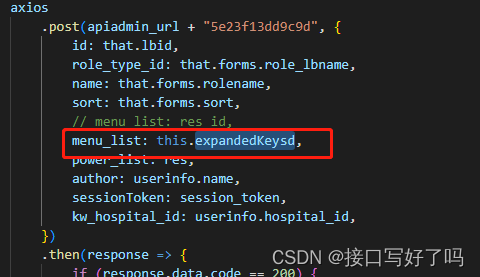
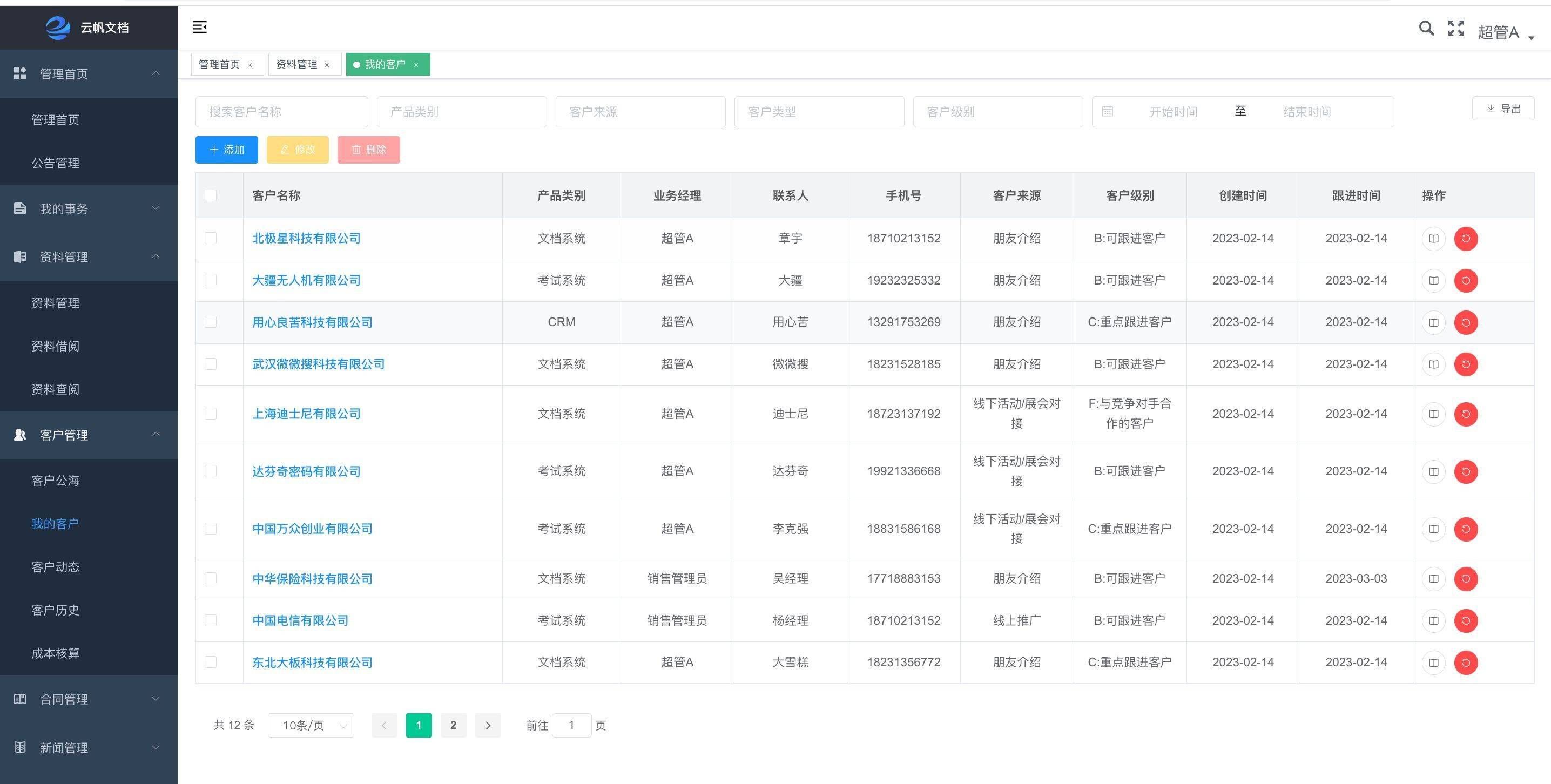
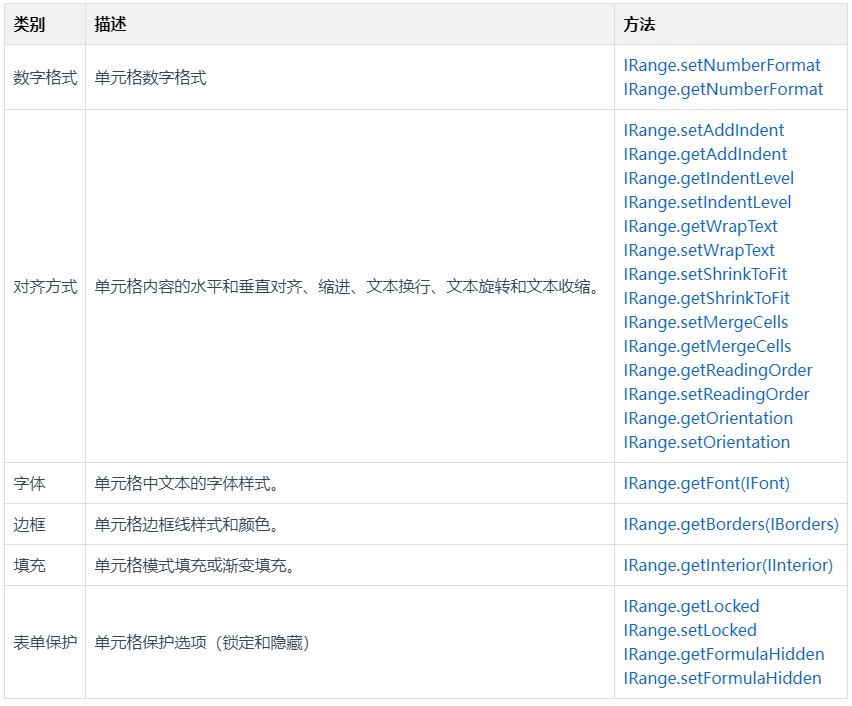
Vox-E: Text-guided Voxel Editing of 3D Objects (3D目标的文本引导体素编辑)

Paper:https://readpaper.com/paper/1705264952657440000
Code:http://vox-e.github.io/
原文链接:Vox-E: 3D目标的文本引导体素编辑 (by 小样本视觉与智能前沿)
文章目录
- Vox-E: Text-guided Voxel Editing of 3D Objects (3D目标的文本引导体素编辑)
- 01 现有工作的不足?
- 02 文章解决了什么问题?
- 03 关键的解决方案是什么?
- 04 主要的贡献是什么?
- 05 有哪些相关的工作?
- 06 方法具体是如何实现的?
- Grid-Based Volumetric Representation
- Text-guided Object Editing
- 1) Generative Text-guided Objective
- 2)Volumetric Regularization
- Spatial Refinement via 3D Cross-Attention
- 07 实验结果和对比效果如何?
- 08 消融研究告诉了我们什么?
- 09 这个工作还是可以如何优化?
- 10 结论
01 现有工作的不足?
这一领域的研究主要集中在仅外观的操作上,它改变了对象的纹理[44,46]和样式[48,42],或者通过与显式网格表示的对应关系进行几何编辑[13,47,45]——将这些表示与关于网格变形的丰富文献联系起来[18,39]。不幸的是,这些方法仍然需要将用户定义的控制点放置在显式网格表示上,并且不允许添加新结构或显着调整对象的几何形状。
02 文章解决了什么问题?
在这项工作中,我们提出了一种利用潜在扩散模型的力量来编辑现有的 3D 对象。
03 关键的解决方案是什么?
