学习目标:
latent-diffusion 代码
学习时间:
2023.06.17 - 2023.06.30
学习产出:
一、代码
1、前置知识:PyTorch Lightning执行顺序
执行顺序:
trainer.fit(model):开始训练模型。
prepare_data():准备数据集。
setup():设置数据集和其他变量。
train_dataloader():返回一个训练数据加载器。
val_dataloader():返回一个验证数据加载器。
test_dataloader():返回一个测试数据加载器。
on_epoch_start():在每个训练轮次开始时被调用。
on_train_batch_start():在每个训练批次开始时被调用。
training_step():执行一个训练步骤。
backward():计算梯度。
optimizer_step():更新模型参数。
on_after_backward():在反向传播后被调用。
on_train_batch_end():在每个训练批次结束时被调用。
on_epoch_end():在每个训练轮次结束时被调用。
on_batch_end():在每个批次结束时被调用。
on_test_batch_start():在每个测试批次开始时被调用。
test_step():执行一个测试步骤。
on_test_batch_end():在每个测试批次结束时被调用。
on_test_end():在测试结束时被调用。
on_fit_end():在训练结束时被调用。
执行顺序应该是:prepare_data() -> setup() -> train_dataloader() -> val_dataloader() -> test_dataloader() -> on_epoch_start() ->
on_train_batch_start() -> training_step() -> backward() -> optimizer_step() -> on_after_backward() -> on_train_batch_end() ->
