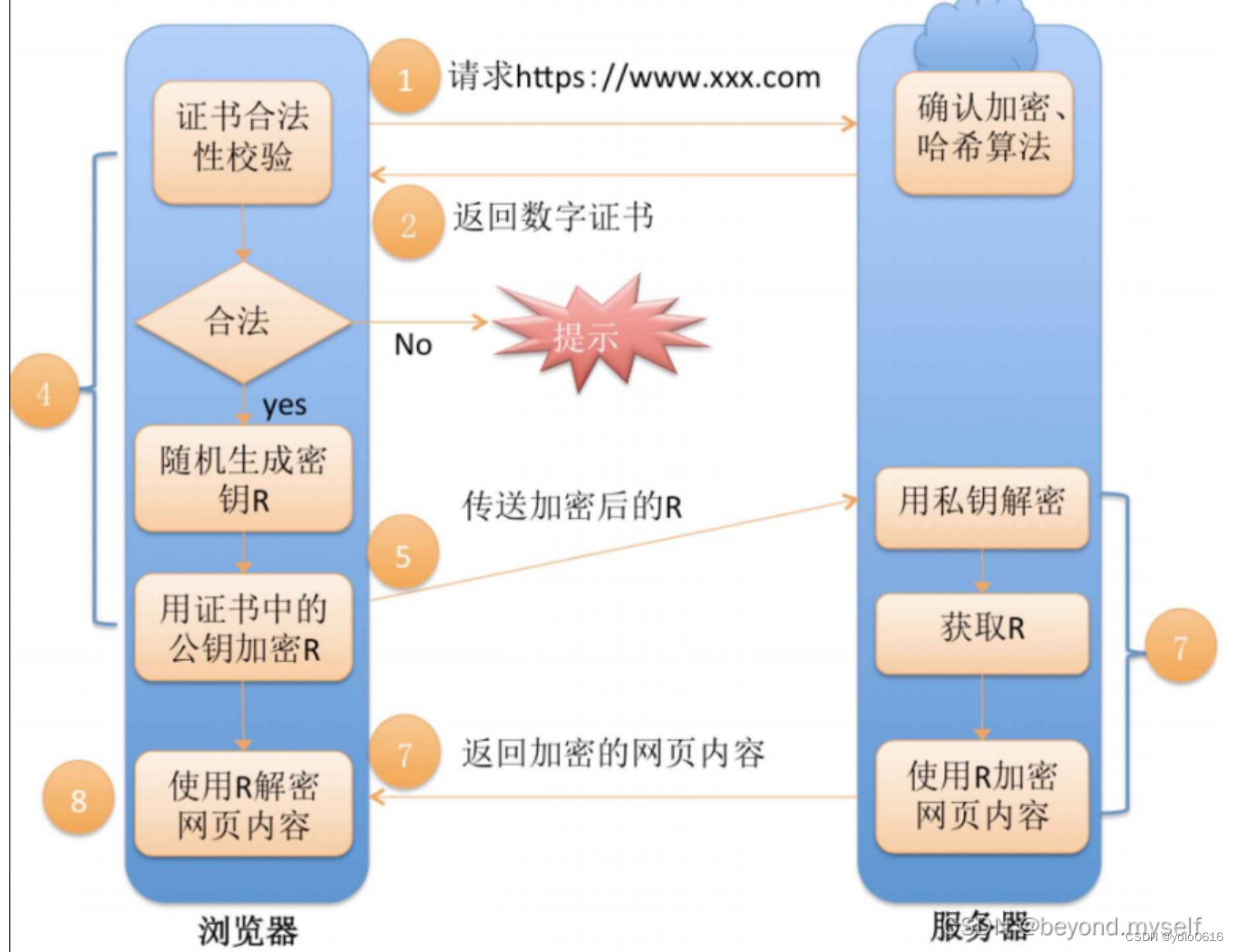
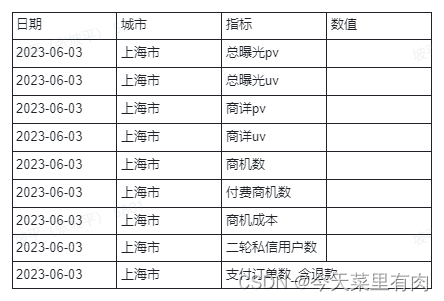
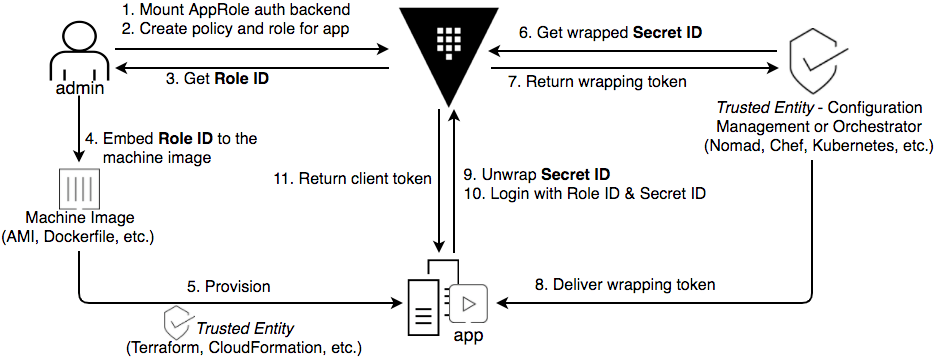
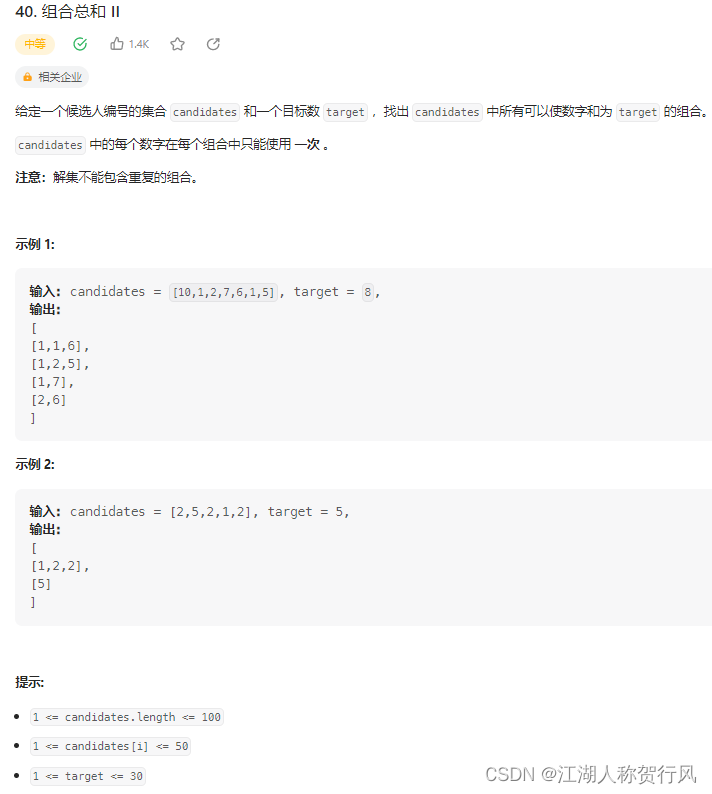
前言

今天,有一位粉丝找到我,希望我出一期关于某大夫数据采集的文章,今天,我们就来采集某大夫的问诊数据。
环境使用
- python 3.9
- pycharm
模块使用
- requests
模块介绍
- requests
requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多。
- parsel
parsel是一个python的第三方库,相当于css选择器+xpath+re。
parsel由scrapy团队开发,是将scrapy中的parsel独立抽取出来的,可以轻松解析html,xml内容,获取需要的数据。
相比于BeautifulSoup,xpath,parsel效率更高,使用更简单。
- re
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用。
- os
os 就是 “operating system” 的缩写,顾名思义,os模块提供的就是各种 Python 程序与操作系统进行交互的接口。通过使用 os 模块,一方面可以方便地与操作系统进行交互,另一方面也可以极大增强代码的可移植性。
- csv
它是一种文件格式,一般也被叫做逗号分隔值文件,可以使用 Excel 软件或者文本文档打开 。其中数据字段用半角逗号间隔(也可以使用其它字符),使用 Excel 打开时,逗号会被转换为分隔符。csv 文件是以纯文本形式存储了表格数据,并且在兼容各个操作系统。
模块安装问题:
- 如果安装python第三方模块:
