系列综述:
💞目的:本系列是个人整理为了秋招算法的,整理期间苛求每个知识点,平衡理解简易度与深入程度。
🥰来源:材料主要源于代码随想录进行的,每个算法代码参考leetcode高赞回答和其他平台热门博客,其中也可能含有一些的个人思考。
🤭结语:如果有帮到你的地方,就点个赞和关注一下呗,谢谢🎈🎄🌷!!!
🌈数据结构基础知识总结篇
文章目录
- 一、回溯算法理论基础
- 定义
- 二、回溯算法基本题目
- 77. 组合
- 39. 组合总和
- [39. 组合总和](https://leetcode.cn/problems/combination-sum/description/)
- 40.组合总和II
- 131. 分割回文串
- 93. 复原 IP 地址
- 1005. K 次取反后最大化的数组和
- 135. 分发糖果
- 406. 根据身高重建队列
- 452. 用最少数量的箭引爆气球
- 763. 划分字母区间
- 435. 无重叠区间
- 56. 合并区间
- 738. 单调递增的数字
- 参考博客
😊点此到文末惊喜↩︎
一、回溯算法理论基础
定义
- 回溯算法 = 穷举 + 剪枝
- 回溯算法解决的问题一般为npc问题,难以使用常规算法进行解决
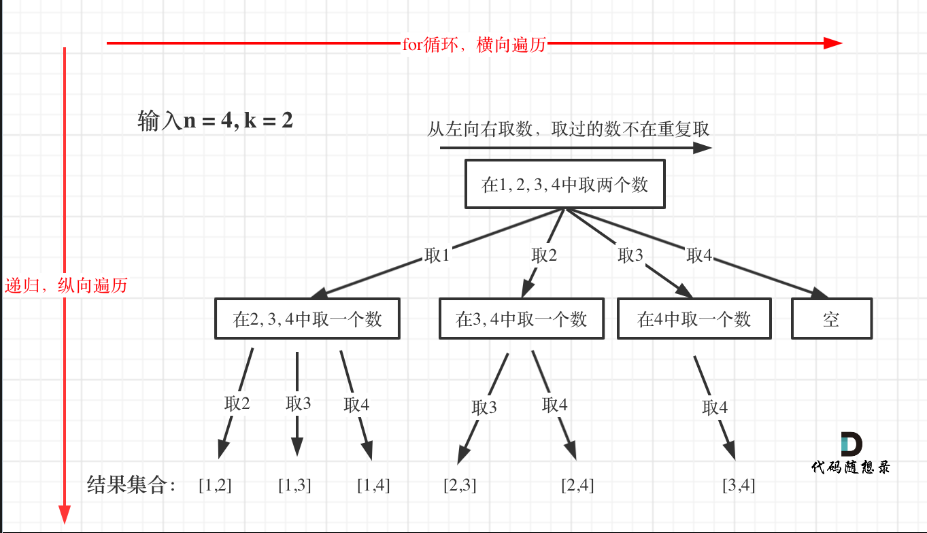
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
- 组合是不强调元素顺序的,排列是强调元素顺序。
- 所有的回溯法解决的问题都可以抽象为树形结构
- 回溯基本结构
- 根节点是总数据集合,树枝节点是可选数据集合
- 叶子节点为根节点到叶子节点的路径的选择集合
// 合法性判断 bool isValid(const type &data){ // type中数据项的合法性判断 } // 回溯函数 vector<vector<type> res; vector<type> path; void backtracking(vecotr<type> candidates, int startIndex) { // 路径值判断 if (符合条件isValid) { 存放结果; return; } // 延申和回撤路径时,可能涉及多个状态标记变量的改动 for (int i = startIndex; i < candidates.size(); ++i) { 剪枝判断; // 状态延申改动 path.push_back(candidates[i]);// 向下延申 backtracking(路径,选择列表); // 回溯 // 状态回撤改动 path.pop_back();// 回撤延申 } } // 主函数 vector<vector<int>> combine(vector<type>& candidates) { res.clear(); // 可以不写 path.clear();// 可以不写 backtracking(candidates, 0); return result; }
二、回溯算法基本题目
77. 组合
- 77. 组合
- 组合中的元素不能重复
// 函数式编程? vector<vector<int>> result; // 存放符合条件结果的集合 vector<int> path; // 用来存放符合条件结果 void backtracking(int n, int k, int startIndex) { // 递归结束条件:组合树的叶子节点的条件 if (path.size() == k) { result.push_back(path); return; } // 回溯的递归: for (int i = startIndex; i <= n; i++) { path.push_back(i); // 处理节点 backtracking(n, k, i + 1); // 递归 path.pop_back(); // 回溯,撤销处理的节点 } } vector<vector<int>> combine(int n, int k) { result.clear(); // 可以不写 path.clear(); // 可以不写 backtracking(n, k, 1); return result; }
39. 组合总和
-
39. 组合总和
vector<vector<int>> res; vector<int> path; void backtracking(vector<int> &candidates, int startIndex, int target, int sum){ // 结束条件 if (sum > target) { return ; } if (sum == target) { res.push_back(path); return ; } // 路径回溯 for (int i = startIndex; i < candidates.size(); ++i) { sum += candidates[i];// 路径值累加 path.push_back(candidates[i]);// 路径延申 backtracking(candidates, i, target, sum); sum -= candidates[i]; path.pop_back(); } } vector<vector<int>> combinationSum(vector<int>& candidates, int target) { res.clear(); path.clear(); backtracking(candidates, 0, target, 0); return res; }
40.组合总和II
- 40.组合总和II
- 集合(数组candidates)有重复元素,但还不能有重复的组合。
- 同一个层不可重复选取两个相同的元素