我们的方法以 3D 对象的定向 2D 图像作为输入并学习其基于网格的体积表示。为了引导体积表示符合目标文本提示,我们遵循unconditional text-to-3D方法并优化分数蒸馏采样 (SDS) 损失。
我们引入了一种新的体积正则化损失,直接在3D空间中操作,利用我们的3D表示的显式性质来加强原始和编辑对象的全局结构之间的相关性。
此外,我们提出了一种优化交叉注意力体积网格的技术,以细化编辑的空间范围。
04 主要的贡献是什么?
- 使用 3D 正则化绑定的耦合体积表示,允许使用扩散模型作为指导编辑 3D 对象,同时保留输入对象的外观和几何形状。
- 基于 3D 交叉注意的体积分割技术,该技术定义了文本编辑空间范围。
- 结果表明,我们提出的框架可以执行广泛的编辑任务,这是以前无法实现的。
05 有哪些相关的工作?
- Text-driven Object Editing
- Text-to-3D
06 方法具体是如何实现的?
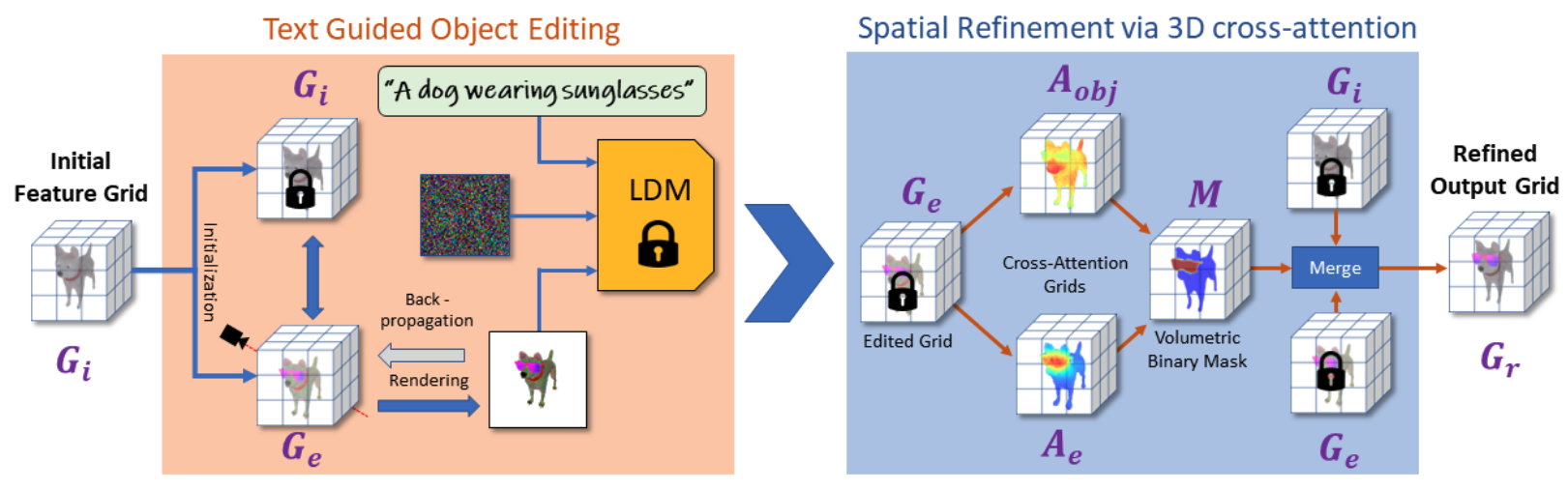
Grid-Based Volumetric Representation
我们使用 3D 网格 G,其中每个体素包含一个 4D 特征向量。我们使用单个特征通道对对象的几何图形进行建模,该通道表示通过 ReLU 非线性时的空间密度值。三个额外的特征通道表示对象的外观,并在通过 sigmoid 函数时映射到 RGB 颜色。请注意,与最近的神经 3D 场景表示(包括 ReLU Fields)相比,我们没有对视图相关的外观效应进行建模,因为我们发现当以 2D 基于扩散的模型引导时,它会导致不希望的伪影。
为了用基于网格的表示来表示输入对象,我们使用图像和相关的相机姿势来执行体绘制,如NeRF[28]所述。然而,与 NeRF 相比,我们没有使用任何位置编码,而是在每个位置查询中采样我们的网格以获得插值的密度和颜色值,然后沿着每条射线累积。在我们的渲染输出和输入图像之间使用简单的L1损失,以学习表示输入对象的基于网格的体积Gi。
Text-guided Object Editing
在上一节中描述的初始体素网格 Gi的基础上,我们通过优化 Ge 来执行文本引导的对象编辑,Ge 是一个网格,表示从 Gi 初始化的编辑对象。我们的优化方案结合了由目标文本提示引导的生成组件和鼓励新网格与其初始值没有太大偏差的回拉项。正如我们稍后所展示的,我们的耦合体积表示为我们的系统提供了额外的灵活性,允许通过直接在 3D 空间中进行正则化来更好地平衡两个目标。接下来我们描述这两个优化目标。
1) Generative Text-guided Objective
为了鼓励我们的特征网格尊重通过文本提示提供的所需编辑,我们使用应用于潜在扩散模型 (LDM) 的分数蒸馏采样 (SDS) 损失。形式上,在每次优化迭代中,使用随机时间步长 t 将噪声添加到生成的图像 x 中,