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
在pycharm中点击Terminal(终端) 输入安装命令
- 安装失败原因:
- 失败一: pip 不是内部命令
解决方法: 设置环境变量
- 失败二: 出现大量报红 (read time out)
解决方法: 因为是网络链接超时, 需要切换镜像源
清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:https://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 华中理工大学:https://pypi.hustunique.com/ 山东理工大学:https://pypi.sdutlinux.org/ 豆瓣:https://pypi.douban.com/simple/ 例如:pip3 install -i https://pypi.doubanio.com/simple/ 模块名
- 失败三: cmd里面显示已经安装过了, 或者安装成功了, 但是在pycharm里面还是无法导入
解决方法: 可能安装了多个python版本 (anaconda 或者 python 安装一个即可) 卸载一个就好,或者你pycharm里面python解释器没有设置好。
代码实现
今天,我们就来采集好大夫的问诊数据。下面,我和大家介绍如何获取数据。
确定网址
首先,我们要确定我们获取的目标网站,然后,确定我们需要的数据是什么。
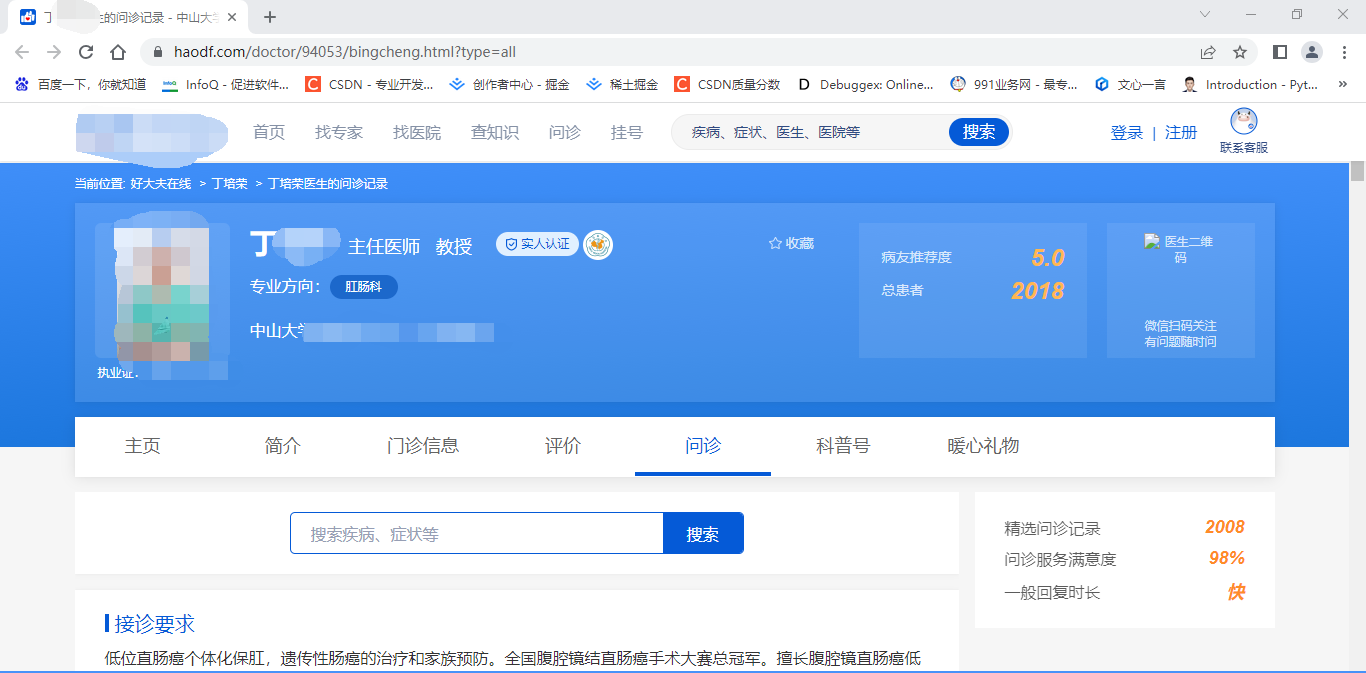
我们滚动页面,我们看到了问诊记录,这时,我们打开开发者工具。打开开发者工具之后,刷新页面,我们滚动网页页面,我们会看到下面的页面,大家在滚动之前,最好清除一下数据包。
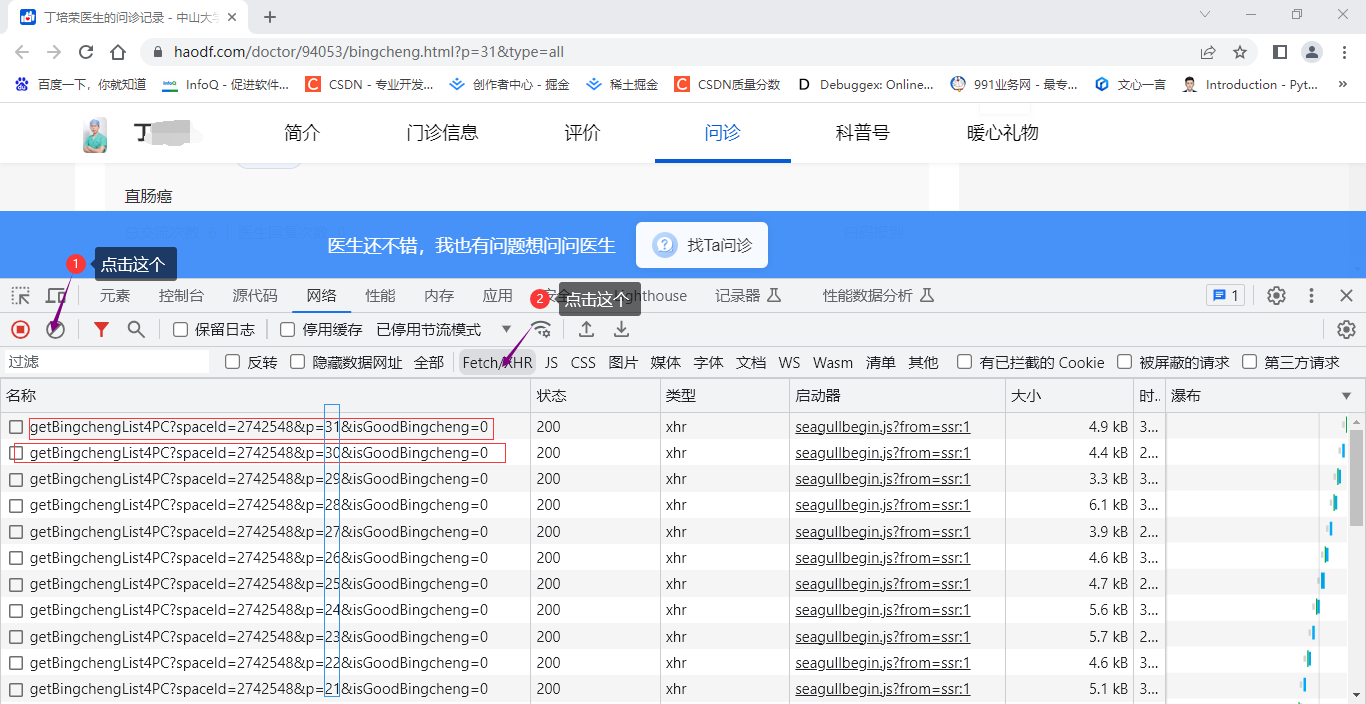
