目录
了解config (模型训练测试的整体过程配置文件)
通过脚本参数修改config
Config 文件 结构
config文件的命名规则
动作识别的config系统
了解config (模型训练测试的整体过程配置文件)
我们使用python文件作为config,将模块化和继承性设计融入到我们的config系统中,方便进行各种实验。可以在MMAction2/configs下找到所有提供的config。如果你想检查、分析config文件,你可以运行python tools/analysis_tools/print_config.py /PATH/TO/CONFIG来查看完整的config。
通过脚本参数修改config
当使用tools/train.py或tools/test.py提交jobs时,你可以指定--cfg-options来就地修改config。
更新config的字典关键字。
config选项可以按照原始配置中dict的keys顺序来指定。例如,--cfg-options model.backbone.norm_eval=False将模型骨干中的所有BN模块改为训练模式。
更新configs list内的keys。
一些config字典在你的config中被组成一个list。例如,训练pipeline train_pipeline 通常是一个list,例如 [dict(type='SampleFrames'), ...]。如果你想把pipeline中的 "SampleFrames "改为 "DenseSampleFrames",你可以指定--cfg-options train_pipeline.0.type=DenseSampleFrames。
更新list/tuples的值。
如果要更新的值是一个列表或一个元组。例如,config文件通常设置model.data_preprocessor.mean=[123.675, 116.28, 103.53]。如果你想改变这个键,你可以指定--cfg-options model.data_preprocessor.mean="[128,128,128]"。注意,引号 "是支持列表/元组数据类型。
Config 文件 结构
configs/_base_下有3种基本的组件类型,models、schedules、default_runtime。许多方法可以很容易地用其中的一个来构建,比如TSN、I3D、SlowOnly等等。由来自_base_的组件组成的配置被称为primitive。
对于同一文件夹下的所有configs,建议只拥有一个primitive的config。所有其他的config都应该继承自primitive的config。最大的继承级别是3。
为了便于理解,我们建议贡献者从退出的方法中继承。例如,如果在TSN的基础上做了一些修改,用户可以首先通过指定_base_ = ../tsn/tsn_imagenet-retrained-r50_8xb32-1x1x3-100e_kinetics400-rgb.py来继承基本的TSN结构,然后修改配置文件中的必要字段。
如果你正在构建一个全新的方法,并且不与任何现有的方法共享结构,你可以在configs/TASK下创建一个文件夹。
这部分具体请参考mmengine的详细文档。
config文件的命名规则
我们遵循下面的风格来命名config文件。建议贡献者遵循同样的风格。config文件的名称被分为几个部分。从逻辑上讲,不同的部分用下划线"_"连接,而同一部分的设置用破折号"-"连接。
{algorithm info}_{module info}_{training info}_{data info}.py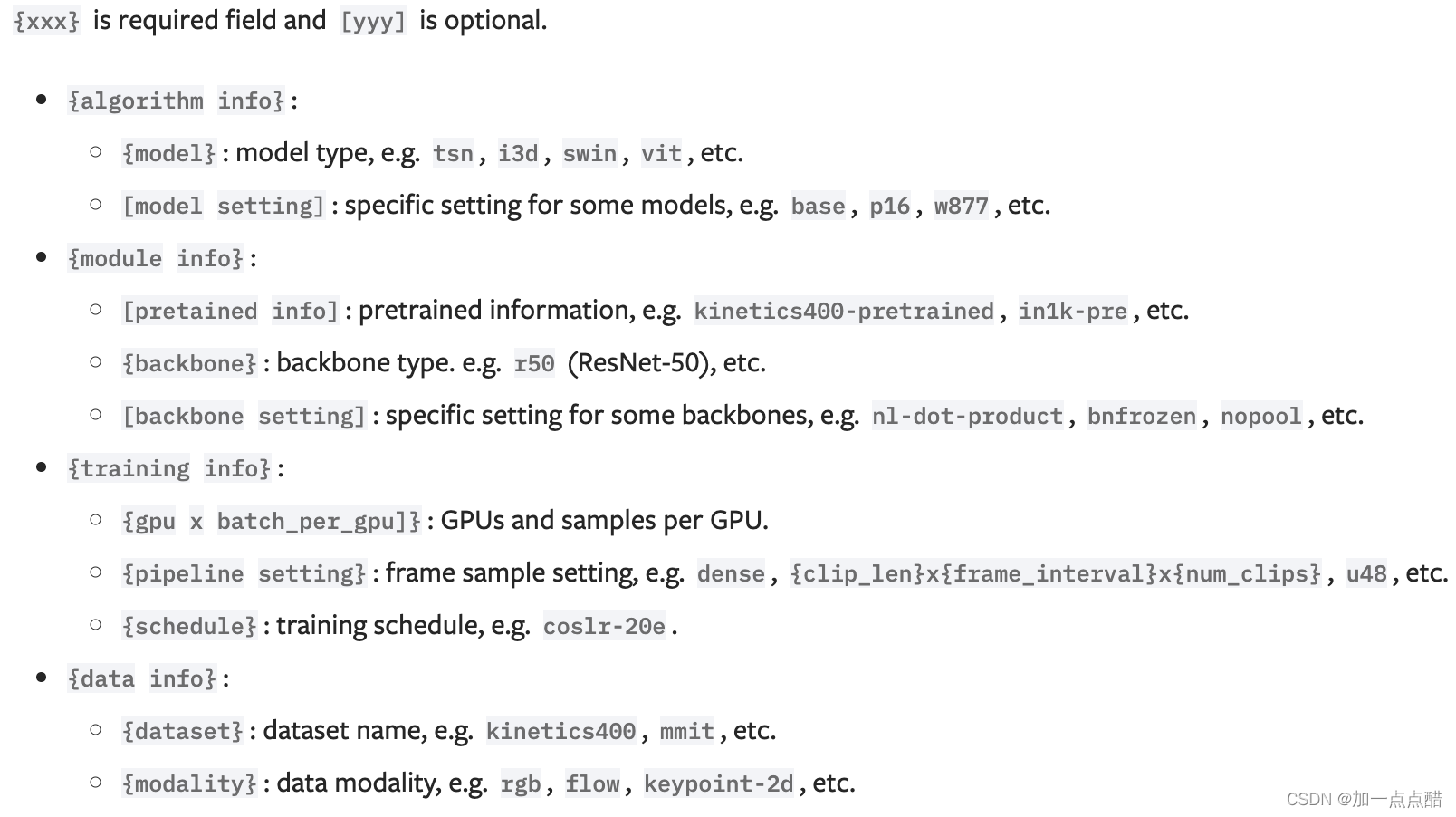
动作识别的config系统
我们将模块化设计纳入我们的config系统,这便于进行各种实验。
一个TSN模型的例子
为了帮助用户对一个完整的config结构和动作识别系统中的模块有一个基本的概念,我们对TSN的config做了如下的简要介绍。关于每个模块中每个参数的更详细的用法和选择,请参考API文档。
# model setting
model = dict( # Config of the model
type='FastRCNN', # Class name of the detector
_scope_='mmdet', # The scope of current config
backbone=dict( # Dict for backbone
type='ResNet3dSlowOnly', # Name of the backbone
depth=50, # Depth of ResNet model
pretrained=None, # The url/site of the pretrained model
pretrained2d=False, # If the pretrained model is 2D
lateral=False, # If the backbone is with lateral connections
num_stages=4, # Stages of ResNet model
conv1_kernel=(1, 7, 7), # Conv1 kernel size
conv1_stride_t=1, # Conv1 temporal stride
pool1_stride_t=1, # Pool1 temporal stride
spatial_strides=(1, 2, 2, 1)), # The spatial stride for each ResNet stage
roi_head=dict( # Dict for roi_head
type='AVARoIHead', # Name of the roi_head
bbox_roi_extractor=dict( # Dict for bbox_roi_extractor
type='SingleRoIExtractor3D', # Name of the bbox_roi_extractor
roi_layer_type='RoIAlign', # Type of the RoI op
output_size=8, # Output feature size of the RoI op
with_temporal_pool=True), # If temporal dim is pooled
bbox_head=dict( # Dict for bbox_head
type='BBoxHeadAVA', # Name of the bbox_head
in_channels=2048, # Number of channels of the input feature
num_classes=81, # Number of action classes + 1
multilabel=True, # If the dataset is multilabel
dropout_ratio=0.5), # The dropout ratio used
data_preprocessor=dict( # Dict for data preprocessor
type='ActionDataPreprocessor', # Name of data preprocessor
mean=[123.675, 116.28, 103.53], # Mean values of different channels to normalize
std=[58.395, 57.12, 57.375], # Std values of different channels to normalize
format_shape='NCHW')), # Final image shape format