// 结果容器 vector<vector<int>> result; vector<int> path; // 回溯函数 void backtracking(vector<int>& candidates, int target, int sum, int startIndex, vector<bool>& used) { // if (sum == target) { result.push_back(path); return; } for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++) { // used[i - 1] == true,说明同一树枝candidates[i - 1]使用过 // used[i - 1] == false,说明同一树层candidates[i - 1]使用过 // 要对同一树层使用过的元素进行跳过 if (i > 0 && candidates[i] == candidates[i - 1] && used[i - 1] == false) { continue; } // 延申路径:改变状态机中路径相关变量,sum、path、used sum += candidates[i]; path.push_back(candidates[i]); used[i] = true; // 回溯函数 backtracking(candidates, target, sum, i + 1, used); // 回缩路径 used[i] = false; sum -= candidates[i]; path.pop_back(); } } vector<vector<int>> combinationSum2(vector<int>& candidates, int target) { vector<bool> used(candidates.size(), false); path.clear(); result.clear(); // 首先把给candidates排序,让其相同的元素都挨在一起。 sort(candidates.begin(), candidates.end()); backtracking(candidates, target, 0, 0, used); return result; }
131. 分割回文串
- 131. 分割回文串
- 获取
[startIndex,i]在s中的子串s.substr(startIndex, i - startIndex + 1)
// 判断是否为回文字符串 bool isPalindrome(const string& s, int start, int end) { for (int i = start, j = end; i < j; i++, j--) { if (s[i] != s[j]) { return false; } } return true; } // 基本的回溯 vector<vector<string>> result; vector<string> path; // 放已经回文的子串 void backtracking (const string& s, int startIndex) { // 如果起始位置已经大于s的大小,说明已经找到了一组分割方案了 if (startIndex >= s.size()) { result.push_back(path); return; } for (int i = startIndex; i < s.size(); i++) { // 剪枝与枝的延长 if (isPalindrome(s, startIndex, i)) { // 是回文子串 // 获取[startIndex,i]在s中的子串 string str = s.substr(startIndex, i - startIndex + 1); path.push_back(str); } else { // 不是回文,跳过 continue; } backtracking(s, i + 1); // 寻找i+1为起始位置的子串 path.pop_back(); // 回溯过程,弹出本次已经填在的子串 } } vector<vector<string>> partition(string s) { result.clear(); path.clear(); backtracking(s, 0); return result; } - 获取
93. 复原 IP 地址
- 93. 复原 IP 地址
str.insert(1,s);在原串下标为1的字符e前插入字符串sstr.erase(0);删除下标为0的字符
vector<string> result;// 记录结果 // startIndex: 搜索的起始位置,pointNum:添加逗点的数量 void backtracking(string& s, int startIndex, int pointNum) { if (pointNum == 3) { // 逗点数量为3时,分隔结束 // 判断第四段子字符串是否合法,如果合法就放进result中 if (isValid(s, startIndex, s.size() - 1)) { result.push_back(s); } return; } for (int i = startIndex; i < s.size(); i++) { if (isValid(s, startIndex, i)) { // 判断 [startIndex,i] 这个区间的子串是否合法 s.insert(s.begin() + i + 1 , '.'); // 在i的后面插入一个逗点 pointNum++; backtracking(s, i + 2, pointNum); // 插入逗点之后下一个子串的起始位置为i+2 pointNum--; // 