on_epoch_end() -> on_batch_end() -> on_test_batch_start() -> test_step() -> on_test_batch_end() -> on_test_end() -> on_fit_end()
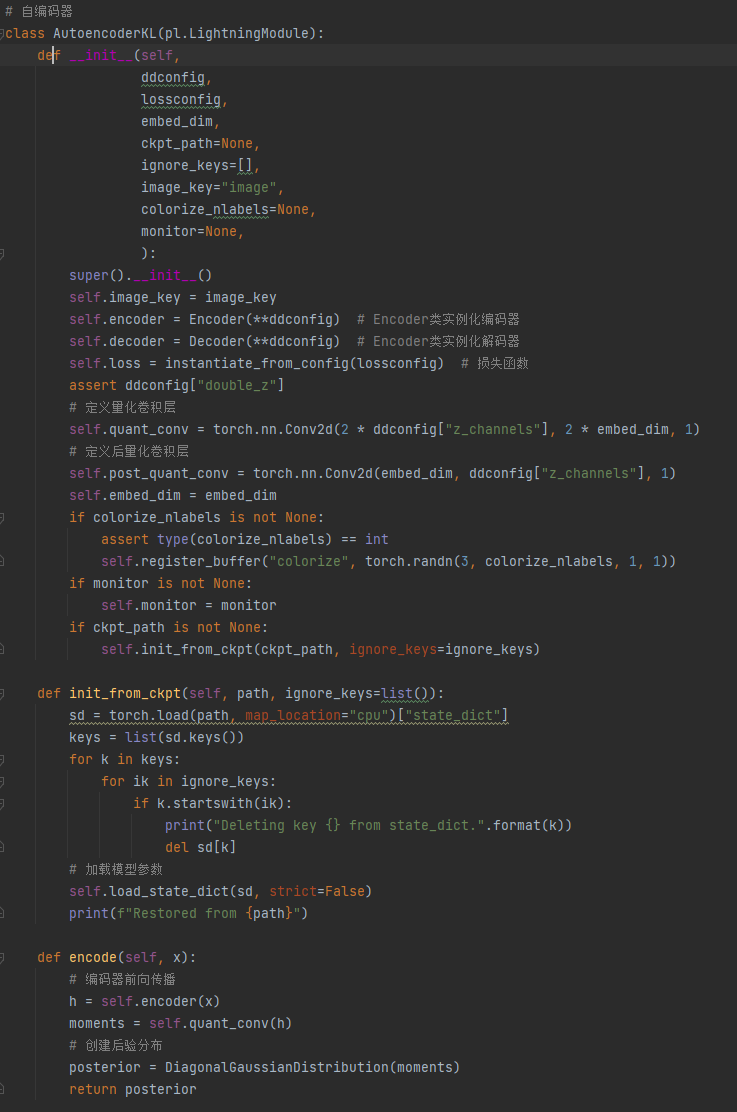
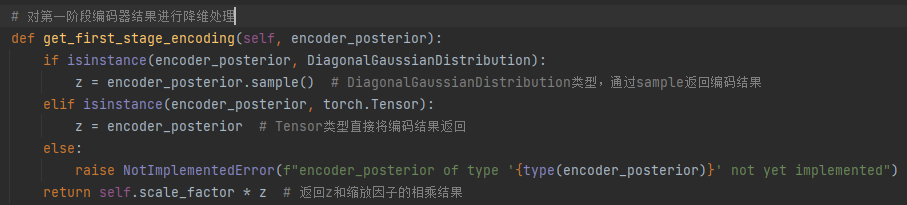
2、on_train_batch_start:获取图像,调用自编码器AutoencoderKL的encoder()将图像压缩至潜在空间,然后通过 get_first_stage_encoding()降维后获取图像的特征向量z
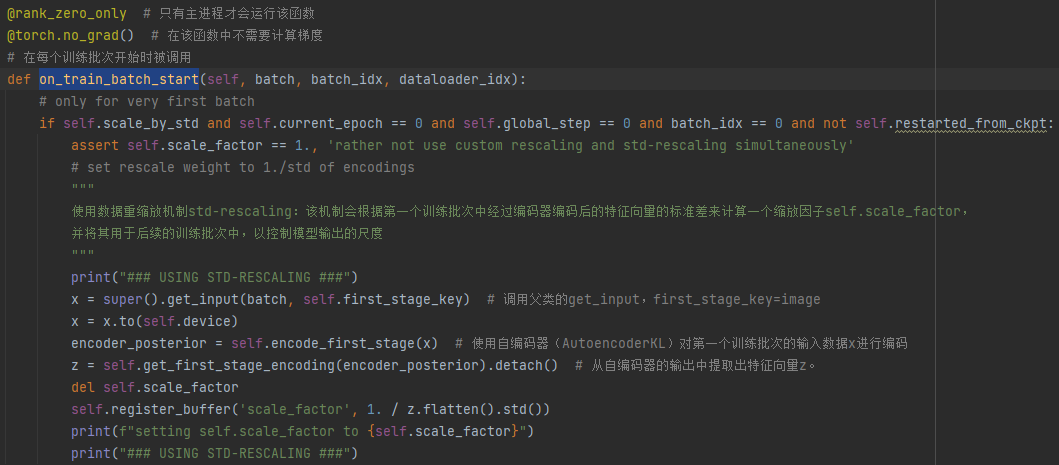
3、调用父类的training_step(),然后调用子类的shared_step()和子类的get_input()返回自编码器编码后的图像,再调用子类的forward()函数中的get_learned_conditioning()函数获取条件编码后的条件向量(get