🔥 跟着梁哥打卡一波spark的性能调优~
文章目录
- 1、Spark调优原理与步骤
- 2、Spark任务UI监控
- 3、Spark调优案例
- 3.1、资源配置优化
- 3.2、利用缓存减少重复计算
- 3.3、数据倾斜调优
- 3.4、broadcast+map代替join
- 3.5、reduceByKey/aggregateByKey代替groupByKey
1、Spark调优原理与步骤

🔥 如果程序执行太慢,调优的顺序一般如下:
-
1、首先调整任务并行度,并调整partition分区。 -
2、尝试定位可能的重复计算,并优化之。 -
3、尝试定位数据倾斜问题或者计算倾斜问题并优化之。 -
4、如果shuffle过程提示堆外内存不足,考虑调高堆外内存。 -
5、如果发生OOM或者GC耗时过长,考虑提高executor-memory或降低executor-core。
🔥以下是对上述公式中涉及到的一些概念的初步解读,建议可以初步过一眼,直接跳到调优案例部分看代码,遇到不会的概念再回头看这里。
任务计算总时间: 假设由一台无限内存的同等CPU配置的单核机器执行该任务,所需要的运行时间。通过缓存避免重复计算,通过mapPartitions代替map以减少诸如连接数据库,预处理广播变量等重复过程,都是减少任务计算总时间的例子。
shuffle总时间: 任务因为reduceByKey,join,sortBy等shuffle类算子会触发shuffle操作产生的磁盘读写和网络传输的总时间。shuffle操作的目的是将分布在集群中多个节点上的同一个key的数据,拉取到同一个节点上,以便让一个节点对同一个key的所有数据进行统一处理。shuffle过程首先是前一个stage的一个shuffle write即写磁盘过程,中间是一个网络传输过程,然后是后一个stage的一个shuffle read即读磁盘过程。shuffle过程既包括磁盘读写,又包括网络传输,非常耗时。因此如有可能,应当避免使用shuffle类算子。例如用map+broadcast的方式代替join过程。退而求其次,也可以在shuffle之前对相同key的数据进行归并,减少shuffle读写和传输的数据量。此外,还可以应用一些较为高效的shuffle算子来代替低效的shuffle算子。例如用reduceByKey/aggregateByKey来代替groupByKey。最后,shuffle在进行网络传输的过程中会通过netty使用JVM堆外内存,spark任务中大规模数据的shuffle可能会导致堆外内存不足,导致任务挂掉,这时候需要在配置文件中调大堆外内存。
GC垃圾回收总时间: 当JVM中execution内存不足时,会启动GC垃圾回收过程。执行GC过程时候,用户线程会终止等待。因此如果execution内存不够充分,会触发较多的GC过程,消耗较多的时间。在spark2.0之后excution内存和storage内存是统一分配的,不必调整excution内存占比,可以提高executor-memory来降低这种可能。或者减少executor-cores来降低这种可能(这会导致任务并行度的降低)。
任务有效并行度: 任务实际上平均被多少个core执行。它首先取决于可用的core数量。当partition分区数量少于可用的core数量时,只会有partition分区数量的core执行任务,因此一般设置分区数是可用core数量的2倍以上20倍以下。此外任务有效并行度严重受到数据倾斜和计算倾斜的影响。有时候我们会看到99%的partition上的数据几分钟就执行完成了,但是有1%的partition上的数据却要执行几个小时。这时候一般是发生了数据倾斜或者计算倾斜。这个时候,我们说,任务实际上有效的并行度会很低,因为在后面的这几个小时的绝大部分时间,只有很少的几个core在执行任务。
