1.背景
得物社区是一大批年轻人获取潮流信息、分享日常生活的潮流生活社区。其中用户浏览的信息,进行个性化的分发,是由推荐系统来决策完成的。目前得物社区多个场景接入了推荐算法,包括首页推荐双列流、沉浸式视频推荐、分类tab推荐流、直播推荐流等多个场景,为了给用户提供更好的服务和体验,我们从整个推荐系统维度为相关服务做了大量优化。现在主流的推荐系统都会有召回、粗排、精排和机制等多个模块组成,本文主要介绍我们在精排层面演进过程中做的一些工作和思考。
2.挑战和解法
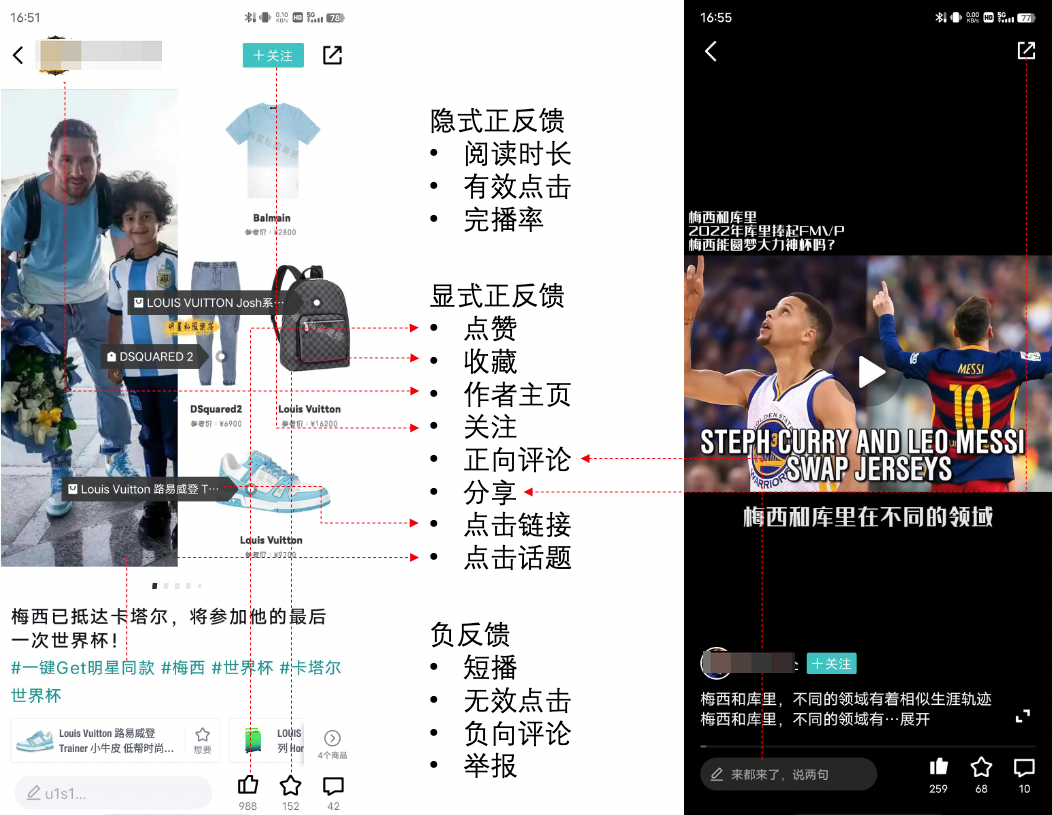
用户在与信息流交互过程中,会产生点击、阅读、点赞、关注、收藏、评论和负反馈等行为,一般是业务关心的核心指标,也可作为算法同学建模的信号。其中,点击是用户一系列行为轨迹的入口,相对不稀疏,往往是一个信息流推荐系统初期最关注的目标之一。如何对用户兴趣进行精准建模,是这些年来推荐系统在工业界从初出茅庐到大展身手的过程中始终热门的主题。在工业界中一个好的业务建模范式是在一定资源约束下,做好服务于业务目标的可迭代的系统优化,对于推荐系统来说,需要考虑系统引擎、计算资源、模型迭代和维护的人力、系统和模型的可迭代性以及多团队合作等多方面因素下,推动整个系统向着业务目标持续前进。拆解到精排层面,我们需要解决多场景、多人群和多目标等为准确预估用户兴趣带来的挑战。下面从特征、样本、多目标建模和新用户冷启动等多个方向来阐述我们对这些挑战在得物社区的具体解法。
2.1 特征
单目标的CTR模型的技术演进可从两个不同的视角进行观察,一个维度是特征工程,另外一个维度就是模型结构复杂度。在CTR模型早期的时候,受限于计算资源,模型结构往往比较简单,初期应用最广泛的便是LR模型。这个阶段算法工程师更多的时间是人工设计特征,从而针对不同的业务背景进行迭代拿到指标收益。
推荐系统精排模型其实是一个预估用户行为概率的模型,我们希望模型一方面能够记住用户的历史行为(即拟合能力),另一方面可以基于历史数据进行合理扩展(即泛化能力)。在传统机器学习时期,LR、SVM和GDBT等模型就已经具备很好的拟合能力,可以在训练数据集上有极好的表现。但在实际业务上,真实的困难在于,如何基于过去数据准确地预估未来行为。万物基于数,在数学的视角上,模型建模本质上是对现实世界一部分运行规律在数字空间的抽象和模拟。现实行为在数字空间的表征的准确性很大程度上决定了建模的效果,幸运的是随着深度学习的发展,基于Embedding的表征技术越来越成熟,基本解决了建模的表征瓶颈,而这个映射空间往往称为特征向量空间。
对于推荐系统精排模型而言,在向量空间中具备现实概念的基本单元就是特征,这也揭示了针对特征的工作,对于整个建模的重要性。各个业务场景特征的设计,要求算法工程师对业务具备足够的理解,以及拥有丰富相关经验,特征工程也是算法工作中资源投入权重很大的工作,需要持续打磨优化,所谓磨刀不误砍柴工。
2.1.1 特征设计
模型使用的特征根据不同的角度可进行不一样的划分。根据特征来源,可以分为用户特征、Item特征、上下文特征、交叉特征以及级联模型特征;根据特征结构,一般可按照Dense和Sparse进行区分;根据特征时效性,往往又分为离线特征和实时特征。对于具体的业务场景,可根据特征来源,按照下表从整体上设计各个域的特征,在迭代的过程中持续优化升级特征。

