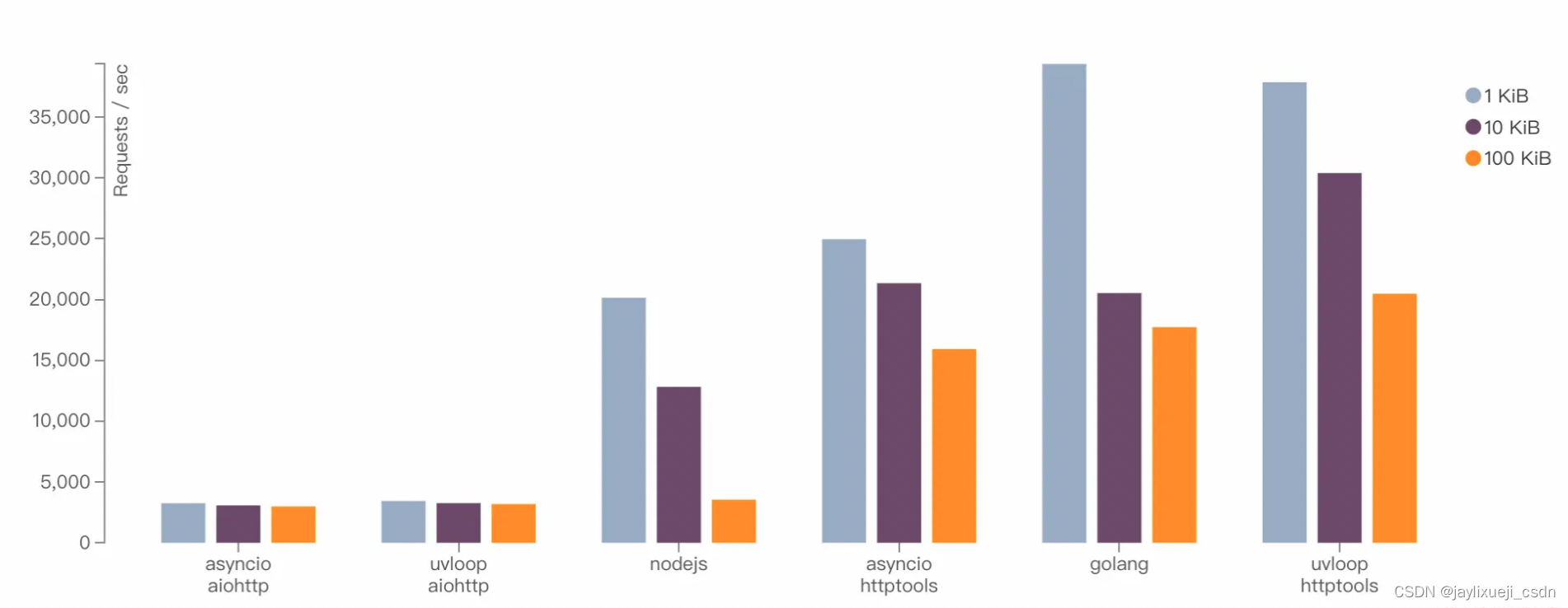
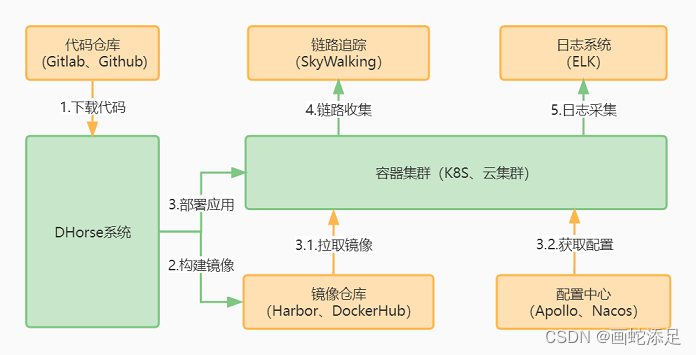
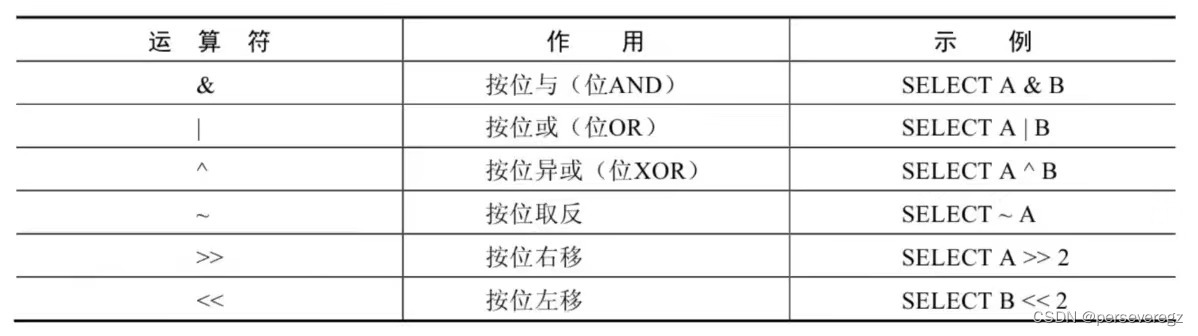
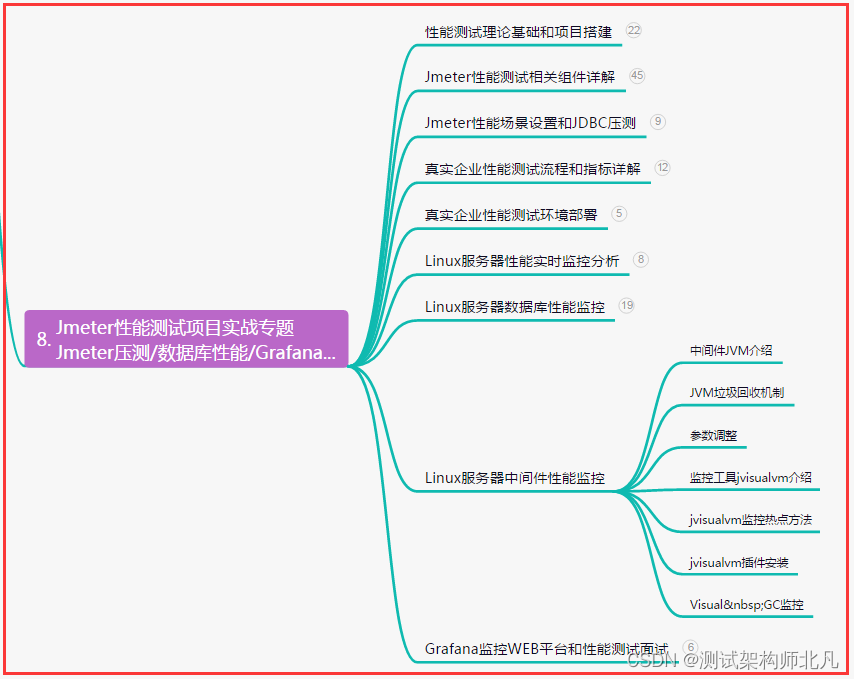
1.手写Flink的UV
手写Flink的UV
2.Flink的分组TopN
Flink的分组TopN
3.Spark的分组TopN
1)方法1:
(1)按照key对数据进行聚合(groupByKey)
(2)将value转换为数组,利用scala的sortBy或者sortWith进行排序(mapValues)数据量太大,会OOM。
2)方法2:
(1)取出所有的key
(2)对key进行迭代,每次取出一个key利用spark的排序算子进行排序
方法3:
(1)自定义分区器,按照key进行分区,使不同的key进到不同的分区
(2)对每个分区运用spark的排序算子进行排序
Spark的分组TopN![]() http://t.csdn.cn/Jh1PB
http://t.csdn.cn/Jh1PB
4.如何快速从40亿条数据中快速判断,数据123是否存在
答:解决方案:申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。dizengrong: 方案2:因为2^32为40亿多,所以给定一个数可能在,也可能不在其中;这里我们把40亿个数中的每一个用32位的二进制来表示假设这40亿个数开始放在一个文件中。然后将这40亿个数分成两类: 1.最高位为0 2.最高位为1 并将这两类分别写入到两个文件中,其中一个文件中数的个数<=20亿,而另一个>=20亿(这相当于折半了);与要查找的数的最高位比较并接着进入相应的文件再查找再然后把这个文件为又分成两类: 1.次最高位为0 2.次最高位为1并将这两类分别写入到两个文件中,其中一个文件中数的个数<=10亿,而另一个>=10亿(这相当于折半了); 与要查找的数的次最高位比较并接着进入相应的文件再查找。 ....... 以此类推,就可以找到了,而且时间复杂度为O(logn),方案2完。
5.给你100G数据,1G内存,如何排序?
内存只有 1G,需要排序的数据有 100G
因为内存中因为无法把所有数据全部放下,所以需要外部排序,而归并排序是最常用的外部排序
1. 先把文件切分成 200 份,每个 512 M
2. 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以
3. 进行 200 路归并,同时对 200 份有序文件做归并过程,最终结果就有序了