分数蒸馏梯度(按像素计算)可以被表示为:

其中w是是权重函数,s是输入的引导文本。
正如 Lin 等人所建议的那样[23],我们使用退火 SDS 损失,它逐渐减少我们从中得出 t 的最大时间步长,允许 SDS 在编辑轮廓形成后专注于高频信息。我们凭经验发现这通常会导致更高质量的输出。
2)Volumetric Regularization
我们提出了一个体积正则化项,它将我们编辑的网格 Ge 与初始网格 Gi 耦合。具体来说,我们结合了一个损失项,它鼓励输入网格 f i σ f_i^{\sigma} fiσ 的密度特征与编辑网格 f e σ f_e^{\sigma} feσ的密度特征之间的相关性:

这种体积损失比图像空间损失具有显著的优势,因为它允许将场景的外观与其结构解耦,从而将3D空间中的体积表示连接起来,而不是将其视为多视图优化问题。
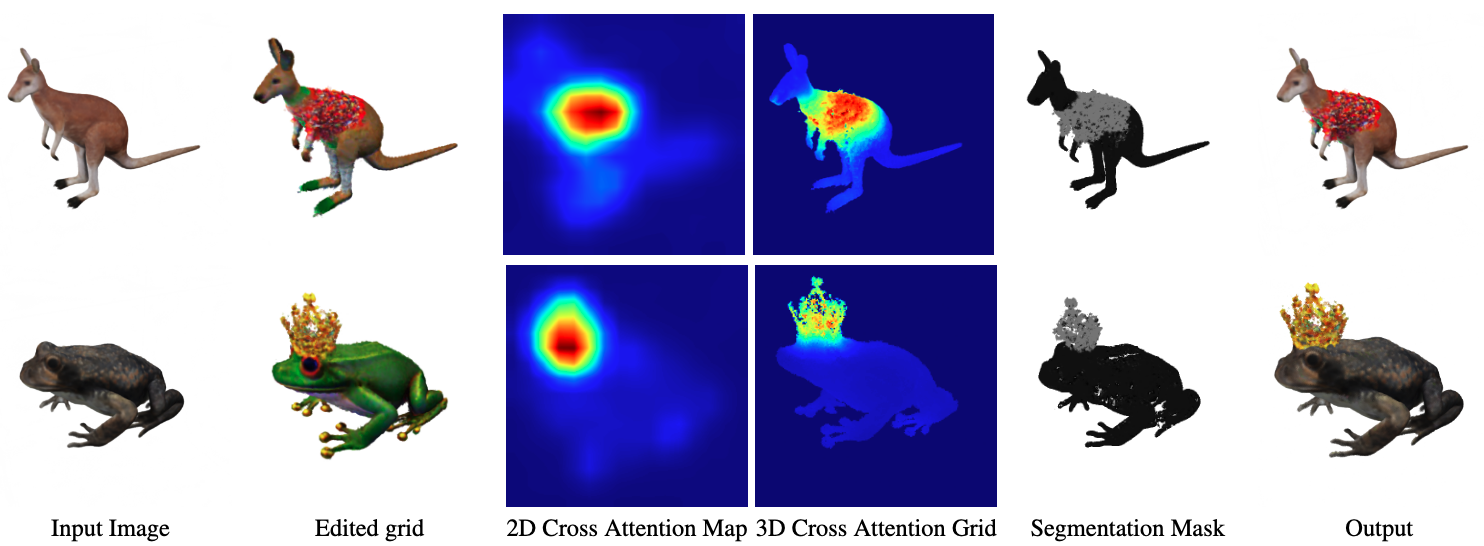
Spatial Refinement via 3D Cross-Attention
我们添加了一个(可选的)细化步骤,它利用来自交叉注意层的信号来产生一个体积二进制掩码M,该掩码标记了应该编辑的体素。然后将输入网格Gi与编辑后的网格Ge合并,得到精细化网格Gr:

我们使用基于能量最小化的seam-hiding segmentation算法将这些3D概率场转换为我们的二值掩码M[3]。我们将体素单元的标签概率定义为两个交叉注意网格 A e A_e Ae和 A o b j A_{obj} Aobj的element-wise softmax,其中:
- Ae是与描述编辑的标记(例如太阳镜)相关联的交叉注意网格,
- A o b j A_{obj} Aobj是与对象关联的网格是与对象关联的网格,定义为提示符中所有其他tokens的最大概率。
我们从编辑后的网格中的局部色差计算平滑项。也就是说,我们求和:

对于相邻体素p和q的每一对,其中cp和cq是来自Ge的RGB颜色。
最后,我们通过图切割[7]解决了这个能量最小化问题,得到了如图3所示的高质量分割蒙版。
07 实验结果和对比效果如何?
我们在图1、4、5、8、6、7中展示了不同3D对象和各种编辑的定性编辑结果

在图5中,我们证明了我们的方法也成功地使用Mildenhall等人[28]提供的360°真实场景建模和编辑真实场景。如图所示,我们的方法可以局部编辑前景(例如,将花朵变成向日葵)或背景(例如,将地面变成池塘)。
![Fig 5. 我们的方法在公开可用的360°真实场景上的定性结果[28]。我们在中间行显示从初始网格渲染的图像,在底部行显示从我们编辑过的网格渲染的图像。如上所示,我们的方法可以在这些真实场景上生成令人信服的编辑,而无需明确地对前景和背景区域进行建模。](https://img-blog.csdnimg.cn/img_convert/183c4b0ff426e1eb95482d6e8822588e.png#pic_center)