每个特征都应该结合业务进行设计,比如其中统计类特征需要考虑聚合的时间窗口,序列特征需要考虑序列的长度,这些都可以根据实际情况进行取舍和选择。
在设计特征的基础上,算法工程师还需要推动上下游打通数据链路,校验特征质量,引入到现有模型中进行离线调研,要是小流量AB实验有置信收益,新版特征就可以全量生效。一个常见的挖掘特征的手段,便是基于内容理解算法,利用自然语言处理、计算机视觉、语音识别等等,对内容进行深度挖掘,生产优质特征,从而让模型更容易捕获用户兴趣点。根据业务需要在持续迭代的过程中,会不断新增有效特征,旧的失效特征也会慢慢下线,在我们的业务场景中,模型使用的特征数也在迭代的过程相对增加了30%,系统的分发效率也有很大的提升。特征对模型预估的重要性可以通过auc-diff进行评估,为了系统的稳定性,还需要实时监控线上每个特征的覆盖率和取值分布情况,避免异常数据影响大盘。
2.1.2 特征处理
在推荐系统中使用的所有特征,按照特征结构和处理方式的不同,可以分为四类。
数值型特征,特征的原始值是一定区间内的连续值,比如动态后验CTR、视频时长、点赞数等等,通常处理方式如下
-
可以增加对特征异常值的鲁棒性、提升非线性能力、加快算法处理性能、方便特征交叉
-
会丢失部分信息、边界离散值的跳变会影响模型预估稳定性
-
可以采用等宽分箱、聚类分箱、等频分箱、决策树分箱和卡方分箱等方式
-
特征最大最小归一化、标准化等等
-
连续特征离散化
-
非线性变换,比如常用的log(x+1)等等
单值离散特征,一个样本只有一个离散取值,比如手机型号、用户性别等等
-
One-Hot编码
-
查LookUp表,得到向量表征
多值离线特征,一个样本可以有多个离散取值,比如用户点击序列、Item标签等等
-
人工生成交叉特征
-
查LookUp表,得到多维向量,可采用拼接、Pooling、Attention等方式生成融合后唯一的向量表征
KV特征,一个样本Key可以有多个离线取值,并有与之对应的Value值
-
Key和Value离散化后,加权使用
-
可以将Key和Value进行拼接后,离散化使用
在推荐系统领域,在上表各式各样的特征中,有两种类型的特征很具备推荐特色,并在不同的业务上往往都是算法工程师大力投入,基本会取得不错收益的技术点。
2.1.3 高维稀疏类别特征
第一个就是高维稀疏的类别特征,这类特征由于其高维稀疏性,在向量空间上具备更好的线性可分性,从而模型更容易记住样本。对于一个相对成熟的推荐系统来说,此类特征的维度可达到上亿维,甚至几十亿维。
为了让模型顺利使用这么大的高维特征,需要算法联合工程做很多深度优化工作。一般采用的解决方案是动态弹性特征(EmbeddingVariable),可以解决静态特征词表大小难预估、特征冲突、内存和IO冗余等问题,并能够通过特征准入、特征退场、底层哈希表无锁化和精细化内存布局等措施,来提高存储和访问效率。随着动态弹性EV特征的引入,在得物社区的各个场景上均有着不错的收益。
2.1.4 交叉特征
另外一个就是大名鼎鼎的交叉特征。交叉特征是通过多个特征进行交叉组合而来,能够有效地增强模型的表达能力。这些年来算法工程师在特征交叉上尝试了大量的工作,总体来说分为显示交叉和隐式交叉。
