我们都知道,在Golang中字符都是以UTF-8编码的形式存储,当我们使用range遍历字符串的时候,go会为我们取出一个字符(rune)而不是一个byte,例如以下例子,我们使用range迭代取出第一个字符“你”,并且打印输出取出的字符编码以及内容,接着我们使用取址方法观察内存中实际存储的内容是什么。
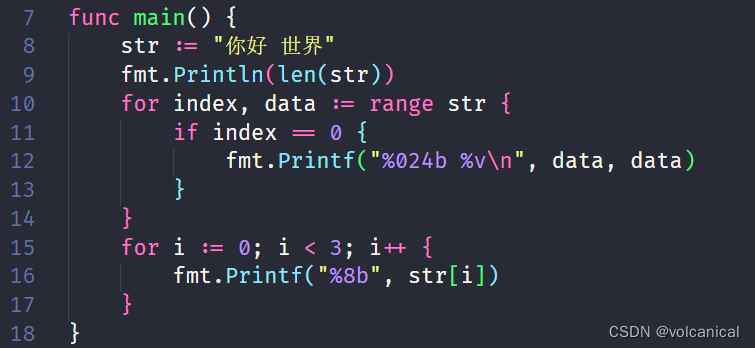
先说结论:
迭代器取出的是字符的Unicode编码,而内存里实际存储的是UTF-8实现。
输出结果如下图所示:
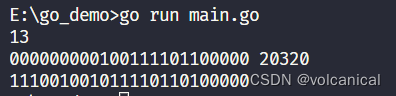
我们可以发现,迭代器取出的内容与实际存储内容不一致,这是因为:迭代器取出的是字符的unicode编码,“你”在Unicode编码里是第20320位,而真正在计算机内的实现方法采用UTF-8编码方式,本文将详细解释如何实现unicode到UTF-8的转变。
Unicode
统一码(Unicode),也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
统一码是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
统一码是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。统一码用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
为什么需要UTF-8?
我们已经有了Unicode编码,就有了一本字典,给每个字符一个编码,字符集序号一直从0-0x10FFFF。但是问题在于,单纯使用Unicode编码无法让计算机判断出哪里是一个字符,例如
00000001 00000001,计算机应该看成257还是两个1呢?这就涉及到如何实现变长编码,让unicode能够最大化利用计算机内存。现在普遍的实现方法就是UTF-8编码方式,将Unicode通过一定的转换方法变为UTF-8,使得计算机能够识别不定长的字符编码。
UTF-8编码规则
- 对于单字节的符号(英文字符),字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。如 A 在ASCII中是65,对应二进制 0100 0001
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
ASCII有128个字符,所以就是一个字节的后七位,第一位0代表单字节。
如果第一位是1,那么代表字节不完全,为多字节字符。计算机读取第一个字节的1个数,读到0时统计读到了多少个1,据此判断此字符几个字节。
那么为什么我们不直接用1开头表示多字节字符呢?为什么后续的字节开头需要使用10?
假设我们将后续字节设计为以1开头,那么UTF-8编码中的多字节字符的字节格式可能会产生冲突。例如,假设一个多字节字符的编码为:
110xxxxx 10xxxxxx
现在,如果后续字节以1开头,我们无法判断这个1是作为后续字节的一部分,还是作为下一个字符的起始字节。这会导致解析错误,无法正确识别字符的边界。
有人问,那我第一个字节都已经知道后面以后几个字节了,为什么还要用10开头呢,直接8bit全部用上不是更好吗?
UTF-8使用变长编码,这意味着字符占用的字节数是可变的。通过在第一个字节中指示字符占用的字节数,我们可以确定如何解析后续字节。然而,如果后续字节使用完整的8位来表示字符信息,会导致解码时的歧义和错误。
如果后续字节使用全部8位,就无法准确判断一个字节是属于哪个字符。通过将后续字节以"10"开头,我们可以明确地指示它们是后续字节,并且解码器可以根据这个特定的模式来解析UTF-8序列。这种设计保证了解码的自同步性,即即使在传输过程中发生了错误或数据丢失,解码器仍然能够正确地恢复每个字符的边界。
简单概括就是,即使丢掉了第一个字节的信息,后续也能根据每个字节的开头来判断处于哪个位置!
因此,为了明确表示多字节字符的后续字节,UTF-8编码规定后续字节必须以10开头。这样,我们在解析时可以准确地识别出多字节字符的起始和后续字节,避免了歧义和解析错误。