_learned_conditioning通过调用BERTEmbedder的BERTTokenizer将text编码),最后将特征向量和条件向量输入p_losses计算loss
traitraining_step
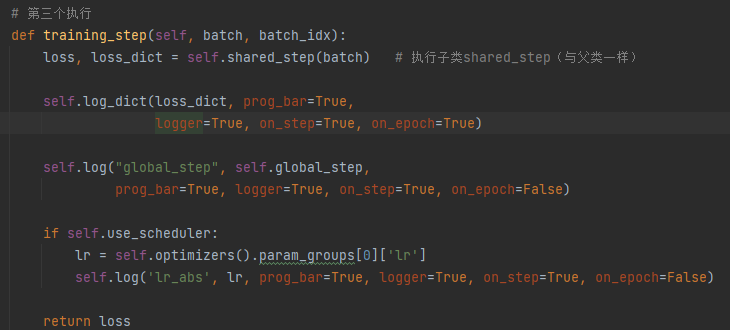
shared_step
get_input返回特征向量
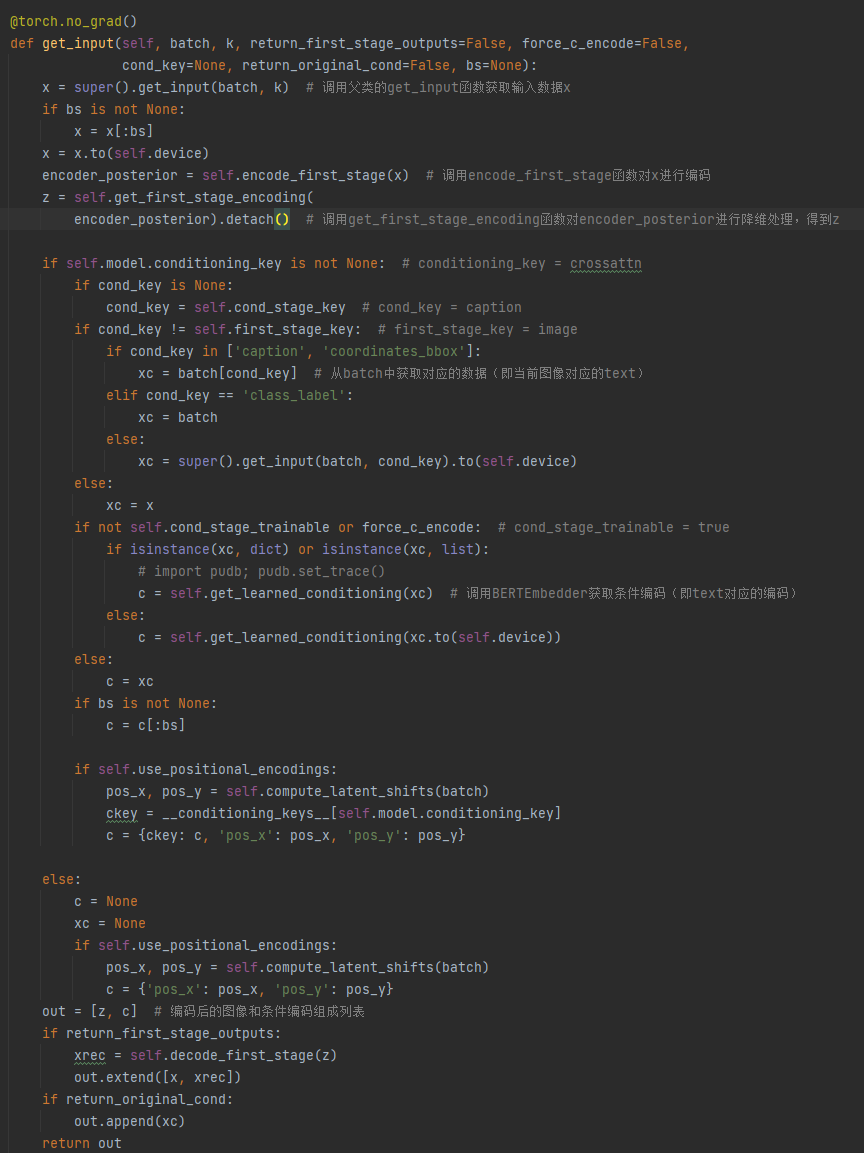
forward获取条件向量后将特征向量和条件向量的列表传入p_losses()
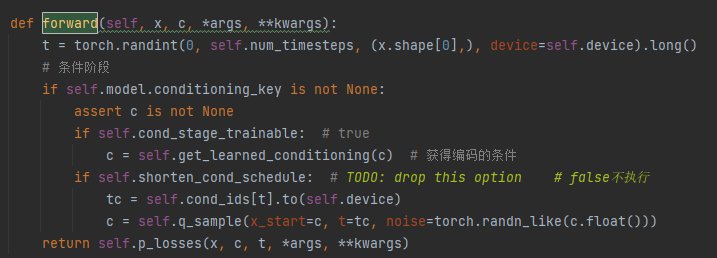
get_learned_conditioning调用BERTEmbedder
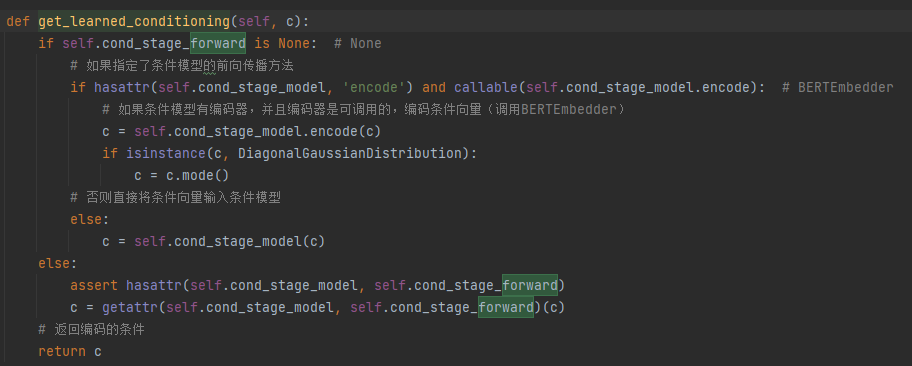
BERTEmbedder将文本编码为向量

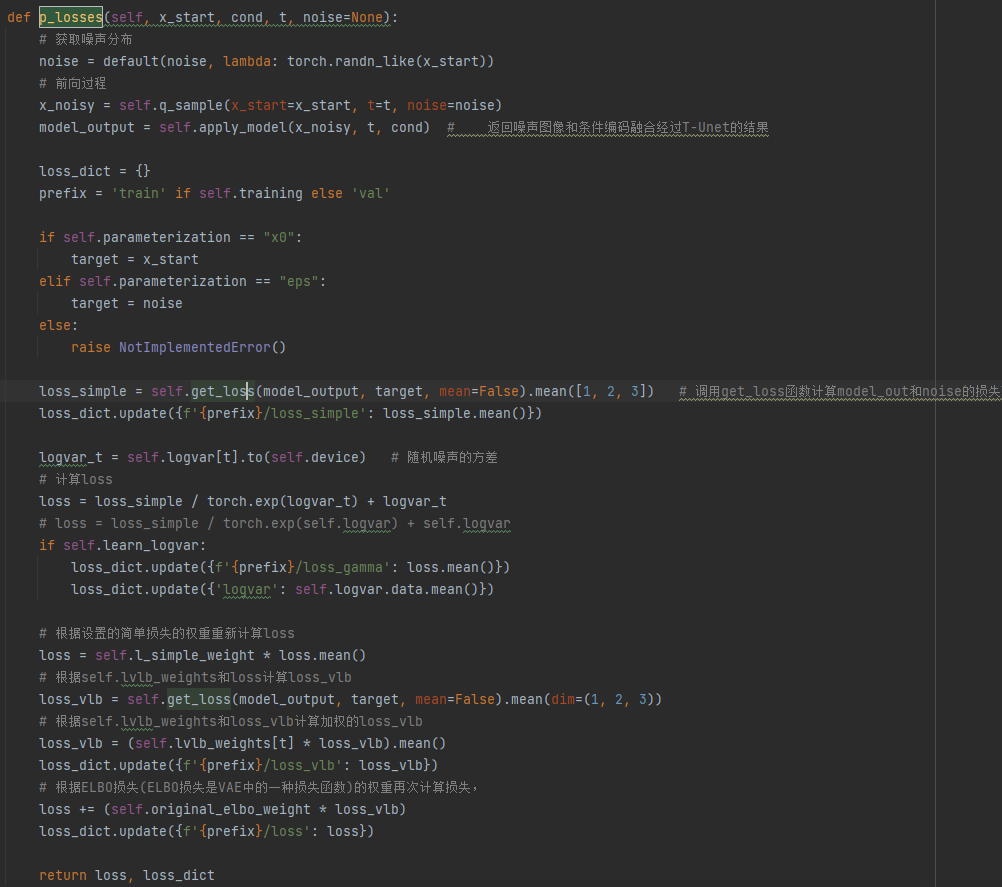
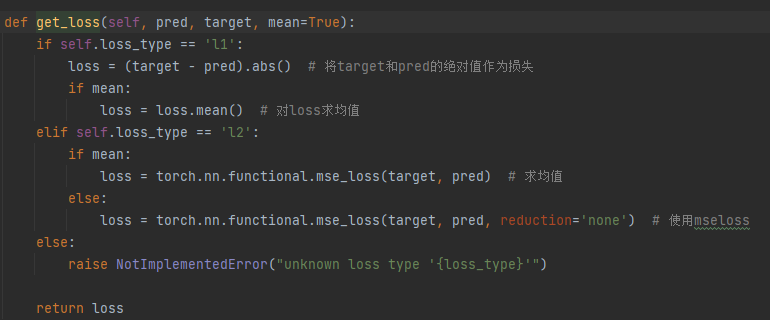