七大排序知识点 http://t.csdn.cn/D47GE
http://t.csdn.cn/D47GE
6.公平调度器容器集中在同一个服务器上?
不会
7.匹马赛跑,1个赛道,每次5匹进行比赛,无法对每次比赛计时,但知道每次比赛结果的先后顺序,最少赛多少次可以找出前三名?
匹马赛跑,1个赛道,每次5匹进行比赛,无法对每次比赛计时,但知道每次比赛结果的先后顺序,最少赛多少次可以找出前三名?![]() http://t.csdn.cn/VheIs
http://t.csdn.cn/VheIs
8. 给定一个点、一条线、一个三角形、一个有向无环图,请用java面向对象的思想进行建模
给定一个点、一条线、一个三角形、一个有向无环图,请用java面向对象的思想进行建模![]() http://t.csdn.cn/sDaJ2
http://t.csdn.cn/sDaJ2
9.HQL场景题
尚大自研刷题网站的网址![]() http://forum.atguigu.cn/interview.html
http://forum.atguigu.cn/interview.html
10.一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析
答: 解决方案:方案1:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(n*le)(le表示单词的平准长度)。然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(n*lg10)。所以总的时间复杂度,是O(n*le)与O(n*lg10)中较大的哪一个。
11.给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url
答:解决方案:方案1:可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。通读文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999)中。这样每个小文件的大约为300M。通读文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,...,b999)。这样处理后,所有可能相同的url都在对应的小文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2:如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)。