| import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.*;
import java.util.stream.Collectors;
/**
* @author liuya
*/
public class NaiveBayesModel {
//样本数据
private static List<List<String>> data = new ArrayList<>();
//样本数据
private static Set<List<String>> dataSet = new HashSet<>();
//分类模型
public static Map<String,String> modelMap = new HashMap<>();
//样本数据集
private static String path = "./src/data.txt";
public static void main(String[] args) {
//训练模型
trainingModel();
//识别
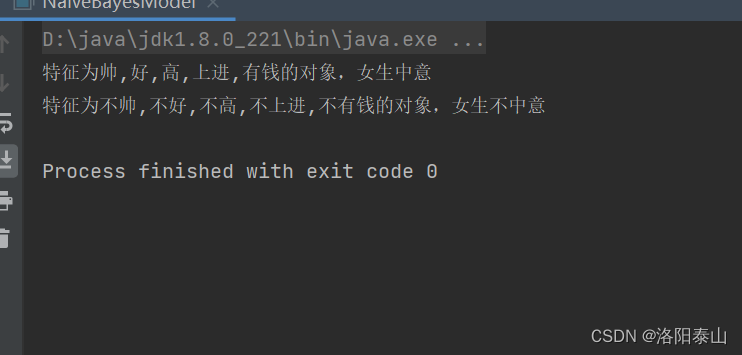
classification("帅","好","高","上进","有钱");
classification("不帅","不好","不高","不上进","不有钱");
}
/**
* 导入数据
* @param path
* @return
*/
public static void readData(String path){
List<String> row = null;
try {
InputStreamReader isr = new InputStreamReader(new FileInputStream(new File(path)));
BufferedReader br = new BufferedReader(isr);
String str = null;
while((str = br.readLine()) != null){
row = new ArrayList<>();
String[] str1 = str.split(",");
for(int i = 0; i < str1.length ; i++) {
row.add(str1[i]);
}
dataSet.add(row);
data.add(row);
}
br.close();
isr.close();
} catch (Exception e) {
e.printStackTrace();
System.out.println("读取文件内容出错!");
}
}
public static void trainingModel() {
readData(path);
String category1="中意";
String category2="不中意";
dataSet.forEach(e->{
double categoryP1= calculateBayesian(e.get(0),e.get(1),e.get(2),e.get(3),e.get(4),category1);
double categoryP2= calculateBayesian(e.get(0),e.get(1),e.get(2),e.get(3),e.get(4),category2);
String result=categoryP1>categoryP2?category1:category2;
modelMap.put(e.get(0)+"-"+e.get(1)+"-"+e.get(2)+"-"+e.get(3)+"-"+e.get(4),result);
});
}
/**
* 分类的识别
* */
public static void classification(String look, String character, String height, String progresses, String wealthy){
String key=look+"-"+character+"-"+height+"-"+progresses+"-"+wealthy;
String result=modelMap.get(key);
System.out.println("特征为"+look+","+character+","+height+","+progresses+","+wealthy+"的对象,女生"+result);
}
/**
* 分类的核心是比较朴素贝叶斯的结果值,结果值大的认为就属于该分类(会有误差,数据集量越大,结果判定的准确率就会越高)由于分母相同可以直接比较分子来确定分类
* */
public static double calculateBayesian(String look, String character, String height, String progresses, String wealthy,String category) {
//获取P(x|y)的分母
// double denominator = getDenominator(look,character,height,progresses,wealthy);
//获取P(x|y)的分子
double molecule = getMolecule(look,character,height,progresses,wealthy,category);
return molecule/1;
}
/**
* 获取p(x|y)分子
* @return
*/
public static double getMolecule(String look, String character, String height, String progresses, String wealthy,String category) {
double resultCP = getProbability(5, category);
double lookCP = getProbability(0, look, category);
double characterCP = getProbability(1, character, category);
double heightCP = getProbability(2, height, category);
double progressesCP = getProbability(3, progresses, category);
double wealthyCP = getProbability(4, wealthy, category);
return lookCP * characterCP * heightCP * progressesCP * wealthyCP * resultCP;
}
/**
* 获取p(x|y)分母
* @return
*/
public static double getDenominator(String look, String character, String height, String progresses, String wealthy) {
double lookP = getProbability(0, look);
double characterP = getProbability(1, character);
double heightP = getProbability(2, height);
double progressesP = getProbability(3, progresses);
double wealthyP = getProbability(4, wealthy);
return lookP * characterP * heightP * progressesP * wealthyP;
}
/**
* 获取某特征的概率
* @return
*/
private static double getProbability(int index, String feature) {
int size = data.size();
int num = 0;
for (int i = 0; i < size; i++) {
if (data.get(i).get(index).equals(feature)) {
num++;
}
}
return (double) num / size;
}
/**
* 获取某类别下某特征的概率
* @return
*/
private static double getProbability(int index, String feature, String category) {
List<List<String>> filterData=data.stream().filter(e -> e.get(e.size() - 1).equals(category)).collect(Collectors.toList());
int size =filterData.size();
int num = 0;
for (int i = 0; i < size; i++) {
if (data.get(i).get(index).equals(feature)) {
num++;
}
}
return (double) num / size;
}
}
|