显式交叉是基于先验知识,算法工程师人工构造交叉特征,一般可以采用的交叉形式有如下三种。其中笛卡尔积由于效果好更常使用,但笛卡尔积可能会发生维度爆炸,所以需要根据实际业务的数据分析情况来构造笛卡尔积。举个例子,在我们的场景中,每个用户在不同类目上兴趣偏好会有所区别,为了让系统在给用户提供服务时更关注这一点,可以在模型中尝试引入用户偏好和动态类目的交叉特征,提升用户体验。
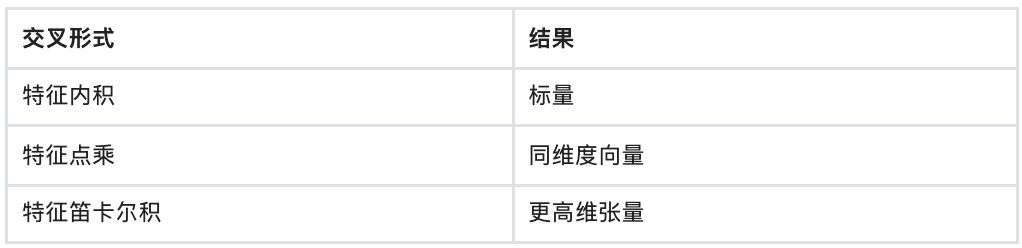
隐式交叉是通过网络结构让模型自动学习交叉,随着交叉技术的发展,算法工程师更多时候使用的方式是隐式交叉,不仅可以解除对人工经验的依赖,同时可在模型训练过程中不断自我优化。近些年在这方面经典的工作主要是FM、FFM、Wide&Deep、DeepFM、DCN和CAN等结构,其中DeepFM更是由于其结构简单、效果突出,在不同的推荐场景下均可作为比较好的基准。
作为特征交叉结构的经典集大成者,DeepFM可以实现端对端的低阶和高阶特征交叉融合。其中FM结构可以进行低阶特征的交叉,提升模型的记忆能力;Deep结构进行高阶特征的交叉融合,提高模型的泛化能力。得物社区最早期的时候,在排序层面,精排模型只是对CTR进行建模,模型架构就采用了比较成熟的DeepFM。

2.2 样本
对于一个推荐系统,模型训练样本和特征决定了模型效果的上限,一个高质量的训练样本集能够有效提高精排模型的预估能力。样本的产生需要依赖线上日志,一个优秀的生产样本流的框架会涉及多方,包括前端埋点、推荐引擎、预估服务和数仓等等。为了对业务效果负责,算法工程师除了关注模型本身外,还需要对样本质量进行监控,与上下游一起确保高质量样本生产的稳定性。
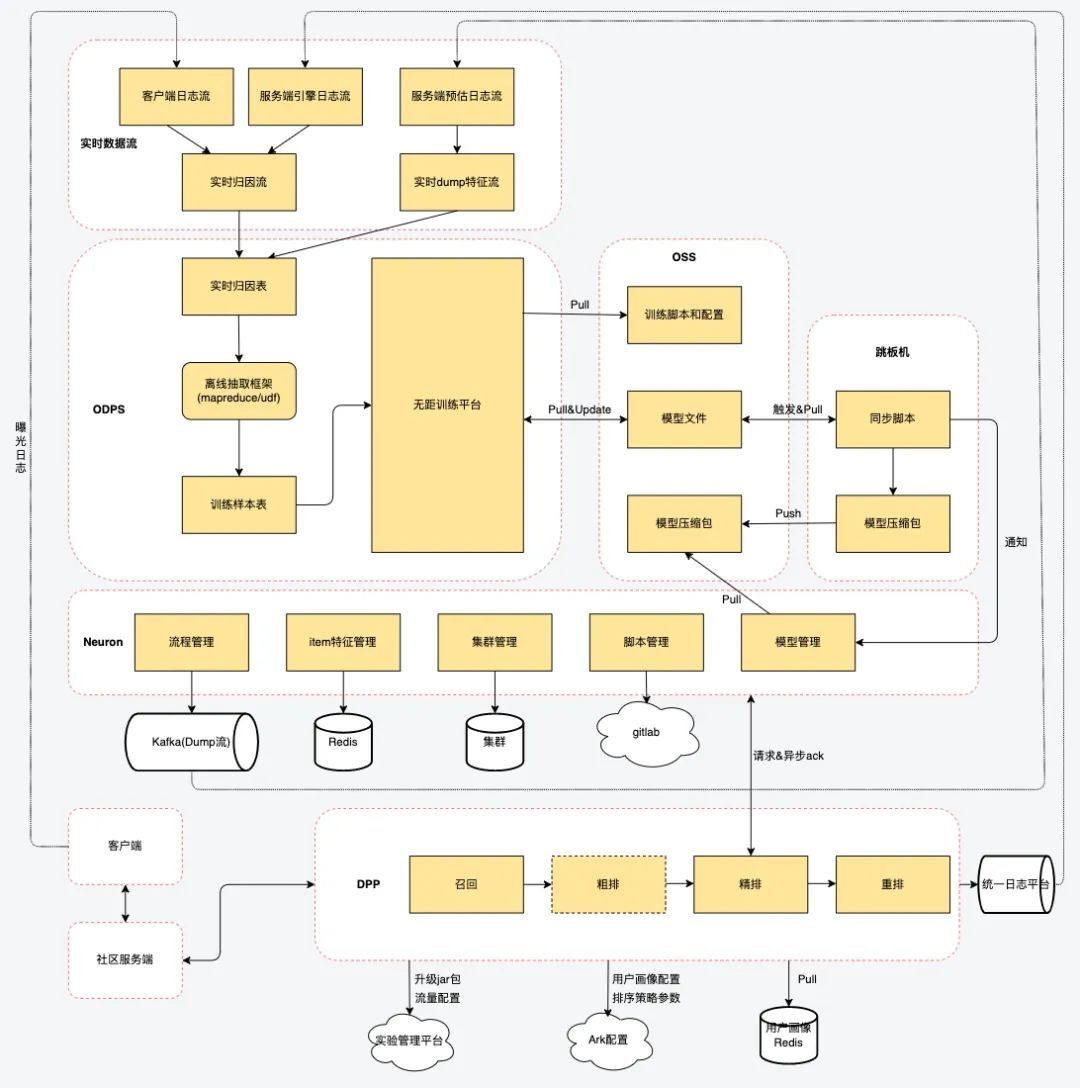
2.2.1 实时样本流架构
得物社区早期时,模型训练样本是基于离线特征表和离线用户行为表拼接而成,除了会有明显的时效性问题外,还可能会发生样本特征线上线下不一致性问题,影响系统整体的分发效率和分发效果。
为了解决高质量样本生产的问题,我们通过协调资源,设计和推动多方搭建了实时样本流框架。通过实时样本流生产样本,样本的时效性大幅提升,从天级到分钟级,从而可以支持实时模型的上线,也为后续算法模型的快速迭代打下了坚实的基础。
实时数据流架构可以概述为三条日志流的生产、归因和拼接。
-
第一条数据流是客户端日志流,它是基于客户端埋点通过触发事件上报埋点信息而来,埋点数据包含了服务端下发给客户端的(reqid, userid, itemid)三元组等信息。用户在浏览信息流时,会持续触发曝光、点击、点赞等行为数据,从而客户端日志流源源不断生产数据。
-
第二条数据流是服务端引擎日志流,它是根据客户端发起的用户请求,经过服务端和整个推荐引擎,拿到推荐结果并返回给客户端这个过程中,在引擎落下的重要信息,同样包括(reqid, userid, itemid)三元组、推荐结果以及正排信息等。
-
最后一条数据流是在预估服务落下的预估日志流,它是引擎将用户画像和召回或者粗排的结果下发到预估机器,由预估机器中的精排模型进行打分,在这个过程中会将模型使用的item特征和user特征等特征信息dump下来。特征流的数据量也是三个流中最大的,往往需要通过ACK的形式降低dump的物品数,从而有效节约资源。