任务并行度: 任务可用core的数量。它等于申请到的executor数量和每个executor的core数量的乘积。可以在spark-submit时候用num-executor和executor-cores来控制并行度。此外,也可以开启spark.dynamicAllocation.enabled根据任务耗时动态增减executor数量。虽然提高executor-cores也能够提高并行度,但是当计算需要占用较大的存储时,不宜设置较高的executor-cores数量,否则可能会导致executor内存不足发生内存溢出OOM。
partition分区数量: 分区数量越大,单个分区的数据量越小,任务在不同的core上的数量分配会越均匀,有助于提升任务有效并行度。但partition数量过大,会导致更多的数据加载时间,一般设置分区数是可用core数量的2倍以上20倍以下。可以在spark-submit中用spark.default.parallelism来控制RDD的默认分区数量,可以用spark.sql.shuffle.partitions来控制SparkSQL中给shuffle过程的分区数量。
数据倾斜度: 数据倾斜指的是数据量在不同的partition上分配不均匀。一般来说,shuffle算子容易产生数据倾斜现象,某个key上聚合的数据量可能会百万千万之多,而大部分key聚合的数据量却只有几十几百个。一个partition上过大的数据量不仅需要耗费大量的计算时间,而且容易出现OOM。对于数据倾斜,一种简单的缓解方案是增大partition分区数量,但不能从根本上解决问题。一种较好的解决方案是利用随机数构造数量为原始key数量1000倍的中间key。大概步骤如下,利用1到1000的随机数和当前key组合成中间key,中间key的数据倾斜程度只有原来的1/1000, 先对中间key执行一次shuffle操作,得到一个数据量少得多的中间结果,然后再对我们关心的原始key进行shuffle,得到一个最终结果。
计算倾斜度: 计算倾斜指的是不同partition上的数据量相差不大,但是计算耗时相差巨大。考虑这样一个例子,我们的RDD的每一行是一个列表,我们要计算每一行中这个列表中的数两两乘积之和,这个计算的复杂度是和列表长度的平方成正比的,因此如果有一个列表的长度是其它列表平均长度的10倍,那么计算这一行的时间将会是其它列表的100倍,从而产生计算倾斜。计算倾斜和数据倾斜的表现非常相似,我们会看到99%的partition上的数据几分钟就执行完成了,但是有1%的partition上的数据却要执行几个小时。计算倾斜和shuffle无关,在map端就可以发生。计算倾斜出现后,一般可以通过舍去极端数据或者改变计算方法优化性能。
堆内内存: on-heap memory, 即Java虚拟机直接管理的存储,由JVM负责垃圾回收GC。由多个core共享,core越多,每个core实际能使用的内存越少。core设置得过大容易导致OOM,并使得GC时间增加。
堆外内存: off-heap memory, 不受JVM管理的内存, 可以精确控制申请和释放, 没有GC问题。一般shuffle过程在进行网络传输的过程中会通过netty使用到堆外内存。
2、Spark任务UI监控
🔥 复习一下先:
在Spark中,一个job是由一个或多个stage组成的,而一个stage又由一个或多个task组成。每个task都会被分配给一个executor来执行。因此,job和executor之间的关系可以描述为:
-
1、当一个job被提交到Spark集群时,Spark会将job分解为多个stage,并将每个stage分解为多个task。
-
2、Spark会将每个task分配给一个executor来执行。executor是一个运行在集群中的进程,负责执行task并将结果返回给驱动程序。
-
3、每个executor都会启动一个或多个线程来执行task。线程之间会共享executor的资源,例如内存和CPU。
-
4、一个executor可以执行多个task,但每个task只能由一个executor执行。
-
5、当一个task执行完成后,executor会将结果返回给驱动程序,并将资源释放给其他task使用。