# model training and testing settings
train_cfg=dict( # Training config of FastRCNN
rcnn=dict( # Dict for rcnn training config
assigner=dict( # Dict for assigner
type='MaxIoUAssignerAVA', # Name of the assigner
pos_iou_thr=0.9, # IoU threshold for positive examples, > pos_iou_thr -> positive
neg_iou_thr=0.9, # IoU threshold for negative examples, < neg_iou_thr -> negative
min_pos_iou=0.9), # Minimum acceptable IoU for positive examples
sampler=dict( # Dict for sample
type='RandomSampler', # Name of the sampler
num=32, # Batch Size of the sampler
pos_fraction=1, # Positive bbox fraction of the sampler
neg_pos_ub=-1, # Upper bound of the ratio of num negative to num positive
add_gt_as_proposals=True), # Add gt bboxes as proposals
pos_weight=1.0)), # Loss weight of positive examples
test_cfg=dict(rcnn=None)) # Testing config of FastRCNN
# dataset settings
dataset_type = 'AVADataset' # Type of dataset for training, validation and testing
data_root = 'data/ava/rawframes' # Root path to data
anno_root = 'data/ava/annotations' # Root path to annotations
ann_file_train = f'{anno_root}/ava_train_v2.1.csv' # Path to the annotation file for training
ann_file_val = f'{anno_root}/ava_val_v2.1.csv' # Path to the annotation file for validation
exclude_file_train = f'{anno_root}/ava_train_excluded_timestamps_v2.1.csv' # Path to the exclude annotation file for training
exclude_file_val = f'{anno_root}/ava_val_excluded_timestamps_v2.1.csv' # Path to the exclude annotation file for validation
label_file = f'{anno_root}/ava_action_list_v2.1_for_activitynet_2018.pbtxt' # Path to the label file
proposal_file_train = f'{anno_root}/ava_dense_proposals_train.FAIR.recall_93.9.pkl' # Path to the human detection proposals for training examples
proposal_file_val = f'{anno_root}/ava_dense_proposals_val.FAIR.recall_93.9.pkl' # Path to the human detection proposals for validation examples
train_pipeline = [ # Training data processing pipeline
dict( # Config of SampleFrames
type='AVASampleFrames', # Sample frames pipeline, sampling frames from video
clip_len=4, # Frames of each sampled output clip
frame_interval=16), # Temporal interval of adjacent sampled frames
dict( # Config of RawFrameDecode
type='RawFrameDecode'), # Load and decode Frames pipeline, picking raw frames with given indices
dict( # Config of RandomRescale
type='RandomRescale', # Randomly rescale the shortedge by a given range
scale_range=(256, 320)), # The shortedge size range of RandomRescale
dict( # Config of RandomCrop
type='RandomCrop', # Randomly crop a patch with the given size
size=256), # The size of the cropped patch
dict( # Config of Flip
type='Flip', # Flip Pipeline
flip_ratio=0.5), # Probability of implementing flip
dict( # Config of FormatShape
type='FormatShape', # Format shape pipeline, Format final image shape to the given input_format
input_format='NCTHW', # Final image shape format
collapse=True), # Collapse the dim N if N == 1
dict(type='PackActionInputs') # Pack input data
]
val_pipeline = [ # Validation data processing pipeline
dict( # Config of SampleFrames
type='AVASampleFrames', # Sample frames pipeline, sampling frames from video
clip_len=4, # Frames of each sampled output clip
frame_interval=16), # Temporal interval of adjacent sampled frames
dict( # Config of RawFrameDecode
type='RawFrameDecode'), # Load and decode Frames pipeline, picking raw frames with given indices
