用的是cut()方法,cut()方法有一个参数bins用来指明切分区间。
cut()方法的切分结果是几个左开右闭的区间,(0,3]就表示大于0小于等于3,(3,6]表示大于3小于等于6,(6,10]表示大于6小于等于10 。
与cut()方法类似的还有qcut()方法,qcunt()方法不需要实现指明切分区间,只需要指明切分个数,即你要把待切分数据切成几份,然后它就会根据待切分数据的情况,将数据切分成实现指定的份数,依据的原则就是每个组里面的数据个数尽可能相等。
在数据分布比较均匀的情况下,cut()方法得到的区间基本一致,当数据分布不均匀,即方差比较大时,两者得到的区间的偏差就会比较大。
九、插入新的行或列
在特定的位置插入行或者列也是比较常用的操作。具体的插入操作有两个关键要素,一个是在哪插入,另一个是插入什么。
1、Excel实现
在Excel中要插入行或列首先要确定在哪一行或哪一列前面插入,然后选中这一列或这一行单击鼠标右键,在弹出的下拉菜单中选择插入选项即可。
2、Python实现
在Python中没有专门用来插入行的方法,可以把待插入的行当作一个新的表,然后将两个表在纵轴方向上进行拼接。
在Python中插入一个新的列用到的方法是insert(),在insert方法后的括号中指明要插入的位置、插入后新列的列名,以及要插入的数据。
还可以直接以索引的方式进行列的插入,直接让新的一列等于某列值即可。
十、行列互换
所谓的行列互换(又称转置)就是将行数据转换到列方向上,将列数据转换到行方向上。
1、Excel实现
在Excel中行列互换(转置)需要先把待转置的内容复制,然后粘贴在新的区域中,粘贴选项选择转置即可。转置选项如下图所示:

2、Python实现
在Python中,我们直接在源数据表的基础上调用.T方法即可得到数据表转置后的结果。对转置后的结果再次转置就会回到原来的结果。
十一、索引重塑
所谓的索引重塑就是将原来的索引进行重新构造。典型的DataFrame结构的表如下表所示:
| C1 | C2 | C3 | |
| S1 | 1 | 2 | 3 |
| S2 | 4 | 5 | 6 |
上面这种表是典型的DataFrame结构,它用一个行索引和一个列索引来确定一个唯一值,比如S1-C1唯一值为1,S2-C3唯一值为6。这种通过两个位置确定一个唯一值的方法不仅可以用上述这表表格型结构表示,而且可以用一种树形结构表示。
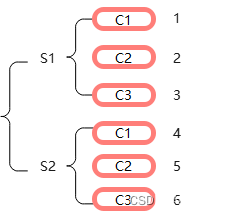
树形结构其实就是在维持表格型行索引不变的前提下,把列索引也变成行索引,其实就是给表格型数据建立层次化索引。
我们把数据从表格型数据转换到树形数据的过程叫重塑,这种操作在Excel中没有,在Python用到的方法是stack()。
与stack()方法相对应的方法是unstack()方法,stack()方法是将表格型数据转化为树形数据,而unstack()方法是将树形数据转为表格型数据。
十二、长宽表转换
长宽表转换就是将比较长(很多行)的表转换为比较宽(很多列)的表,或者将比较宽的表转化为比较长的表。
下表是一个宽表(有很多列)
| company | name | sale2013 | sale2014 | sale2015 | sale2016 |
| apple | 苹果 | 5000 | 5050 | 5050 | 5050 |
| 谷歌 | 3500 | 3800 | 3800 | 3800 | |
| | 脸书 | 2300 | 2900 | 2900 | 2900 |
我们要把这个宽表转化为如下表所示的长表。
| company | name | year | sale |
| apple | 苹果 | sale2013 | 5000 |
| 谷歌 | sale2013 | 3500 | |
| | 脸书 | sale2013 | 2300 |
| apple | 苹果 | sale2014 | 5050 |
| 谷歌 | sale2014 | 3800 | |
| | 脸书 | sale2014 | 2900 |
| apple | 苹果 | sale2015 | 5050 |
| 谷歌 | sale2015 | 3800 | |
| | 脸书 | sale2015 | 2900 |
| apple | 苹果 | sale2016 | 5050 |
| 谷歌 | sale2016 | 3800 | |
| | 脸书 | sale2016 | 2900 |
上面这种由很多列转换为很多行的过程,就是宽表转换为长表的过程,这种转换过程是有前提的,那就是需要有公共列。
1、宽表转换为长表
宽表转化为长表,在Excel中一般都用复制粘贴实现,我们主要看看在Python中如何实现。Python中要实现这种转换有两种方法,一种是stack()方法,另一种是melt()方法。
(1)stack()方法实现
stack()在将表格型数据转为树形数据时,是在保持行索引不变的前提下,将列索引也变成行索引。
这里将宽表转化为长表首先要在保持company和name不变的前提下,将sale2013、sale2014、sale2015、sale2016也变成行索引。所以,需要先将company和name先设置成索引,然后调用stack()方法,将列索引也转换成行索引,最后利用reset_index()方法进行索引重置。
df.set_index(["company","name"])
df.set_index(["company","name"]).stack()
df.set_index(["company","name"]).stack().reset_index()(2)melt()方法实现
用melt()方法实现上述功能,代码如下所示。
df.melt(id_vars = ["company","name"],
var_name = "year",
value_name = "sale")melt中的id_vars参数用于指明宽表转换到长表时保持不变的列,var_name参数表示原来的列索引转化为“行索引”以后对应的列名,value_name表示新索引对应的值的列名。
注意,这里的“行索引”是有双引号的,它并非实际行索引,只是类似实际的行索引。
2、长表转换为宽表
将长表转换为宽表就是宽表转化为长表的逆过程。常用的方法就是数据透视表。
df.pivot_table(index = ["company","name"],columns = "year",values = "sale")上面的实现过程是把company和name设置成行索引,year设置成列索引,sale为值。
3、apply()与applymap()函数
我们在Python基础知识部分讲过一个Python的高级特性map()函数,map()函数是对一个序列中的所有元素执行相同的函数操作。
在dataframe中与map()函数类似的函数有两个,一个是apply()函数,另一个是applymap()函数。函数apply()和applymap()都需要与匿名函数Iambda结合使用。
apply()函数主要用于对dataframe中的某一column或row()中的元素执行相同的函数操作。
applymap()函数用于对dataframe中的每一个元素执行相同的函数操作。