因此,可以看出,job和executor之间的关系是一对多的关系,一个job可以由多个executor来执行,而一个executor可以执行多个task。这种分布式的执行方式可以大大提高Spark的计算效率和处理能力。
Spark UI监控界面:
- spark程序启动后,可以在浏览器中输入 http://localhost:4040/ 进入到spark web UI 监控界面。
- 该界面中可以从多个维度以直观的方式非常细粒度地查看Spark任务的执行情况,包括任务进度,耗时分析,存储分析,shuffle数据量大小等。
- 包括spark代码报错了,也是可以去查log看具体哪里报错的。
- 最常查看的页面是 Stages页面和Executors页面。
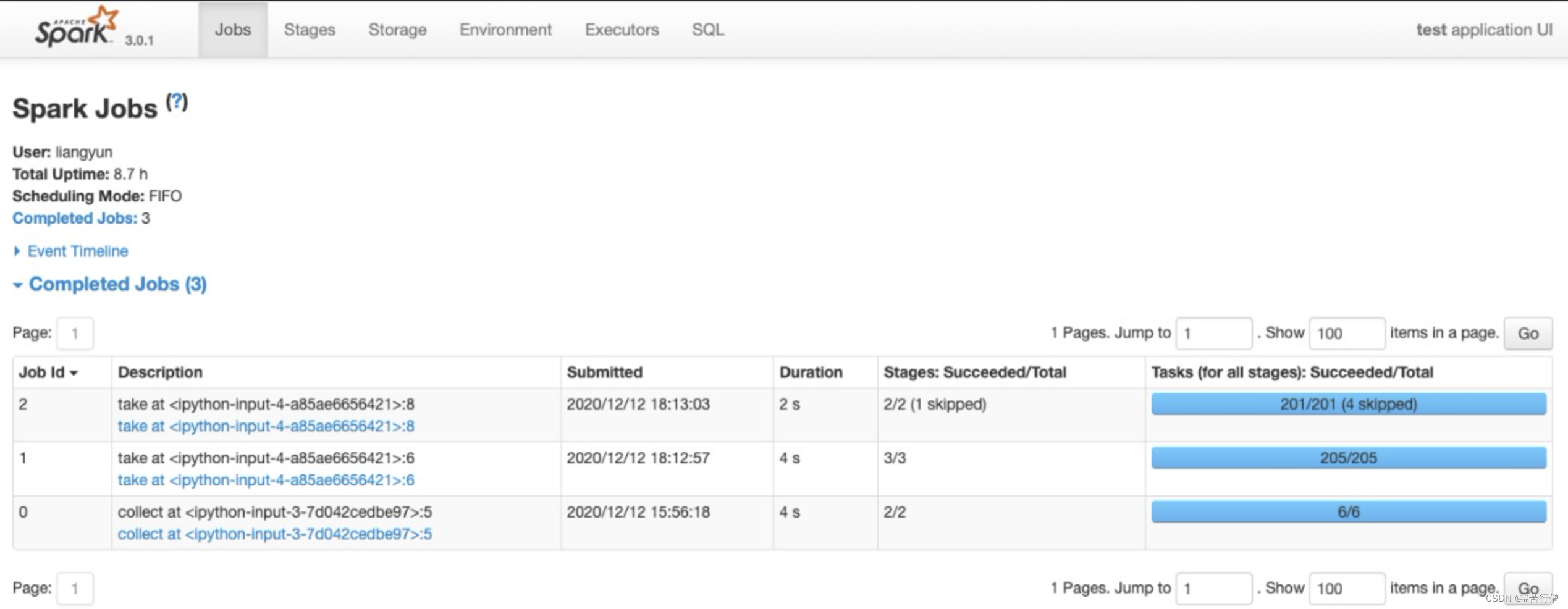
🔥 Jobs:每一个Action操作对应一个Job,以Job粒度显示Application进度。有时间轴Timeline。
🔥 Stages:Job在遇到shuffle切开Stage,显示每个Stage进度,以及shuffle数据量。
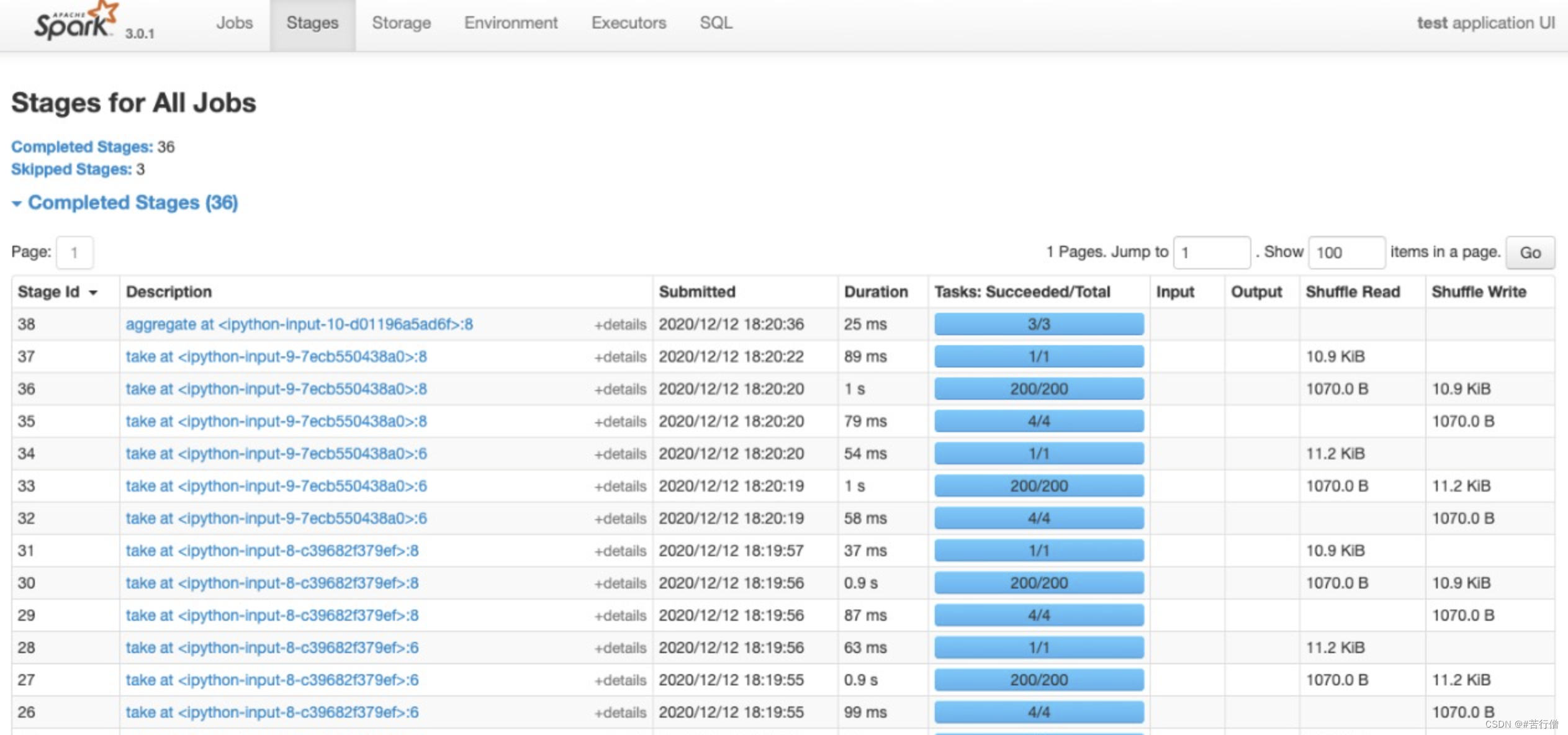
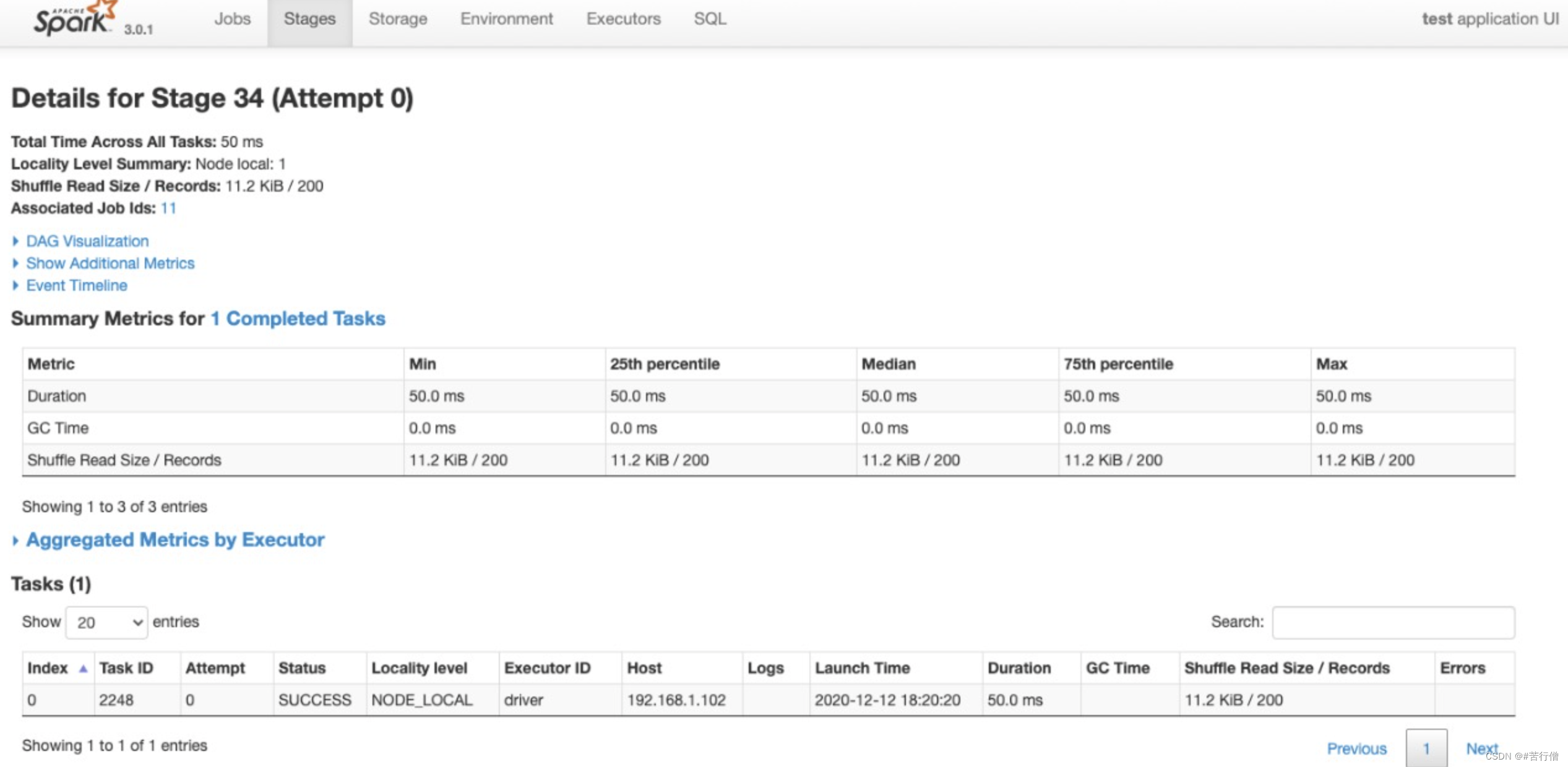
可以点击某个Stage进入详情页,查看其下面每个Task的执行情况以及各个partition执行的费时统计。
🔥 Storage:
监控cache或者persist导致的数据存储大小。
🔥 Environment:
显示spark和scala版本,依赖的各种jar包及其版本。
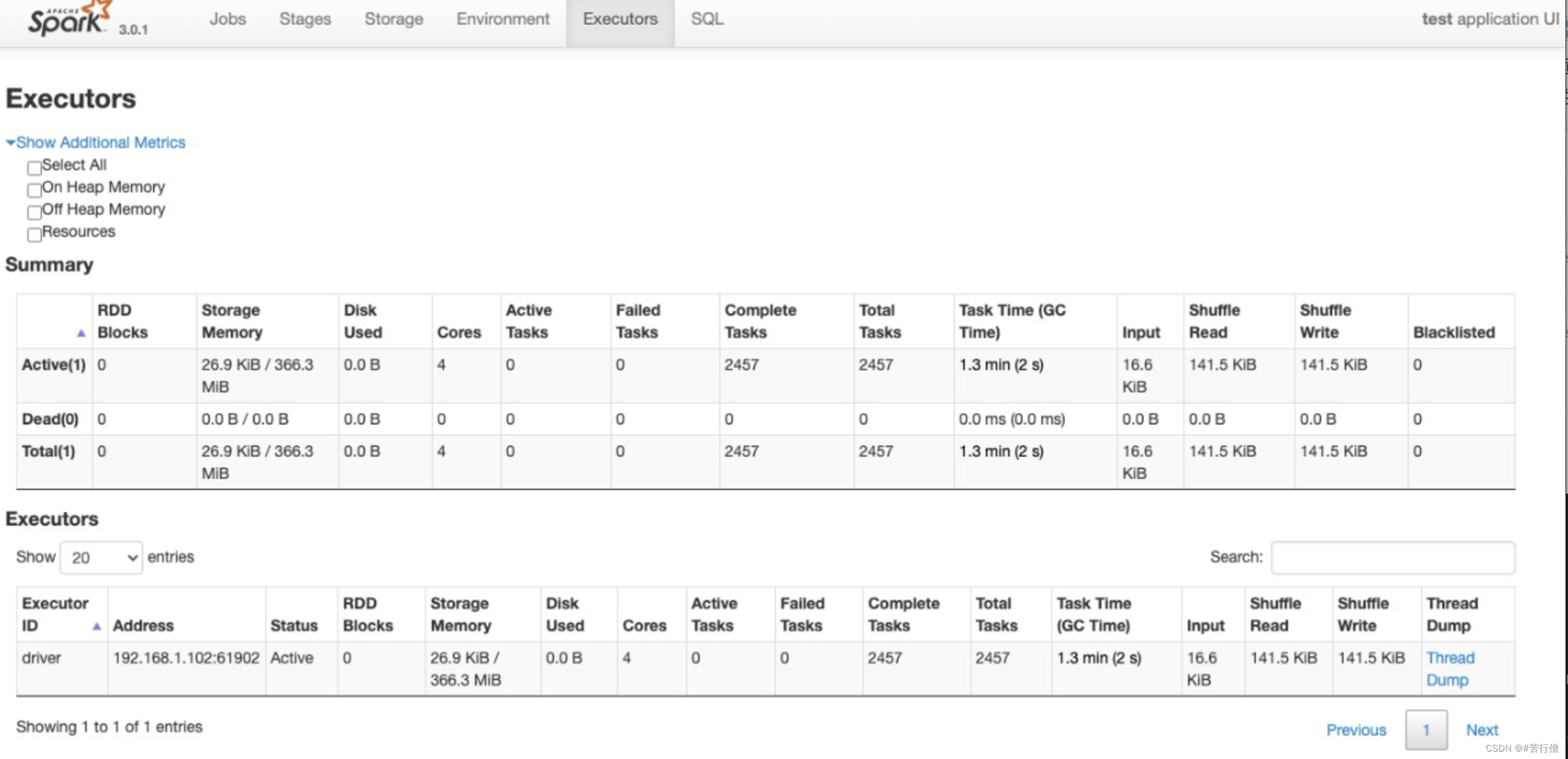
🔥Excutors : 监控各个Excutors的存储和shuffle情况。
🔥 SQL: 显示各种SQL命令在那些Jobs中被执行。
3、Spark调优案例
初始化一波pyspark环境。
import findspark
findspark.init()
import pyspark
from pyspark.sql import SparkSession
#SparkSQL的许多功能封装在SparkSession的方法接口中
spark = SparkSession.builder \
.appName("test") \
.config("master","local[4]") \
.enableHiveSupport() \
.getOrCreate()
sc = spark.sparkContext
🔥 下面仅示范原理,因为我是在单机上测试的,所以某些优化方案难以获得像多机上的性能优势。
3.1、资源配置优化
优化前:
#提交python写的任务
spark-submit --master yarn \
--deploy-mode cluster \
--executor-memory 12G \
--driver-memory 12G \
--num-executors 100 \
--executor-cores 8 \
--conf spark.yarn.maxAppAttempts=2 \
--conf spark.task.maxFailures=10 \
--conf spark.stage.maxConsecutiveAttempts=10 \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./anaconda3.zip/anaconda3/bin/python #指定excutors的Python环境
--conf spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON = ./anaconda3.zip/anaconda3/bin/python #cluster模式时候设置
--archives viewfs:///user/hadoop-xxx/yyy/anaconda3.zip #上传到hdfs的Python环境
