组织方式
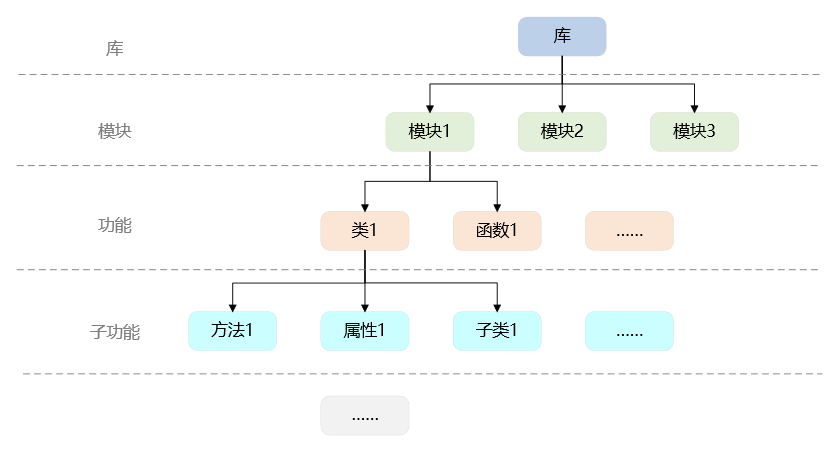
gma 整体按照库-模块-类/函数-(方法/属性/子类)的思路构建,详细思路如下所示:
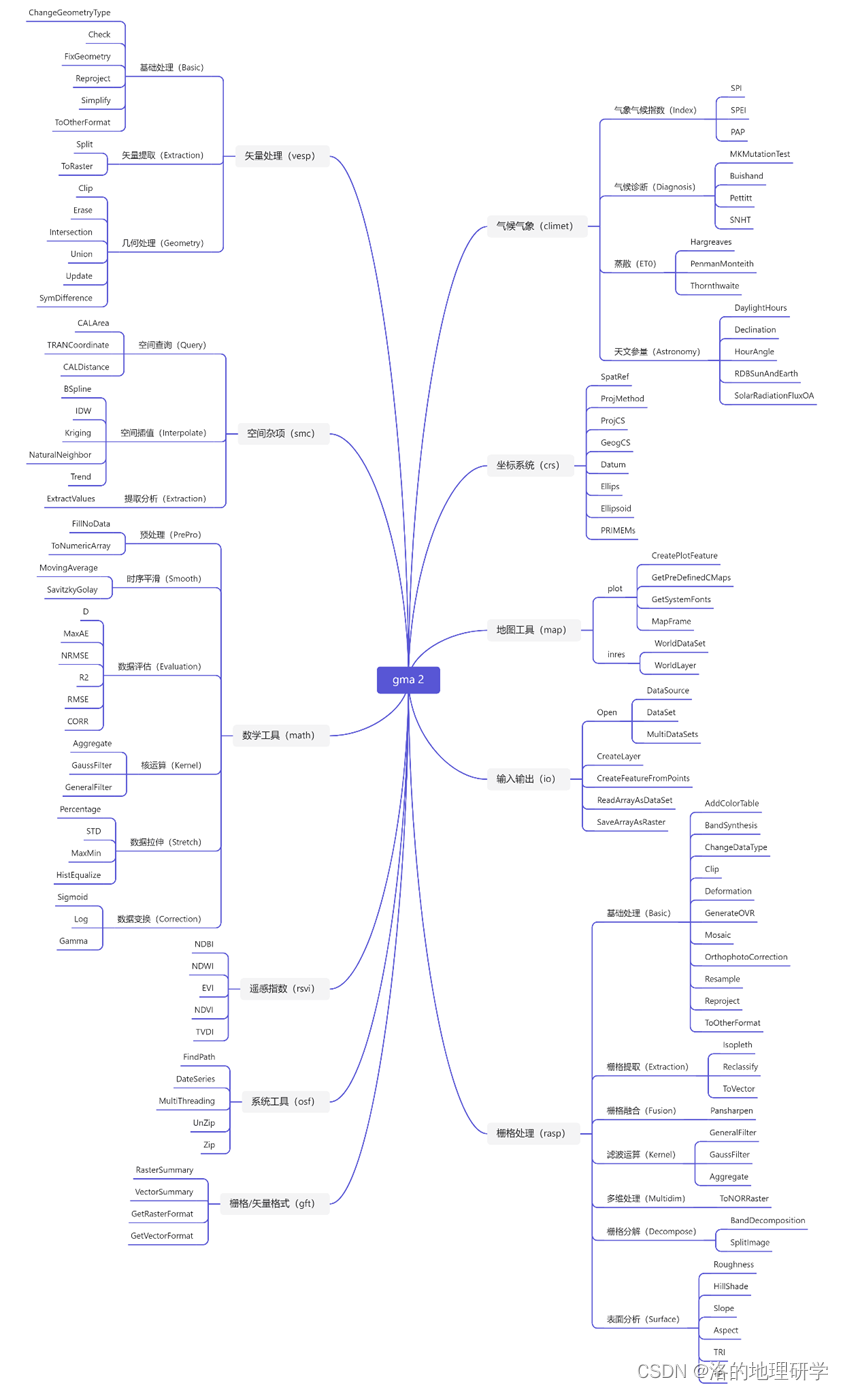
整体架构
gma内主要模块与功能对应关系见下表:
| 模块名 | 中文名 | 对应主要功能 |
|---|---|---|
| io | 输入输出 | 栅格/矢量数据输入输出模块 |
| crs | 坐标系统 | 坐标参考系统 |
| map | 地图工具 | 地理空间制图 |
| math | 数学运算 | 数学运算模块 |
| climet | 气象气候 | 气象气候模块 |
| rsvi | 指数运算 | 遥感指数计算 |
| rasp | 栅格处理 | 栅格处理工具 |
| vesp | 矢量处理 | 矢量处理工具 |
| gft | 驱动格式 | (地理数据格式) |
| smc | 空间杂项 | 空间计算工具 |
| osf | 系统交互 | 其他系统工具 |
库模块及主要函数分类:
命名约定
函数/类、参数的命名遵循以下规定:
单个单词: 首字母大写。例如:Clip。
多个单词: 每个单词首字母大写,多个单词直接连在一起。例如:ToOtherFormat。
缩写: 缩写单词全部大写。例如:GenerateOVR,OVR 为 Overviews 的缩写。
模块名的命名遵循以下规定:
不论缩写与否均使用小写。 例如:vesp(vector spatial processing)。
参数或返回值
gma内参数数据类型、返回值数据类型等以Python标准数据、NumPy和pandas数据类型为基础确定,主要包括:
| 类型 | 中文 | 标识/来源 | 示例 |
|---|---|---|---|
| list | 列表 | [ ] | [1, ‘a’, 2] |
| tuple | 元组 | ( ) | (1, 2, 3) |
| dict | 字典 | { } | {‘a’: 1, ‘b’: 2} |
| namedtuple | 具名元组 | collections.namedtuple | M(X=1, Y=2.1) |
| array | 数组 | numpy.array | [1 2] |
| mat | 矩阵 | numpy.mat | [1 2] |
| str | 字符串 | ’ ’ 或 " " | ‘str’ |
| int | 整型数 | 5、-1 | |
| float | 浮点数 | -1.0、5.5 | |
| DataFrame | 数据帧 | pandas.DataFrame | 参考 dict |
| Series | 数据系列 | pandas.Series | 参考 dict |
| DatetimeIndex | 日期时间索引 | pandas.DatetimeIndex | 参考 dict |
| bool | 布尔型 | True、False | |
| set | 集合 | { } | {1, 2, 3} |
| class | 类 | 参考 Python 类定义 |