三条日志流可以通过(reqid, userid, itemid)三元组进行有效关联,从而形成实时归因大宽表。其中,客户端日志流提供了用户真实反馈标签,服务端引擎日志流提供了推荐引擎各环节的信息,预估服务日志流提供了模型使用的特征信息,保证了线上线下特征一致性。
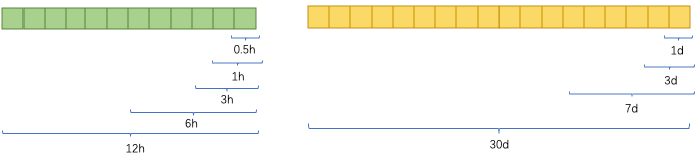
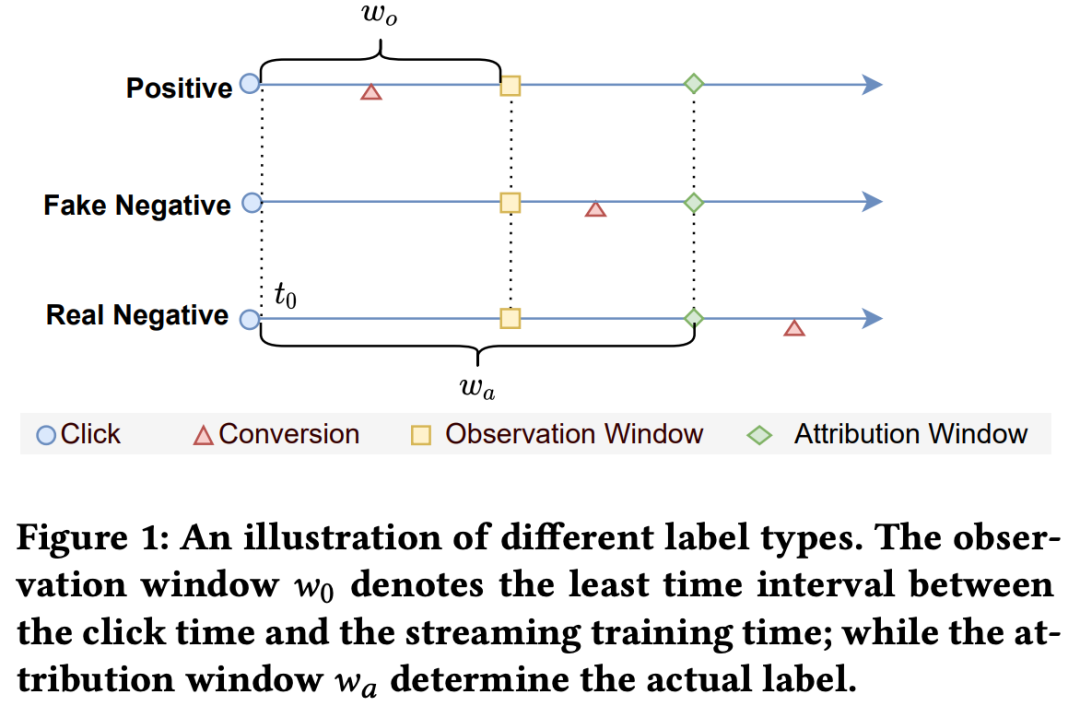
在使用实时样本流生产实时样本的过程中,会遇到一个经典的问题,那就是“用户延迟反馈”。这是由于从曝光埋点上报数据,到用户对动态进行点击和更深度的交互行为,这两个事件往往存在一定的时间差。比如用户在观看一个视频时,过了几分钟看完后才会对视频进行点赞和评论,此时如果我们对归因设计不合理就会造成这条实时样本是负样本。一般对用户反馈标签进行归因时,会考虑归因的时间窗口。离线表的归因窗口可以理解为1d,不过实时计算是在内存中实现的,出于对成本的考虑,很难设到很大的窗口,可以结合分析真实的业务数据情况,在成本、时效性和标签准确性之间找到合适的平衡点。在我们的场景上,通过选取合适的阈值,最后实时样本表的正标签达到了离线表的95%。对于延迟样本,一个有效的解决方案是设计不同的样本回补机制,基于重要性采样对样本分布进行纠偏。
2.2.2 采样
CTR模型为了预估用户浏览到的曝光中会进行点击的概率,是一个二分类模型。直观上建模时,会将用户点击作为正样本,曝光未点击作为负样本。但由于用户点击行为相对稀疏,这种直接构建训练样本集的方式,会造成正负样本严重失衡,有些场景可能低于1:100,训练效果往往不够好。
为了解决类别不均衡问题,一个常用的做法就是对负样本进行采样,只有通过一定策略采样后的负样本可以用来训练模型。负采样有很多实现方式,一般会根据采样质量、采样偏差和采样效率进行取舍,大体分为人工规则采样和基于模型采样。其中,常用的人工规则采样是随机负采样和基于流行度负采样,基于模型采样本质上是通过模型迭代优化负样本的质量,一般借鉴Boosting和GAN对抗学习的思想,不断挖掘强负样本,这块近期比较好的工作便是SRNS。
在我们场景上,目前是通过随机丢弃负样本的方式来实现采样的。采样后训练的模型预估出来的pctr与真实后验点击率CTR是有偏差的,所以线上使用预估分pctr时需要先用如下转换公式进行修正,然后在排序时使用。除了采样外,另外一个可以尝试的解法是在训练时通过对不同样本的Loss进行调权,也可以缓解类别不均衡带来的影响,不过调权任务比较繁重,可能一时很难调到理想的效果,预估分也难以还原。
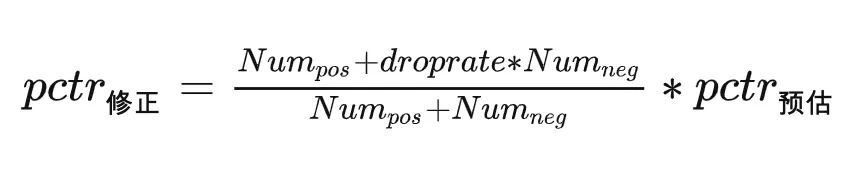
对于一个业务场景,往往会关注多个业务指标,除了点击之外,另一些重要的关注点是用户点击后的后续行为。对于电商场景一般是收藏商品、下单商品等用户深层次行为,对于信息流场景更多的是观看时长、点赞、评论等用户交互行为。这些转化行为是用户点击之后发生的,如果在点击样本空间上对互动进行建模,线上直接使用会产生bias,称为样本选择偏差,多目标联合建模时可以通过设计特定的模型结构来解决。
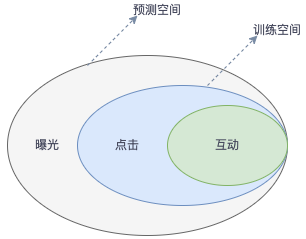
在得物社区场景,我们根据线上遇到和发现的一些问题,在样本层面也做过其他的探索和实践。
-
像评论、关注、分享等这些用户转化信号一般比较稀疏,单独建模的话模型训练不够充分很难取得好的效果,与点击联合训练又会被更密集的点击信号带偏。一种有效的解法是对同类型信号进行聚合使用,同时对这些信号重采样缓解点击信号的影响。