--files data.csv,profile.txt
--py-files pkg.py,tqdm.py
pyspark_demo.py
优化后如下所示。这里主要减小了 executor-cores数量,一般设置为1~4,过大的数量可能会造成每个core计算和存储资源不足产生OOM,也会增加GC时间。此外也将默认分区数调到了1600,并设置了2G的堆外内存。
#提交python写的任务
spark-submit --master yarn \
--deploy-mode cluster \
--executor-memory 12G \
--driver-memory 12G \
--num-executors 100 \
--executor-cores 2 \
--conf spark.yarn.maxAppAttempts=2 \
--conf spark.default.parallelism=1600 \
--conf spark.sql.shuffle.partitions=1600 \
--conf spark.memory.offHeap.enabled=true \
--conf spark.memory.offHeap.size=2g\
--conf spark.task.maxFailures=10 \
--conf spark.stage.maxConsecutiveAttempts=10 \
--conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=./anaconda3.zip/anaconda3/bin/python #指定excutors的Python环境
--conf spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON = ./anaconda3.zip/anaconda3/bin/python #cluster模式时候设置
--archives viewfs:///user/hadoop-xxx/yyy/anaconda3.zip #上传到hdfs的Python环境
--files data.csv,profile.txt
--py-files pkg.py,tqdm.py
pyspark_demo.py
3.2、利用缓存减少重复计算
%%time
# 优化前:
# 在code shell中加入%%time可以测量代码块的运行时间。
# 这样可以方便地测量代码块的性能,并进行调整和优化。
# 合并rddx,y,z数据,各数据经过tanh后计算平均值。
rddx = sc.parallelize(range(1000000),3)
rddy = sc.parallelize(range(1000000),3)
rddz = sc.parallelize(range(1000000),3)
rdd = rddx.union(rddy).union(rddz)
print(len(rdd.collect()))
import math
rdd = rdd.map(lambda x: math.tanh(x))
s = rdd.reduce(lambda x,y: x+y)
n = rdd.count()
mean = s/n
print(mean)
3000000
0.9999987199007819
CPU times: user 128 ms, sys: 59.7 ms, total: 187 ms
Wall time: 1.21 s
-
是的,RDD的
map操作是一个transformation操作,它并不会立即执行,而是会被记录下来,等到需要对结果进行操作时才会执行。因此,如果不缓存该RDD,在后续的操作中每次使用该RDD时都需要重新计算,因为RDD的计算结果并没有被保存下来。 -
例如,在本例中,如果不缓存