这样,我们就抓取到了所有问诊记录的数据包,我们会发现,里面有一段数字不一样,我们猜想是页码,当然,我们通过验证,就是页码,既然我们拿到了地址,就简单多了,我们接下来,开始写代码。
发送请求
我们首先确定我们的目标网址,对我们需要获取的数据。我们先看一下,数据包里面有什么内容,这个,和我们网页显示的一模一样。我们先获取第一页的数据。
import requests
headers = {
"authority": "zoo.haodf.com",
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9",
"cookie": "g=HDF.143.64778d15bc9b3; krandom_a119fcaa84=877492; __bid_n=1887c8ff1502fccdeb4207; FPTOKEN=pQ0+Q1N7Yy9X9wO03KejFmuYIJFJp3G5sBWbXvIwC0W+7v0ggLDEkfeBruyynjo0oXNB9jzCrUOVWeJ9OvBRxFt8rwwdVDZXoc7NdGQtdZpccy0BscX7HYE1NXnwZrSmYlCbcQKBXww+X4DKPXzcCBL0rjvWKiwQMPnLmFxwTxYi/WoosLCoU348LjMiHDlu/6H8j9g5YroiL+NnOGTeuvYCpcXgzL8ILqr03u8djk8n6IhNTw1gchBX5HrpfvByEaH1b2p5B2KbWb7s7gksZjwfvgWFz6DG9mmjoEmm2s0AP4MdTNBlsYfdVhFyo2L5c/520wr9TBlIGKAxuEAMEkxiN9it9anrElqy6f7WOSq7WDumwV1UCYzp/r7LJK1hdR4Hl7JeTGItqZow5EtODw==^|OlnZ9EPt13Wn8Lt1mJ76AvSqwbhaCvCjgnLXiiG3WV0=^|10^|0ebdcc577fb79709972c988c7aaf86f9; Hm_lvt_dfa5478034171cc641b1639b2a5b717d=1687267673,1688477978; Hm_lpvt_dfa5478034171cc641b1639b2a5b717d=1688479957",