我们在图6中展示了对一个未着色网格的定性比较(可以在顶部一行观察到它的几何形状,因为Latent-paint保持了输入几何形状的固定)。如图所示,Text2Mesh不能产生显著的几何编辑(例如,给马添加圣诞老人帽子或把马变成驴子)。即使是允许几何编辑的SketchShape,也无法实现重要的局部编辑。此外,它不能保留输入的几何形状,该方法并不打算保留输入的几何形状。另一方面,我们的方法成功地遵循了目标文本提示,同时保留了输入的几何形状,允许对几何形状和外观进行语义上有意义的更改。
![Fig 6. 比较其他3D对象编辑技术。我们展示了使用Text2Mesh[27]和两种应用Latent-NeRF [26] (Latent-Paint和SketchShape)获得的定性结果,并与我们的方法进行了比较。为了适应他们的问题设置,所有方法都提供了未着色的网格。请注意,输入网格在顶部行是可见的(因为LatentPaint不编辑对象的几何形状)。如上所述,以前的方法难以实现语义本地化编辑。我们的方法成功了,同时保持了对输入对象的高保真度。](https://img-blog.csdnimg.cn/img_convert/3d5fcaeac476ca02072f22ea8eea32a0.png#pic_center)
我们在表1中对我们的数据集进行了定量评估。为了公平地比较所有方法在其训练域中的操作,我们使用没有纹理映射的网格作为所有基线方法的输入。如表所示,就CLIP相似度而言,我们的方法优于本地和全局编辑的所有基线,但Text2Mesh产生略高的CLIP方向相似度。我们注意到Text2Mesh在CLIP指标方面具有优势,因为它明确地优化了CLIP相似性,因此它的分数并不完全具有指示性。
![Tab 1. 定量评价。我们比较了3D对象编辑技术Text2Mesh[27]和SketchShape[26]在本地(上)和全局(下)编辑。*请注意,Text2Mesh明确地训练最小化剪辑损失,因此直接将它们与SkechShape和我们的比较是没有信息的。](https://img-blog.csdnimg.cn/img_convert/2c3023984da4519090c12d39ae4b2fc8.png#pic_center)
在图7中,我们比较了Latent-NeRF中提出的无条件文本到3d模型,以表明这种无条件模型也不能保证在不同的提示下生成一致的对象。我们还注意到,如果使用专有的大扩散模型[35],这个结果(以及我们的编辑)肯定会看起来更好,但尽管如此,这些模型不能保持身份。