rdd,而是在后续的操作中多次使用该RDD,那么每次使用时都需要重新计算。例如,对rdd进行reduce和count操作时,需要对rdd中的每个元素进行计算,而每个元素都需要通过map操作进行计算,由于map操作并没有被缓存,因此每次使用时都需要重新计算,这将导致程序的性能下降。 -
通过对RDD进行缓存,可以避免这种情况的发生,因为RDD的计算结果已经被保存下来,可以在需要时直接使用,而不需要重新计算。当RDD被缓存到内存和磁盘中时,可以避免将RDD重新计算,因为RDD的计算结果已经被存储在内存和磁盘中,可以在需要时从内存和磁盘中读取RDD的计算结果。
%%time
# 优化后:
rddx = sc.parallelize(range(1000000),3)
rddy = sc.parallelize(range(1000000),3)
rddz = sc.parallelize(range(1000000),3)
rdd = rddx.union(rddy).union(rddz)
print(len(rdd.collect()))
import math
from pyspark.storagelevel import StorageLevel
rdd = rdd.map(lambda x: math.tanh(x)).persist(StorageLevel.MEMORY_AND_DISK)
s = rdd.reduce(lambda x,y: x+y)
n = rdd.count()
mean = s/n
print(mean)
3000000
0.9999987199007819
CPU times: user 147 ms, sys: 30.5 ms, total: 177 ms
Wall time: 896 ms
3.3、数据倾斜调优
%%time
# 优化前:
rdd_data = sc.parallelize(["hello world"]*1000000+["good morning"]*10000+["I love spark"]*10000)
rdd_word = rdd_data.flatMap(lambda x:x.split(" "))
rdd_one = rdd_word.map(lambda x:(x,1))
rdd_count = rdd_one.reduceByKey(lambda a,b:a+b+0.0)
print(rdd_count.collect())
[('morning', 10000.0), ('hello', 1000000.0), ('spark', 10000.0), ('I', 10000.0), ('love', 10000.0), ('good', 10000.0), ('world', 1000000.0)]
CPU times: user 164 ms, sys: 0 ns, total: 164 ms
Wall time: 833 ms
数据倾斜问题:
-
前面的代码可能会出现数据倾斜的情况,即某些键值对的数量远远大于其他键值对的数量,导致在进行reduceByKey操作时,某些节点的负载过重,而其他节点的负载较轻,从而影响程序的性能和效率。如果说假设reduceByKey之后还需要根据不同的key来处理,那就会数据倾斜了。
-
是的,reduceByKey操作会将具有相同key的键值对分配到同一个节点进行处理。在进行reduceByKey操作时,Spark会根据键值对的键进行分区,将具有相同键的键值对分配到同一个分区中。然后在每个分区内,Spark会将具有相同键的键值对进行聚合,得到一个新的键值对。最后,Spark会将所有分区中的键值对进行合并,得到最终的结果。
-
由于具有相同键的键值对被分配到同一个节点进行处理,因此可以避免在节点之间进行数据传输,从而提高程序的性能和效率。同时,这也意味着如果某些键值对的数量远远大于其他键值对的数量,可能会导致数据倾斜的问题,需要进行数据倾斜调优。
所以下面是这样解决的:
-
为了解决这个问题,可以进行数据倾斜调优,即将数据倾斜的键值对进行拆分,将其拆分成多个键值对,从而将负载均衡到多个节点上,提高程序的性能和效率。