-
样本随机负样本对低活用户是不友好的,甚至会让曝光未点击用户逐渐流失。在负采样时需要考虑低活用户曝光未点击的样本,同时可以尝试在特征层面加上曝光未点击序列。
-
理想样本是在剔除噪音干扰的情况下,尽可能多的保留和基于先验知识提取真实场景的有效信息。其中一个可能有收益的信息就是用户样本的Session,所以建议试试基于用户Session构建样本。
2.3 多目标
相比单个目标建模,对多个业务目标进行建模会遇到更多的挑战,其中比较常见的问题就是多个指标之间会有跷跷板现象。为了缓解这些问题,在业界经过多年的实践和技术发展,积累不少的优秀模型ESSM、MMOE、PLE和ESCM等等,其中比较重要和应用广泛的模型是ESSM、MMOE,它们在很多业务场景都有着不错的效果,在得物社区场景,对多目标的建模也借鉴了相关模型的思路。

2.3.1 模型结构
2.3.1.1 首页双列流
随着业务的发展,得物社区首页推荐流精排模型也一直在迭代升级中,模型个性化能力不断提升,总的来说可以划分为四个阶段。
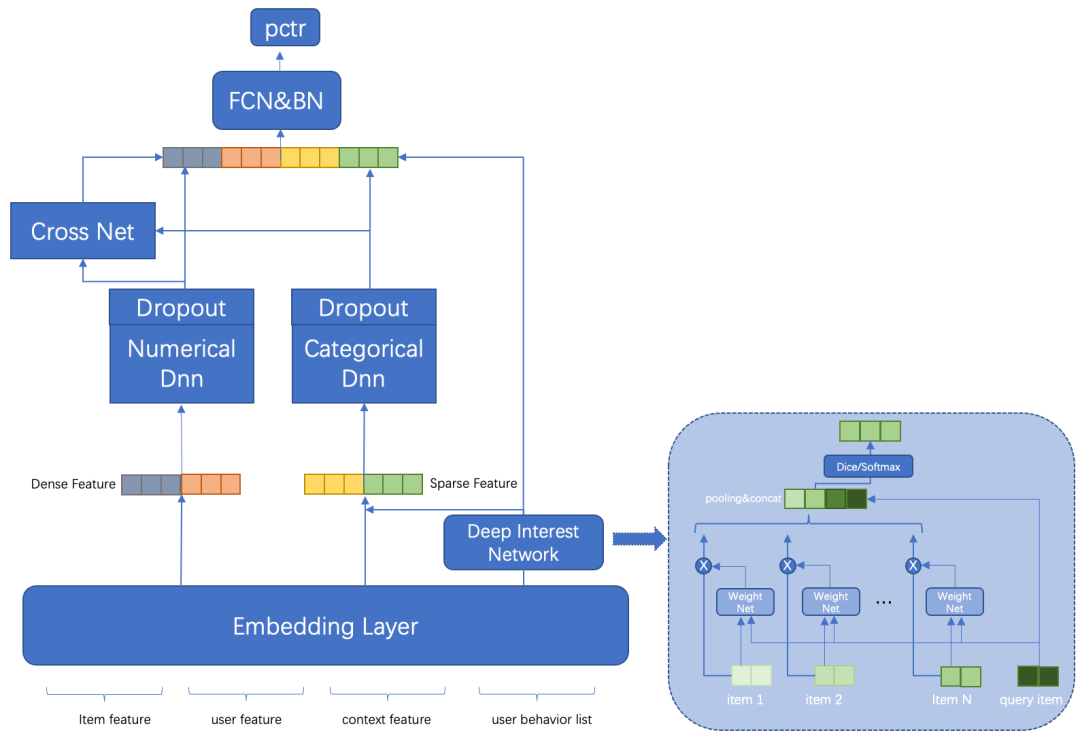
第一阶段是早期时候,只对用户点击率建模,精排层只有CTR模型。期间经过几次迭代,从开始的DeepFM结构,到结合业务特点的DLRM结构,特征交叉能力明显提升,以及增加了提取用户深度兴趣的DIN模块,都取得了不错的收益。
-
CTR模型
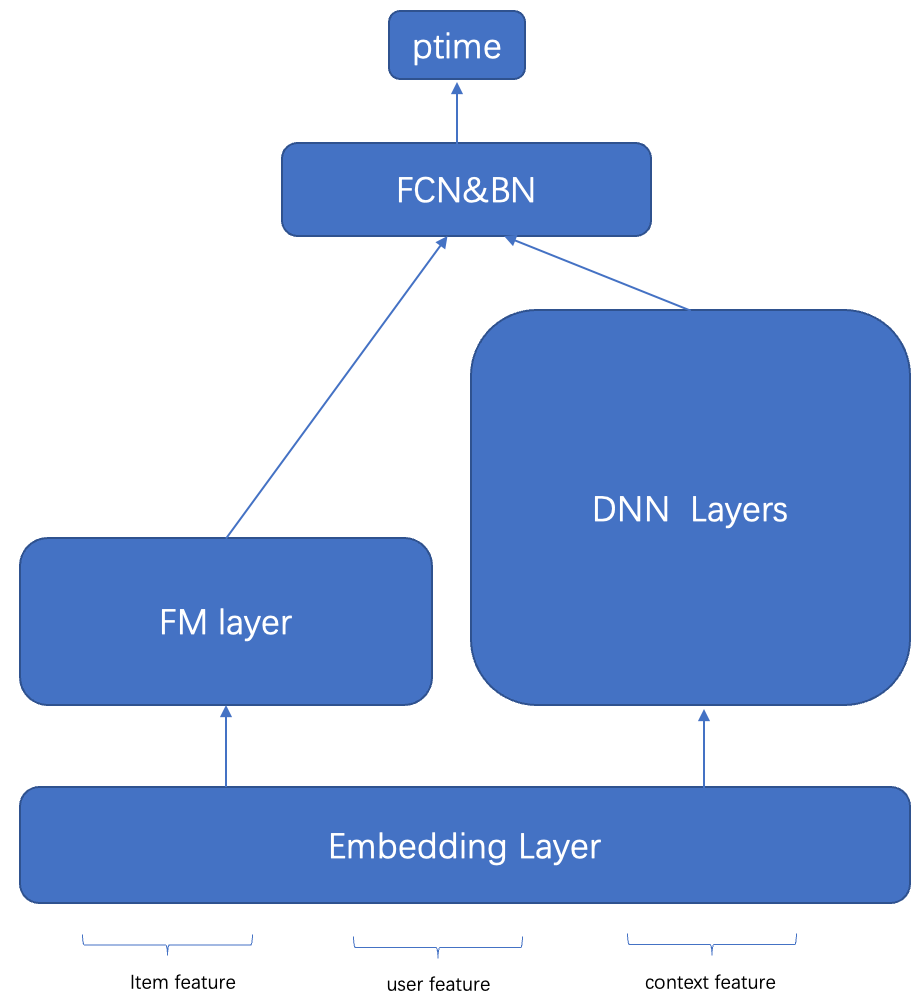
第二阶段是增加了对用户时长的单独建模,希望提升系统对用户时长的预估能力,精排层会有CTR模型和时长模型。时长模型第一版采用了比较成熟DeepFM结构,在CTR损失兑换可接受的情况下,带来大盘人均时长相对提升+3%。
-
时长模型
第三阶段是对用户点赞、关注、收藏、评论和分享等互动行为与用户时长联合建模,借助互动信号更好地捕获用户兴趣点,精排层会有两个模型,包括CTR模型和时长互动双塔模型。通过对多目标分融合公式进行有效调参后,在其他指标基本持平情况下,大盘互动用户渗透率,相对提升+6%。
-
时长互动双塔模型
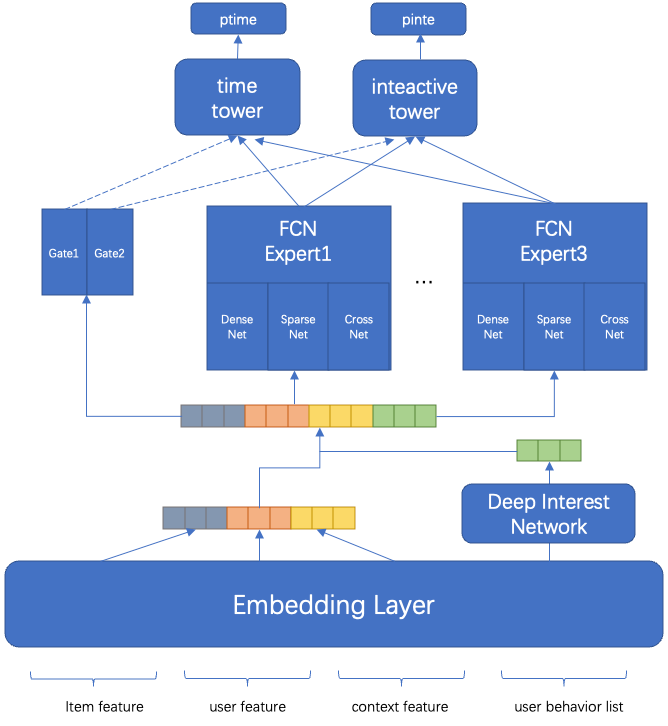
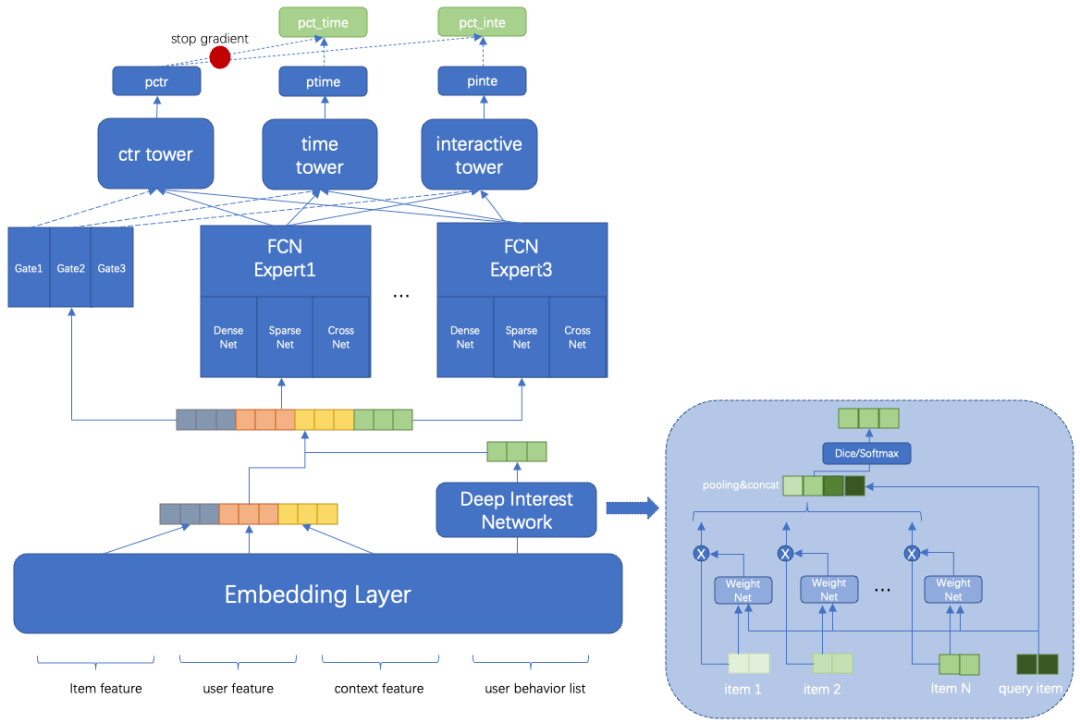
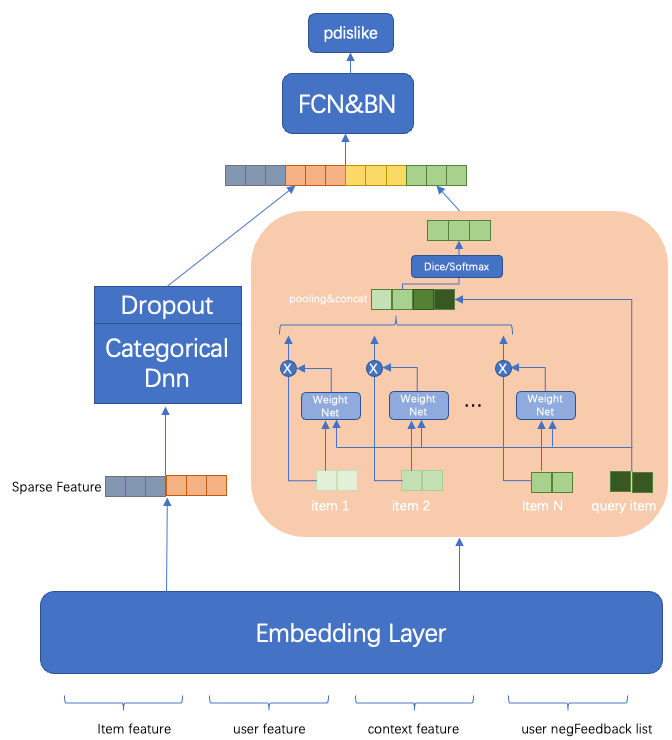
第四阶段是用户点击、用户时长和用户互动等多目标统一建模,并对用户负反馈单独建模,更好地整合精排层对用户兴趣的建模能力,精排层会有两个模型,即点击、时长和互动等多目标模型,以及负反馈模型。相对双塔模型,多目标模型更需要在结构上能够适配更多目标,尤其需要解决CTR任务和稀疏任务的相互影响。通过在训练时基于pct_time和pct_inte节点构建损失函数,并对pctr节点进行梯度阻断,使得能够对多个目标在曝光空间上统一进行建模。线上使用ptime和pinte作为时长和互动的预估分,融合公式可以做到线上线下一致,有助于在线上拿到离线调研的收益。上线后大盘ctr相对提升+2.3%,人均时长相对提升+0.33%,互动用户渗透率相对+4.5%。负反馈模型分在机制层通过平滑降权的形式生效,大盘负反馈率相对降低16%。