回溯 s.erase(s.begin() + i + 1); // 回溯删掉逗点 } else break; // 不合法,直接结束本层循环 } } // 判断字符串s在左闭又闭区间[start, end]所组成的数字是否合法 bool isValid(const string& s, int start, int end) { if (start > end) { return false; } if (s[start] == '0' && start != end) { // 0开头的数字不合法 return false; } int num = 0; for (int i = start; i <= end; i++) { if (s[i] > '9' || s[i] < '0') { // 遇到非数字字符不合法 return false; } num = num * 10 + (s[i] - '0'); if (num > 255) { // 如果大于255了不合法 return false; } } return true; } vector<string> restoreIpAddresses(string s) { result.clear(); if (s.size() < 4 || s.size() > 12) return result; // 算是剪枝了 backtracking(s, 0, 0); return result; }
1005. K 次取反后最大化的数组和
- 1005. K 次取反后最大化的数组和
- sort的使用:第三个参数为自定义的排序队则,在头文件#include
- accumulate的使用:第三个参数为累加的初值,在头文件include
static bool cmp(int a, int b) { return abs(a) > abs(b);// 绝对值的从大到小进行排序 } int largestSumAfterKNegations(vector<int>& A, int K) { // 将容器内的元素按照绝对值从大到小进行排序 sort(A.begin(), A.end(), cmp); // 在K>0的情况下,将负值按照绝对值从大到小依次取反 for (int i = 0; i < A.size(); i++) { if (A[i] < 0 && K > 0) { A[i] *= -1; K--; } } // 如果K为奇数,将最小的正数取反 if (K % 2 == 1) A[A.size() - 1] *= -1; // 求和 return accumulate(A.begin(),A.end(),0); // 第三个参数为累加的初值,在头文件include<numeric> }
135. 分发糖果
- 135. 分发糖果
双向遍历进行贪心处理
int candy(vector<int>& ratings) { vector<int> candyVec(ratings.size(), 1); // 从前向后 for (int i = 1; i < ratings.size(); i++) { if (ratings[i] > ratings[i - 1]) candyVec[i] = candyVec[i - 1] + 1; } // 从后向前 for (int i = ratings.size() - 2; i >= 0; i--) { if (ratings[i] > ratings[i + 1] ) { candyVec[i] = max(candyVec[i], candyVec[i + 1] + 1); } } // 统计结果 int result = 0; for (int i = 0; i < candyVec.size(); i++) result += candyVec[i]; return result; }
406. 根据身高重建队列
- 406. 根据身高重建队列
两个维度遍历进行贪心处理- 常用插入操作使用list进行处理
- 感觉可以局部最优推出整体最优,而且想不到反例。就可以使用贪心算法。
// 身高从大到小排(身高相同k小的站前面) static bool cmp(const vector<int>& a, const vector<int>& b) { if (a[0] == b[0]) // 相等的,数量小的在前 return a[1] < b[1]; return a[0] > b[0];// 其他情况身高高的的在前 } vector<vector<int>> reconstructQueue(vector<vector<int>>& people) { sort (people.begin(), people.end(), cmp); list<vector<int>> que; // list底层是链表实现,插入效率比vector高的多 for (int i = 0; i < people.size(); i++) {// 按序插入 int position = people[i][1]; // 插入到下标为position的位置 std::list<vector<int>>::iterator it = que.begin(); while (position--) { // 寻找在插入位置 it++; } que.insert(it, people[i]); } return vector<vector<int>>(que.begin(), que.end()); }
452. 用最少数量的箭引爆气球
- 452. 用最少数量的箭引爆气球
- 贪心算法通常先进行
排序和最值处理