-
在本段代码中,通过在每个键中添加一个随机数来解决数据倾斜的问题。具体来说,将每个键中的单词和一个随机数进行拼接,得到一个新的键,从而避免了某些键值对数量过多的情况。这样可以将负载均衡到多个节点上,提高程序的性能和效率。
需要注意的是,数据倾斜调优需要根据具体情况进行,不同的场景可能需要采用不同的方法来解决数据倾斜问题。
%%time
# 优化后:
import random
rdd_data = sc.parallelize(["hello world"]*1000000+["good morning"]*10000+["I love spark"]*10000)
rdd_word = rdd_data.flatMap(lambda x:x.split(" "))
rdd_one = rdd_word.map(lambda x:(x,1))
rdd_mid_key = rdd_one.map(lambda x:(x[0]+"_"+str(random.randint(0,999)),x[1]))
rdd_mid_count = rdd_mid_key.reduceByKey(lambda a,b:a+b+0.0)
rdd_count = rdd_mid_count.map(lambda x:(x[0].split("_")[0],x[1])).reduceByKey(lambda a,b:a+b+0.0)
print(rdd_count.collect())
#作者按:此处仅示范原理,单机上该优化方案难以获得性能优势
[('morning', 10000.0), ('hello', 1000000.0), ('spark', 10000.0), ('I', 10000.0), ('love', 10000.0), ('good', 10000.0), ('world', 1000000.0)]
CPU times: user 145 ms, sys: 13.2 ms, total: 158 ms
Wall time: 1.22 s
3.4、broadcast+map代替join
%%time
# 优化前:
rdd_age = sc.parallelize([("LiLei",18),("HanMeimei",19),("Jim",17),("LiLy",20)])
rdd_gender = sc.parallelize([("LiLei","male"),("HanMeimei","female"),("Jim","male"),("LiLy","female")])
rdd_students = rdd_age.join(rdd_gender).map(lambda x:(x[0],x[1][0],x[1][1]))
print(rdd_students.collect())
[('LiLei', 18, 'male'), ('Jim', 17, 'male'), ('LiLy', 20, 'female'), ('HanMeimei', 19, 'female')]
CPU times: user 12.6 ms, sys: 130 µs, total: 12.7 ms
Wall time: 325 ms
该优化策略一般限于有一个参与join的rdd的数据量不大的情况。
有时候需要在不同节点或者节点和Driver之间共享变量。Spark提供两种类型的共享变量,广播变量和累加器。
-
广播变量是不可变变量,实现在不同节点不同任务之间共享数据。
-
广播变量在每个机器上缓存一个只读的变量,而不是为每个task生成一个副本,可以减少数据的传输。
-
是的,
join操作会产生Shuffle过程。具体来说,join操作会将两个RDD中具有相同键的键值对分配到同一个节点上进行计算,从而产生Shuffle过程。在进行join操作时,Spark会将两个RDD中的数据根据键进行分区,并将具有相同键的键值对分配到同一个分区中。然后,Spark会将分区内的数据进行排序、合并等操作,得到新的键值对。最后,Spark会将具有相同键的键值对分配到同一个节点上进行计算,从而得到最终的结果。由于join操作需要进行数据的重分布和网络传输,因此会产生Shuffle过程。为了减少Shuffle的数据量,可以在进行join操作之前,对RDD进行合理的分区、缓存、过滤等操作,以提高程序的性能和效率。