-
多目标模型
-
负反馈平滑降权
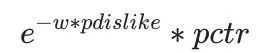
-
负反馈模型
2.3.1.2 沉浸式视频单列流
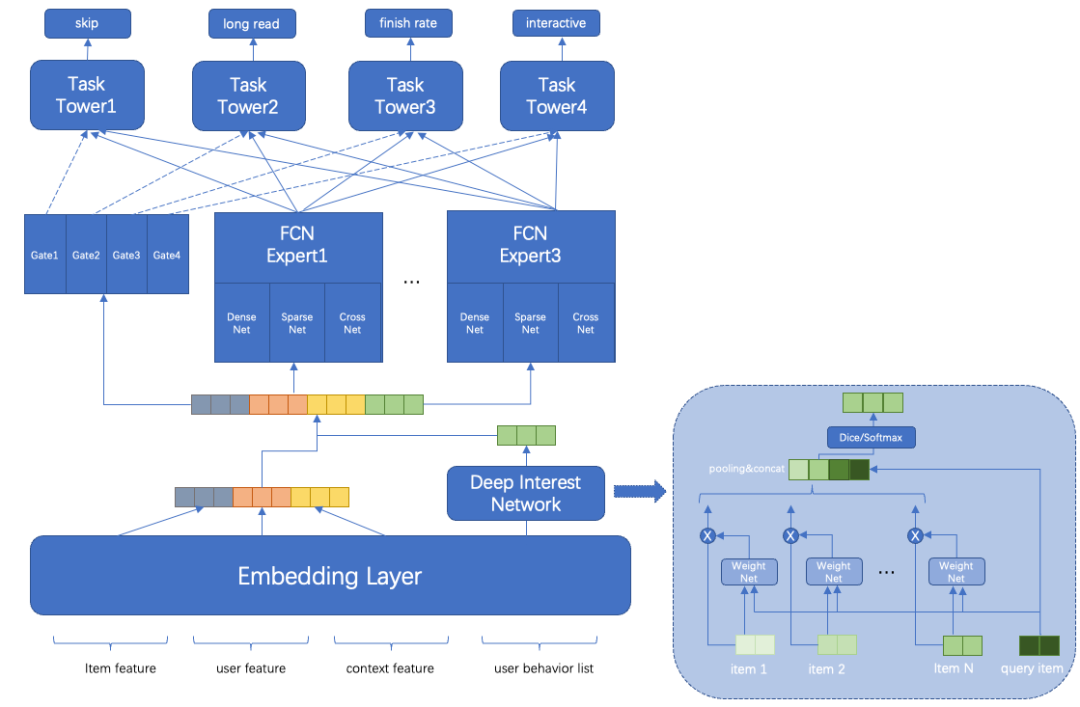
与首页双列流产品形态不同的是,沉浸式视频推荐流是单列流场景,用户通过不断下滑观看不同的视频。针对场景特点,最开始的建模思路是从视频完成度进行切入的,模型会预估用户会观看视频时长占视频本身时长的比例pfinish_rate,线上使用时会结合视频本身时长videoTime,并对videoTime双端进行限制缓解视频本身时长带来的bias,最后使用pfinish_rate*truncated(videoTime) 作为排序分。与首页主场景一样,在后面的迭代过程中,也增加了对用户互动行为的建模,在对互动预估分pinte和完成度预估分pfinish_rate进行融合时,不出意外也遇到跷跷板现象,通过不断实验尝试,最后采用级联排序的形式取得了收益。
通过几个版本持续迭代优化,场景核心指标提升明显,场景访问uv人均时长相对提升+46%,曝光互动率相对提升+15%。结合视频场景特殊性,通过对业务指标的分析,最近我们在考虑对用户短播行为和长播行为进行建模,更好的捕获用户兴趣点,为用户提供更贴心的视频推荐流服务。
-
多目标模型
2.3.2 多目标融合
多目标建模除了模型本身,另一个主要的挑战就是线上如何有效地使用多个目标分?我们希望通过合适的排序目标和机制设计,让业务关注的目标都能够有收益,做到多个目标共同提升,针对这个问题在我们场景上也进行了各种不同的尝试。
第一类比较直接的解决方案就是设计公式,对多个目标分使用公式进行融合,从而作为最终排序分。此方案的好处就是简单、明确,可以根据权重知道每个目标分是怎么对最终排序生效的。其中一个常用的技巧就是由于不同目标的预估分分布差异大,预估分绝对值的变动会影响调参结果,所以可以考虑使用单个目标分排序后的序号,将其通过合理的归一化后,再对多个目标进行融合。缺点就是不同的模型上线都需要手动调参,带来很大的工作量,并且融合公式也没有根据不同用户做到个性化融合,影响整体排序效果。在得物社区场景,我们先后设计了两版融合公式,第二版加法形式取得了更好的收益,同时参数量也有效降低。
-
人工公式融合
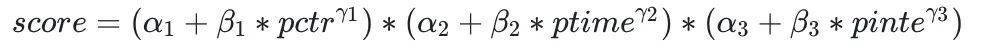
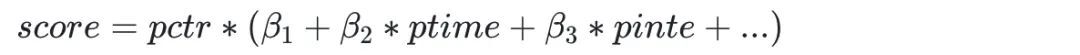
第二类解决方案是希望借助深度模型来端对端的生成最终排序分,避免人工调参,同时在融合时会考虑个性化。具体思路是构造一些用户侧、物品侧重要的基础特征,以及多个模型的预估分,将它们作为一个简单网络的输入,利用离线训练的模型产生最终融合分。一个关键点就是离线模型Label的构造,一般是通过对多个目标加权的方式进行聚合,权重的选择需要结合业务和线上实验的效果进行调试。缺点是精排层需要多调用一个模型,需要更多的资源,另外就是有时业务上需要做一些生态上的调整,模型融合没有公式来的快捷。
-
独立融合模型
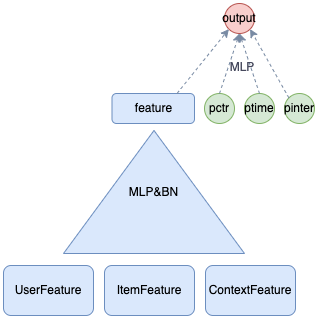