"referer": "https://www.haodf.com/",
"sec-ch-ua": "^\\^Not.A/Brand^^;v=^\\^8^^, ^\\^Chromium^^;v=^\\^114^^, ^\\^Google",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "^\\^Windows^^",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "no-cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"origin": "https://www.haodf.com",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"If-None-Match": "4be90d78c1efe46b69558f575162c694",
"Referer": "https://www.haodf.com/",
"Sec-Fetch-Dest": "script",
"Sec-Fetch-Mode": "no-cors",
"Sec-Fetch-Site": "cross-site",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"content-length": "0"
}
cookies = {
"HMACCOUNT_BFESS": "98346E4F47A1DA39",
"HMTK": "1",
"BAIDUID_BFESS": "42362309F92CBA36955515B3BC24C906:SL=0:NR=10:FG=1",
"ZFY": "QcUe7:AJExloferQMOZmqrXdgnmibYtD6jG4mPN9SkCs:C",
"BDUSS_BFESS": "hlejJHY35ocUZaZW1LdjRpc3l6bjcwM3JCNjZTcjRLZHNBVExWcU00S1ljTXBrSVFBQUFBJCQAAAAAAAAAAAEAAAA2pSDKwbXE48qxz8LRqQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAJjjomSY46Jkel",
"H_PS_PSSID": "36544_38942_38857_38795_38957_38954_39009_38831_38918_38973_38818_38638_26350"
}
url = "https://www.haodf.com/ndoctor/getBingchengList4PC"
params = {
"spaceId": "2742548",
"p": "1",
"isGoodBingcheng": "0"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
print(response.text)
print(response)我们运行这个代码,我们可以看到这样的输出,就说明我们的代码也没有问题,也没有被反爬。
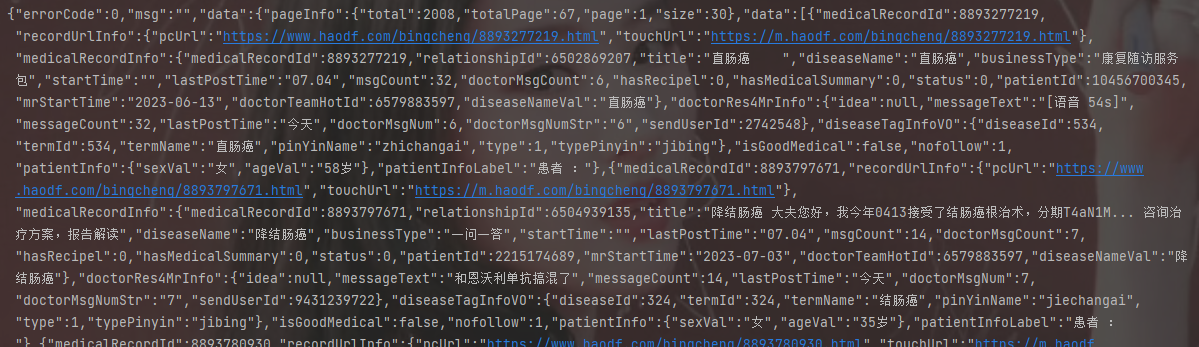
获取数据
我们这个为了方便展示,我们只获取问诊文字信息,关于其他的数据,原理都是一样的。

接下来,我们开始写代码,后面都是字典取值,没有什么难度,按部就班的取值就好。我们分析数据分析,一页里面有30个问诊记录。
datas = response.json()['data']['data']
for data in datas:
print(data)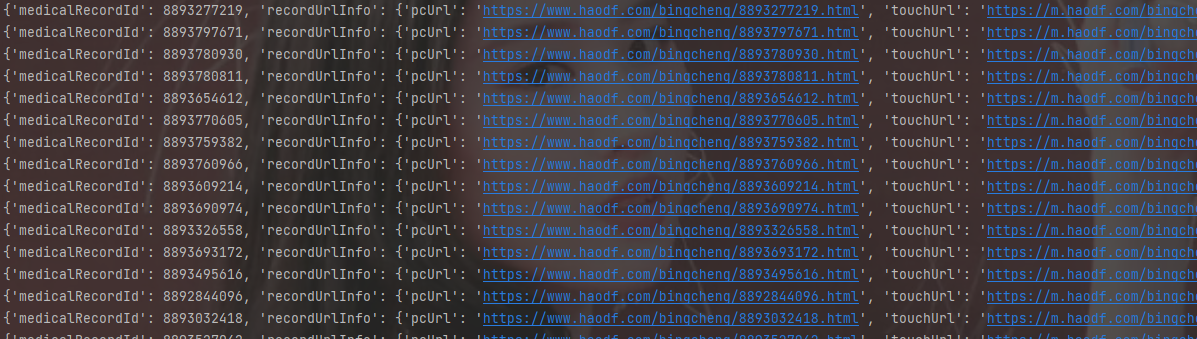
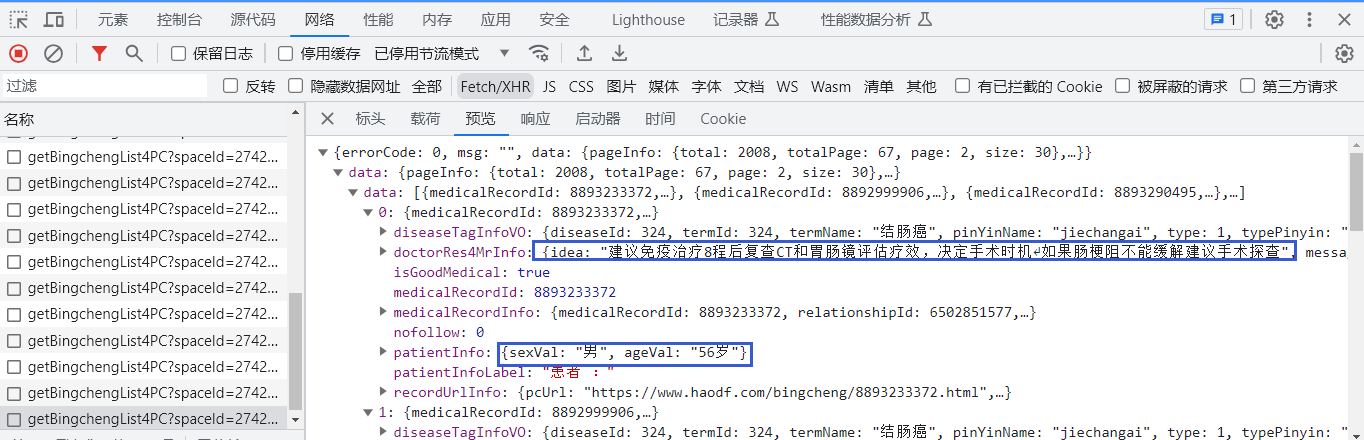
我们可以看到,这里每一行的数据,就是一个患者的信息,我们接下来获取文字记录,不过,我们会发现有语音消息字样,这里我们就不管了。
datas = response.json()['data']['data']
for data in datas:
lastPostTime =data['doctorRes4MrInfo']['lastPostTime']
messageText=data['doctorRes4MrInfo']['messageText']
print(lastPostTime,messageText)到这里,我们的代码就完成了,也实现了我们想要的功能。

多页获取
多页获取数据,其实很简单,我们只要改页码数字就可以了,其他的代码都是一样的,这里,我也写保存数据的代码了,感兴趣的可以看我之前的博客。
import requests
for p in range(1, 100):
headers = {
"cookie": "g=HDF.143.64778d15bc9b3; krandom_a119fcaa84=877492; __bid_n=1887c8ff1502fccdeb4207; FPTOKEN=pQ0+Q1N7Yy9X9wO03KejFmuYIJFJp3G5sBWbXvIwC0W+7v0ggLDEkfeBruyynjo0oXNB9jzCrUOVWeJ9OvBRxFt8rwwdVDZXoc7NdGQtdZpccy0BscX7HYE1NXnwZrSmYlCbcQKBXww+X4DKPXzcCBL0rjvWKiwQMPnLmFxwTxYi/WoosLCoU348LjMiHDlu/6H8j9g5YroiL+NnOGTeuvYCpcXgzL8ILqr03u8djk8n6IhNTw1gchBX5HrpfvByEaH1b2p5B2KbWb7s7gksZjwfvgWFz6DG9mmjoEmm2s0AP4MdTNBlsYfdVhFyo2L5c/520wr9TBlIGKAxuEAMEkxiN9it9anrElqy6f7WOSq7WDumwV1UCYzp/r7LJK1hdR4Hl7JeTGItqZow5EtODw==^|OlnZ9EPt13Wn8Lt1mJ76AvSqwbhaCvCjgnLXiiG3WV0=^|10^|0ebdcc577fb79709972c988c7aaf86f9; Hm_lvt_dfa5478034171cc641b1639b2a5b717d=1687267673,1688477978; Hm_lpvt_dfa5478034171cc641b1639b2a5b717d=1688479957",
"referer": "https://www.haodf.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
}
url = "https://www.haodf.com/ndoctor/getBingchengList4PC"
params = {
"spaceId": "2742548",
"p": p,
"isGoodBingcheng": "0"
}
response = requests.get(url, headers=headers, params=params)
datas = response.json()['data']['data']
for data in datas:
lastPostTime = data['doctorRes4MrInfo']['lastPostTime']
messageText = data['doctorRes4MrInfo']['messageText']
print(lastPostTime, messageText)
简化后的代码如上,大家如果还有什么问题可以在评论区留言。