-
如下使用将
mapPartitions改为map可能会影响性能,因为mapPartitions操作是对每个分区进行转换操作,而map操作是对每个元素进行转换操作。如果使用map操作,Spark需要为每个元素都创建一个任务,并将任务分配给集群中的节点进行计算,这虽能开更多的并行计算,但将导致任务的创建和调度开销增加,从而影响程序的性能和效率。 -
相比之下,
mapPartitions操作可以减少任务的创建和调度开销,提高程序的性能和效率。在本例中,由于get_age函数是对整个分区进行操作,因此使用mapPartitions操作可以更好地利用集群的计算资源,从而提高程序的性能和效率。通过mapPartitions代替map以减少诸如连接数据库,预处理广播变量等重复过程,都是减少任务计算总时间的例子。 -
需要注意的是,使用
mapPartitions操作时,需要注意内存的使用情况。由于mapPartitions操作是对整个分区进行操作,因此可能会导致内存不足的问题。如果内存不足,可以考虑使用mapPartitionsWithIndex函数,对分区进行分片处理,以减少内存的使用。
# 优化后:
rdd_age = sc.parallelize([("LiLei",18),("HanMeimei",19),("Jim",17),("LiLy",20)])
rdd_gender = sc.parallelize([("LiLei","male"),("HanMeimei","female"),("Jim","male"),("LiLy","female")],2)
ages = rdd_age.collect()
broads = sc.broadcast(ages)
print(broads.value)
# 将每个分区中的元素拼接上age后返回
def get_age(it):
res = []
ages = dict(broads.value)
# x: (name,sex)
for x in it:
name = x[0]
age = ages.get(name, 0)
res.append((x[0], age, x[1]))
return iter(res)
rdd_students = rdd_gender.mapPartitions(get_age)
print(rdd_students.collect())
[('LiLei', 18), ('HanMeimei', 19), ('Jim', 17), ('LiLy', 20)]
[('LiLei', 18, 'male'), ('HanMeimei', 19, 'female'), ('Jim', 17, 'male'), ('LiLy', 20, 'female')]
3.5、reduceByKey/aggregateByKey代替groupByKey
%%time
# 优化前:
rdd_students = sc.parallelize([("class1","LiLei"),("class2","HanMeimei"),("class1","Lucy"),
("class1","Ann"),("class1","Jim"),("class2","Lily")])
# #groupByKey将相同的key对应的values收集成一个Iterator,形如:[(key, it)]
rdd_names = rdd_students.groupByKey().map(lambda t:(t[0],list(t[1])))
names = rdd_names.collect()
print(names)