第三类也是目前正在尝试的解决方案,即个性化融合多目标模型架构。我们希望在多目标模型的基础上,通过构造融合模块,将多目标预估和多目标预估分融合放到一个完整的网络框架下。模型训练时损失函数可以分为两块,主网络损失和融合网络损失,主网络损失是为了优化模型对各个目标分的预估,融合网络损失是从整体上优化融合排序的结果,可以通过异步训练和梯度阻断的方式避免对网络相互造成干扰。理论上这种方案结合了前面两种方案的优化,同时避免了其缺点,希望经过调试后能够在我们的场景上推全这种方案,进一步整合精排模型的能力。
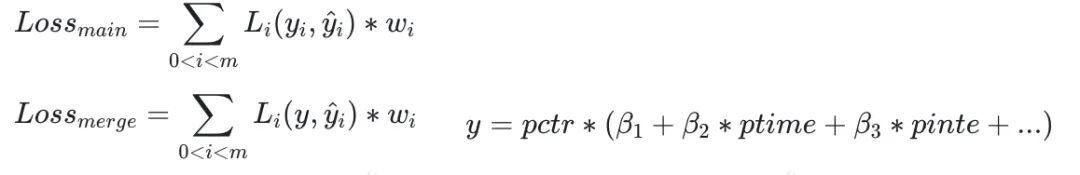
-
个性化融合多目标模型
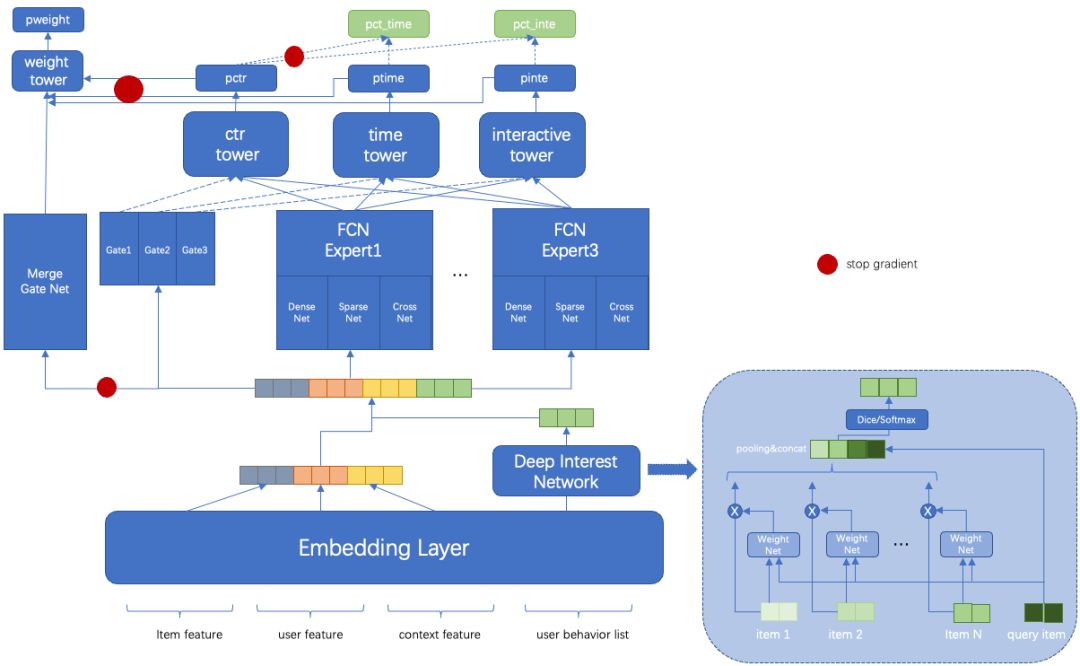
2.4 新用户冷启动
新用户冷启一直是业界的难点,主要体现在以下三点。为了解决这些问题,业界也有很多经典的工作,比如基于元学习的新用户MeLU、FORM模型等等,这些方案都是希望为新用户赋予比较靠谱的初始值,通过动态学习率快速调整从而收敛,但在实际应用时往往效果不佳。
新用户行为稀疏,对推荐结果更敏感
训练集新老用户样本分布不均匀,新用户样本占比往往低于1%
新用户人群和老用户人群特点差异大,由于老用户的主导,会导致模型难以捕捉到新用户人群行为模式
我们在得物社区首页双列流场景上也对新用户冷启动做了尝试,提升新用户冷启效率。基于对业务数据的分析和判断,从可推池、召回到精排、打散整个链路与主场景独立出来进行迭代,针对新用户特殊性,在精排层面从特征到模型结构均进行了单独的设计。
对于新用户冷启任务,个人认为如下技巧都是可以尝试的,在不同业务场景可能会有不一样的收益。
新用户样本重采样或者Loss加权,增加新用户样本的话语权
构造能够表征新用户人群的特征,比如新用户标识、用户首次访问时间等等
用户人群id代替新用户id,缓解新用户id学习不充分
从模型结构上突出新用户相关的特征,增加新用户特征的话语权
在我们的场景上,第一版模型是基于新用户有效点击的时长加权CTR模型,模型会更关注用户消费时长高的内容,从而帮助模型学习到新用户的兴趣点。为了进一步提升模型对不同新用户兴趣捕获能力,我们通过在模型结构上的设计了多目标poso模型,缓解新用户行为和样本稀疏的问题。通过在模型结构层面做到个性化,为相关人群带来更好的体验,全量后新用户ctr相对+2.69%,人均推荐时长相对+3.08%,人均互动数相对+18%,新用户次留相对+1.23%。
-
多目标poso模型

3.展望
本文主要介绍了面对业务中不断出现的挑战,我们从特征、样本、多目标建模和新用户冷启动等方向做的一些具体解法以及取得的一些进展。除了这些已经落地的技术外,我们还在其他方向了进行了探索,包括流行度纠偏、用户深度兴趣、FeatureStore以及超大规模分布式稀疏大模型,希望在后续进一步释放算法红利,保障和促进业务的增长。
4.引用
[1] Chen Y , Jin J , Zhao H , et al. Asymptotically Unbiased Estimation for Delayed Feedback Modeling via Label Correction[J]. 2022.
[2] Lee H , Im J , Jang S , et al. MeLU: Meta-Learned User Preference Estimator for Cold-Start Recommendation[J]. ACM, 2019.