loss计算:p_losses()函数首先将特征向量z进行前向扩散,然后将噪声图像和条件向量使用self.apply_model输入T-Unet模型进行融合(通过Cross-Attention),最后通过get_loss()计算loss,将损失在第2、3、4(c,h,w)维度上求平均得到loss_simple,再经过简单损失的权重和ELBO损失权重的计算得到最终loss
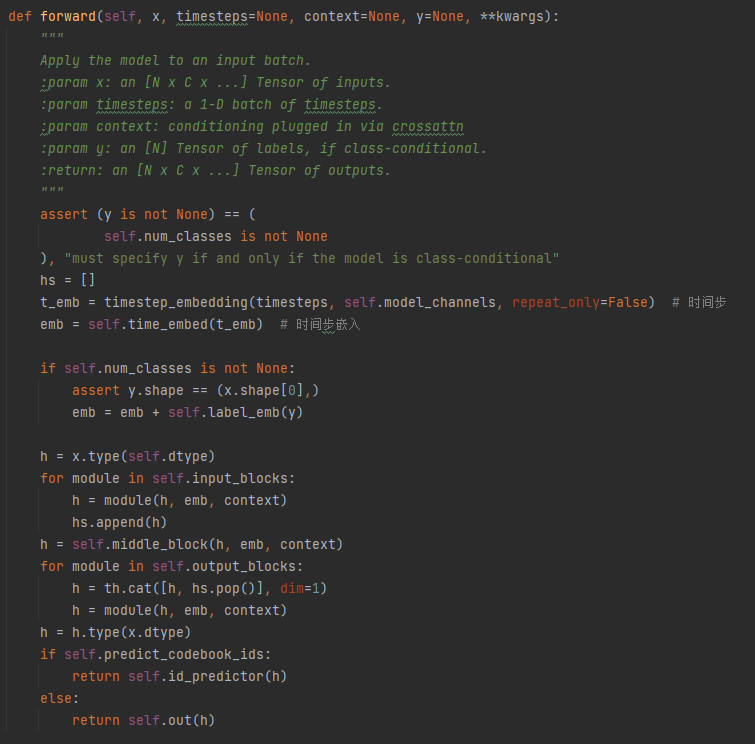
apply_model:调用Unet将条件向量和噪声图像融合
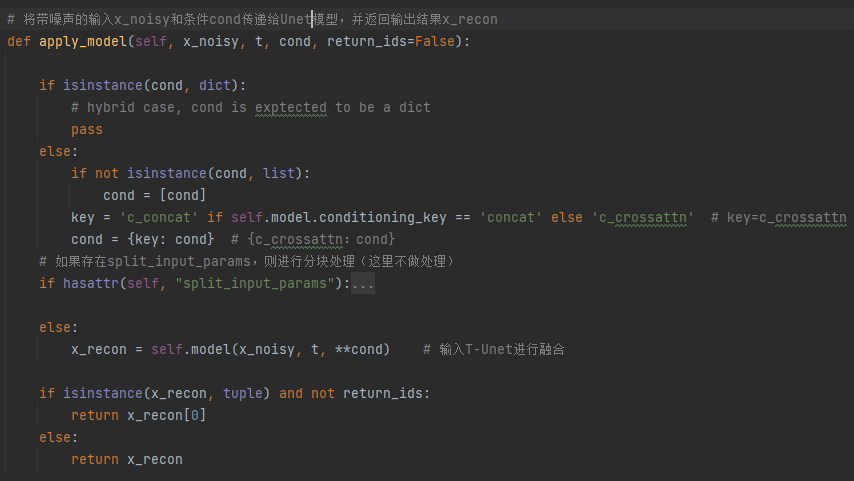
DiffusionWrapper:将条件向量作为上下文输入,通过Cross-Attention在Unet中和图像融合
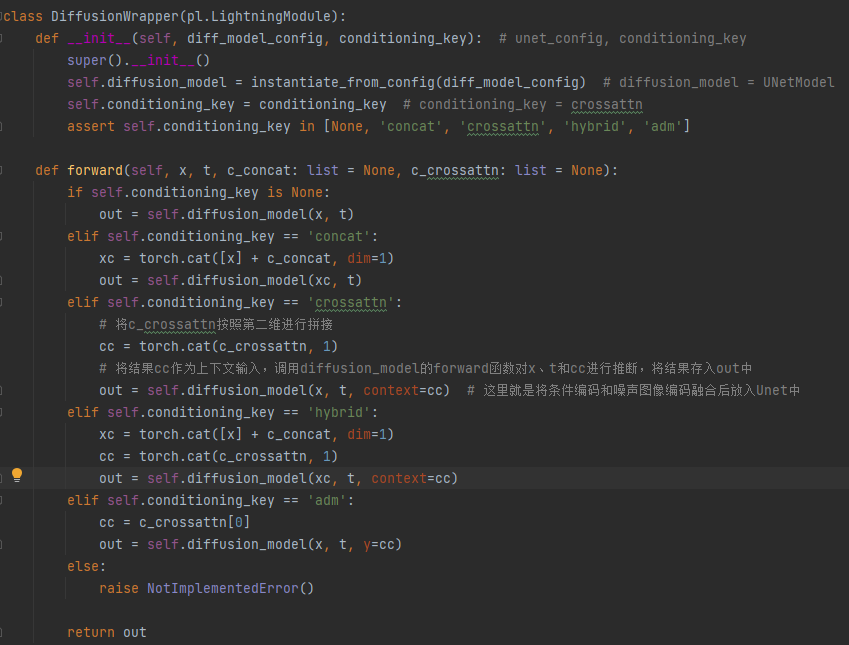
Unet的forward()函数
get_loss():计算loss
最后的梯度更新,参数更新及梯度归零则是框架自行计算。