[('class1', ['LiLei', 'Lucy', 'Ann', 'Jim']), ('class2', ['HanMeimei', 'Lily'])]
CPU times: user 9.34 ms, sys: 0 ns, total: 9.34 ms
Wall time: 186 ms
何为shuffle操作?
-
在Spark中,Shuffle是指对RDD进行重新分区或聚合操作时所涉及的数据重分布过程。在进行Shuffle操作时,Spark会将RDD中的数据重新分布到不同的节点上,以便进行后续的计算。
-
具体来说,当需要对RDD进行重新分区或聚合操作时,Spark会将RDD中的数据根据键值对的键进行分组,将具有相同键的键值对分配到同一个分区中。然后,Spark会将每个分区中的数据进行排序、合并等操作,得到新的键值对。最后,Spark会将新的键值对根据键的哈希值重新分配到不同的节点上,以便进行后续的计算。
-
Shuffle操作是比较耗费计算资源和网络带宽的,因为它需要进行数据的重分布和排序等操作。因此,在实际应用中,需要尽量减少Shuffle的次数和数据量,以提高程序的性能和效率。可以通过对RDD进行合理的分区、缓存、过滤等操作,来减少Shuffle的次数和数据量。
-
groupByKey算子是一个低效的算子,其会产生大量的shuffle。其功能可以用reduceByKey和aggreagateByKey代替,通过在每个partition内部先做一次数据的合并操作,大大减少了shuffle的数据量。
-
说的是正确的,reduceByKey操作也会产生Shuffle,但相比groupByKey操作,它产生的Shuffle数据量要少得多。这是因为reduceByKey操作会在每个分区内部先进行数据的合并操作,从而减少Shuffle的数据量。
-
具体来说,reduceByKey操作会将具有相同键的键值对进行聚合操作,得到一个新的键值对。在进行聚合操作时,Spark会将具有相同键的键值对分配到同一个节点上进行计算。然后,对于每个节点上的数据,Spark会先在节点内部进行数据的合并操作,得到一个局部的聚合结果。最后,Spark会将不同节点上的聚合结果进行合并,得到最终的聚合结果。
-
相比之下,groupByKey操作会将具有相同键的键值对全部分配到同一个节点上,进行聚合操作。这样会导致数据的重分布和网络传输,从而影响程序的性能和效率。
-
因此,在进行聚合操作时,建议使用reduceByKey操作代替groupByKey操作。这样可以减少Shuffle的数据量,提高程序的性能和效率。
%%time
# 优化后:
rdd_students = sc.parallelize([("class1","LiLei"),("class2","HanMeimei"),("class1","Lucy"),
("class1","Ann"),("class1","Jim"),("class2","Lily")])
# 第一个参数为初始值
# 先在每个分区内,分别对相同key的元素执行第一个函数
# 最后,对所有分区的结果相同的key的元素执行第二个函数。
rdd_names = rdd_students.aggregateByKey([],
lambda arr,name: arr+[name],
lambda arr1,arr2: arr1+arr2)
names = rdd_names.collect()
print(names)
[('class1', ['LiLei', 'Lucy', 'Ann', 'Jim']), ('class2', ['HanMeimei', 'Lily'])]
CPU times: user 6.53 ms, sys: 1.81 ms, total: 8.34 ms
Wall time: 206 ms
Reference
- [1] 梁云大佬的: https://github.com/lyhue1991/eat_pyspark_in_10_days。也欢迎大家给梁云大佬点点关注,他的微信公众号叫:“算法美食屋”