[3] Sun X, Shi T, Gao X, et al. FORM: Follow the Online Regularized Meta-Leader for Cold-Start Recommendation[C]//Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2021: 1177-1186.
[4] Ma X, Zhao L, Huang G, et al. Entire space multi-task model: An effective approach for estimating post-click conversion rate[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 1137-1140.
[5] Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018: 1930-1939.
[7] Guo H, Tang R, Ye Y, et al. DeepFM: a factorization-machine based neural network for CTR prediction[J]. arXiv preprint arXiv:1703.04247, 2017.
[8] Naumov M, Mudigere D, Shi H J M, et al. Deep learning recommendation model for personalization and recommendation systems[J]. arXiv preprint arXiv:1906.00091, 2019.
[9] Zhang W, Qin J, Guo W, et al. Deep learning for click-through rate estimation[J]. arXiv preprint arXiv:2104.10584, 2021.
文/召俊

线下活动推荐: 得物技术沙龙「企业协作效率演进之路」(总第19期)
时间:2023年7月16日 14:00 ~ 2023年7月16日 18:00
地点:(上海杨浦)黄兴路221号互联宝地 C栋5楼(宁国路地铁站1号口出)
活动亮点:在当今竞争日益激烈的商业环境中,企业协作效率成为企业团队成功的关键。越来越多的企业意识到,通过信息化建设和工具化的支持,可以大幅提升协作效率,并在行业中取得突破。本次沙龙将涵盖多个主题,这些主题将为与会者提供丰富的思考和经验,助力企业协作效率的提升。
通过得物技术沙龙这个交流平台,您将有机会与其他企业的代表一起学习、借鉴彼此的经验和做法。共同探讨企业内部协作效率的最佳实践,驱动企业长期生存和发展。加入得物技术沙龙,与行业先驱者们一起开启协作效率的新篇章!让我们共同为协作效率的突破而努力!
点击报名: 得物技术沙龙「企业协作效率演进之路」(总第19期)
本文属得物技术原创,来源于:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!
作者:得物技术
链接:https://juejin.cn/post/7249576290533474359