dict( # Config of Resize
type='Resize', # Resize pipeline
scale=(-1, 256)), # The scale to resize images
dict( # Config of FormatShape
type='FormatShape', # Format shape pipeline, Format final image shape to the given input_format
input_format='NCTHW', # Final image shape format
collapse=True), # Collapse the dim N if N == 1
dict(type='PackActionInputs') # Pack input data
]
train_dataloader = dict( # Config of train dataloader
batch_size=32, # Batch size of each single GPU during training
num_workers=8, # Workers to pre-fetch data for each single GPU during training
persistent_workers=True, # If `True`, the dataloader will not shut down the worker processes after an epoch end, which can accelerate training speed
sampler=dict(
type='DefaultSampler', # DefaultSampler which supports both distributed and non-distributed training. Refer to https://github.com/open-mmlab/mmengine/blob/main/mmengine/dataset/sampler.py
shuffle=True), # Randomly shuffle the training data in each epoch
dataset=dict( # Config of train dataset
type=dataset_type,
ann_file=ann_file_train, # Path of annotation file
exclude_file=exclude_file_train, # Path of exclude annotation file
label_file=label_file, # Path of label file
data_prefix=dict(img=data_root), # Prefix of frame path
proposal_file=proposal_file_train, # Path of human detection proposals
pipeline=train_pipeline))
val_dataloader = dict( # Config of validation dataloader
batch_size=1, # Batch size of each single GPU during evaluation
num_workers=8, # Workers to pre-fetch data for each single GPU during evaluation
persistent_workers=True, # If `True`, the dataloader will not shut down the worker processes after an epoch end
sampler=dict(
type='DefaultSampler',
shuffle=False), # Not shuffle during validation and testing
dataset=dict( # Config of validation dataset
type=dataset_type,
ann_file=ann_file_val, # Path of annotation file
exclude_file=exclude_file_val, # Path of exclude annotation file
label_file=label_file, # Path of label file
data_prefix=dict(img=data_root_val), # Prefix of frame path
proposal_file=proposal_file_val, # Path of human detection proposals
pipeline=val_pipeline,
test_mode=True))
test_dataloader = val_dataloader # Config of testing dataloader
# evaluation settings
val_evaluator = dict( # Config of validation evaluator
type='AVAMetric',
ann_file=ann_file_val,
label_file=label_file,
exclude_file=exclude_file_val)
test_evaluator = val_evaluator # Config of testing evaluator
train_cfg = dict( # Config of training loop
type='EpochBasedTrainLoop', # Name of training loop
max_epochs=20, # Total training epochs
val_begin=1, # The epoch that begins validating
val_interval=1) # Validation interval
val_cfg = dict( # Config of validation loop
type='ValLoop') # Name of validation loop
test_cfg = dict( # Config of testing loop
type='TestLoop') # Name of testing loop
# learning policy
param_scheduler = [ # Parameter scheduler for updating optimizer parameters, support dict or list
dict(type='LinearLR', # Decays the learning rate of each parameter group by linearly changing small multiplicative factor
start_factor=0.1, # The number we multiply learning rate in the first epoch
by_epoch=True, # Whether the scheduled learning rate is updated by epochs
begin=0, # Step at which to start updating the learning rate
end=5), # Step at which to stop updating the learning rate