![Fig 7. 与无条件文本到3d生成相比。我们通过比较Latent-NeRF[26]来比较无条件文本到3d的方法,为其提供如上所示的两个目标提示。我们将它们与我们的结果一起显示(LatentNeRF在左边,我们的在右边)。如上所述,无条件方法不能轻易匹配输入对象,也不能保证在不同的提示符上生成一致的对象。](https://img-blog.csdnimg.cn/img_convert/0f5be9198a98ce41adb8d046d675acd0.png#pic_center)
如图8所示,2D方法通常很难从不太规范的视图(例如,在狗的背上添加太阳镜)产生有意义的结果,并且还会产生高度不一致的视图结果。
![Fig 8. 与2D图像编辑技术的比较。我们将文本引导的图像编辑技术InstructPix2Pix (IPix2Pix)[8]和SDEdit[25]进行比较,为其提供不同视点的图像和目标指令文本提示(IPix2Pix为“给狗戴上太阳镜”,SDEdit和我们的方法为“带太阳镜的狗”)。我们在左边显示一个输入图像,在右边显示三个输出(侧面、正面和背面视图),其中最左边的输出对应于输入视点。我们展示了两个变体,一个添加了背景(顶部行),因为我们观察到白色背景通常对这些方法更具挑战性。如上所述,2D技术无法轻松实现与3d一致的编辑结果。](https://img-blog.csdnimg.cn/img_convert/e2571a0f99b52b51105b0155a546b3d3.png#pic_center)
08 消融研究告诉了我们什么?
我们在表2和图9中提供了消融研究。具体来说,我们去掉了体积正则化( L r e g 3 D \mathcal{L}_{reg3D} Lreg3D)和基于3D交叉注意的空间细化模块(SR)。在消除体积正则化时,我们使用单个体积网格,并使用基于图像的L2正则化损失对SDS目标进行正则化。


09 这个工作还是可以如何优化?
我们的方法适用于广泛的高保真度的3D对象编辑,然而,有几个限制要考虑。如图10所示,由于我们对不同的视图进行了优化,因此我们的方法尝试在不同的空间位置编辑相同的对象,因此在某些提示下失败。此外,从图中可以看出,我们的一些编辑由于属性绑定错误而失败,其中模型将属性绑定到错误的主题,这是基于大规模扩散的模型中常见的挑战[9]。最后,我们继承了体积表示的局限性。因此,真实场景的质量可以通过借鉴[6]等作品的想法(例如场景收缩来模拟背景)来显着提高。

10 结论
在这项工作中,我们提出了Vox-E,这是一个新的框架,利用扩散模型的表达能力进行3D对象的文本引导体素编辑。技术上,我们证明了通过将基于扩散的图像空间目标与体积正则化相结合,我们可以实现对目标提示和输入3D对象的保真度。我们还说明了2D交叉注意地图 可以在3D空间中执行定位。我们展示了我们的方法可以生成本地和全局编辑,这对现有技术来说是一个挑战。我们的工作使非专家可以轻松地修改3D对象,只需使用文本提示作为输入,使我们更接近民主化3D内容创建和编辑的目标。
原文链接:Vox-E: 3D目标的文本引导体素编辑 (by 小样本视觉与智能前沿)