// 基本比较函数的使用:1.const &形参 2. 形参为比较的两个数据元素 3. 返回值为两个形参的比较 static bool cmp (const vector<int>& a, const vector<int>& b){ if(a[0] == b[0]) return a[1] < b[1]; return a[0] < b[0]; } int findMinArrowShots(vector<vector<int>>& points) { if(points.size() == 0) return 0; int count = 1;// 至少射一支箭 sort(points.begin(), points.end(), cmp); for(int i = 1; i < points.size(); ++i){ if(points[i-1][1] < points[i][0]){ count++; }else{// 记录最小下限 points[i][1] = min(points[i - 1][1], points[i][1]); } } return count; } - 贪心算法通常先进行
763. 划分字母区间
- 763. 划分字母区间
- 如果只有字母,可以使用数组进行哈希映射。
vector<int> alphabet = {27,0}
vector<int> partitionLabels(string s) { // 统计每个字符的最远坐标 unordered_map<char, int> umap; for(int i = 0; i < s.size(); ++i){ umap[s[i]] = i; } // 初始化 vector<int> res; int left = 0; int right = 0; // 迭代 for(int i = 0; i < s.size(); ++i){ right = max(right, umap[s[i]]); // 找到字符出现的最远边界 if (i == right) { res.push_back(right - left + 1);// 结果记录 left = i + 1; } } return res; } - 如果只有字母,可以使用数组进行哈希映射。
435. 无重叠区间
- 435. 无重叠区间
- 能读就不写:求数量的尽量不要改变改变原来数组,减少写操作。
static bool cmp (const vector<int>& a, const vector<int>& b) { return a[1] < b[1]; } int eraseOverlapIntervals(vector<vector<int>>& intervals) { if (intervals.size() == 0) return 0; sort(intervals.begin(), intervals.end(), cmp); int count = 1; // 记录非交叉区间的个数 int end = intervals[0][1]; // 记录区间分割点 for (int i = 1; i < intervals.size(); i++) { if (end <= intervals[i][0]) {// 记录最小的右边界 end = intervals[i][1]; count++; } } return intervals.size() - count; }
56. 合并区间
- 56. 合并区间
- 排序参数lambda表达式的使用
- 遍历的容器尽量不用动,使用新的结果容器进行处理
vector<vector<int>> merge(vector<vector<int>>& intervals) { // 健壮性检查 if (intervals.size() == 0) return result; // 区间集合为空直接返回 vector<vector<int>> result; // 排序的参数使用了lambda表达式 sort(intervals.begin(), intervals.end(), [](const vector<int>& a, const vector<int>& b){ return a[0] < b[0]; } ); // 第一个区间就可以放进结果集里,后面如果重叠,在result上直接合并 result.push_back(intervals[0]); // 合并区间,只更新右边界就好, // 因为result.back()的左边界一定是最小值,因为我们按照左边界排序的 for (int i = 1; i < intervals.size(); i++) { if (result.back()[1] >= intervals[i][0]) { // 发现重叠区间 result.back()[1] = max(result.back()[1], intervals[i][1]); } else { result.push_back(intervals[i]); // 区间不重叠 } } return result; }
738. 单调递增的数字
- 738. 单调递增的数字
- 数字转换成字符串处理
int monotoneIncreasingDigits(int N) { string strNum = to_string(N); // flag用来标记赋值9从哪里开始 // 设置为这个默认值,为了防止第二个for循环在flag没有被赋值的情况下执行 int flag = strNum.size(); for (int i = strNum.size() - 1; i > 0; i--) { if (strNum[i - 1] > strNum[i] ) { flag = i; strNum[i - 1]--; } } for (int i = flag; i < strNum.size(); i++) { strNum[i] = '9'; } return stoi(strNum); }

🚩点此跳转到首行↩︎
参考博客
- 代码随想录
- letcode