dict(type='MultiStepLR', # Decays the learning rate once the number of epoch reaches one of the milestones
begin=0, # Step at which to start updating the learning rate
end=20, # Step at which to stop updating the learning rate
by_epoch=True, # Whether the scheduled learning rate is updated by epochs
milestones=[10, 15], # Steps to decay the learning rate
gamma=0.1)] # Multiplicative factor of learning rate decay
# optimizer
optim_wrapper = dict( # Config of optimizer wrapper
type='OptimWrapper', # Name of optimizer wrapper, switch to AmpOptimWrapper to enable mixed precision training
optimizer=dict( # Config of optimizer. Support all kinds of optimizers in PyTorch. Refer to https://pytorch.org/docs/stable/optim.html#algorithms
type='SGD', # Name of optimizer
lr=0.2, # Learning rate
momentum=0.9, # Momentum factor
weight_decay=0.0001), # Weight decay
clip_grad=dict(max_norm=40, norm_type=2)) # Config of gradient clip
# runtime settings
default_scope = 'mmaction' # The default registry scope to find modules. Refer to https://mmengine.readthedocs.io/en/latest/tutorials/registry.html
default_hooks = dict( # Hooks to execute default actions like updating model parameters and saving checkpoints.
runtime_info=dict(type='RuntimeInfoHook'), # The hook to updates runtime information into message hub
timer=dict(type='IterTimerHook'), # The logger used to record time spent during iteration
logger=dict(
type='LoggerHook', # The logger used to record logs during training/validation/testing phase
interval=20, # Interval to print the log
ignore_last=False), # Ignore the log of last iterations in each epoch
param_scheduler=dict(type='ParamSchedulerHook'), # The hook to update some hyper-parameters in optimizer
checkpoint=dict(
type='CheckpointHook', # The hook to save checkpoints periodically
interval=3, # The saving period
save_best='auto', # Specified metric to mearsure the best checkpoint during evaluation
max_keep_ckpts=3), # The maximum checkpoints to keep
sampler_seed=dict(type='DistSamplerSeedHook'), # Data-loading sampler for distributed training
sync_buffers=dict(type='SyncBuffersHook')) # Synchronize model buffers at the end of each epoch
env_cfg = dict( # Dict for setting environment
cudnn_benchmark=False, # Whether to enable cudnn benchmark
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0), # Parameters to setup multiprocessing
dist_cfg=dict(backend='nccl')) # Parameters to setup distributed environment, the port can also be set
log_processor = dict(
type='LogProcessor', # Log processor used to format log information
window_size=20, # Default smooth interval
by_epoch=True) # Whether to format logs with epoch type
vis_backends = [ # List of visualization backends
dict(type='LocalVisBackend')] # Local visualization backend
visualizer = dict( # Config of visualizer
type='ActionVisualizer', # Name of visualizer
vis_backends=vis_backends)
log_level = 'INFO' # The level of logging
load_from = ('https://download.openmmlab.com/mmaction/v1.0/recognition/slowonly/'
'slowonly_imagenet-pretrained-r50_8xb16-4x16x1-steplr-150e_kinetics400-rgb/'
'slowonly_imagenet-pretrained-r50_8xb16-4x16x1-steplr-150e_kinetics400-rgb_20220901-e7b65fad.pth') # Load model checkpoint as a pre-trained model from a given path. This will not resume training.
resume = False # Whether to resume from the checkpoint defined in `load_from`. If `load_from` is None, it will resume the latest checkpoint in the `work_dir`.