一、通过索引进行优化
数据结构
Data Structure Visualizations 数据可视化效果展示

Binary Search Tree
插入数据可视化效果展示
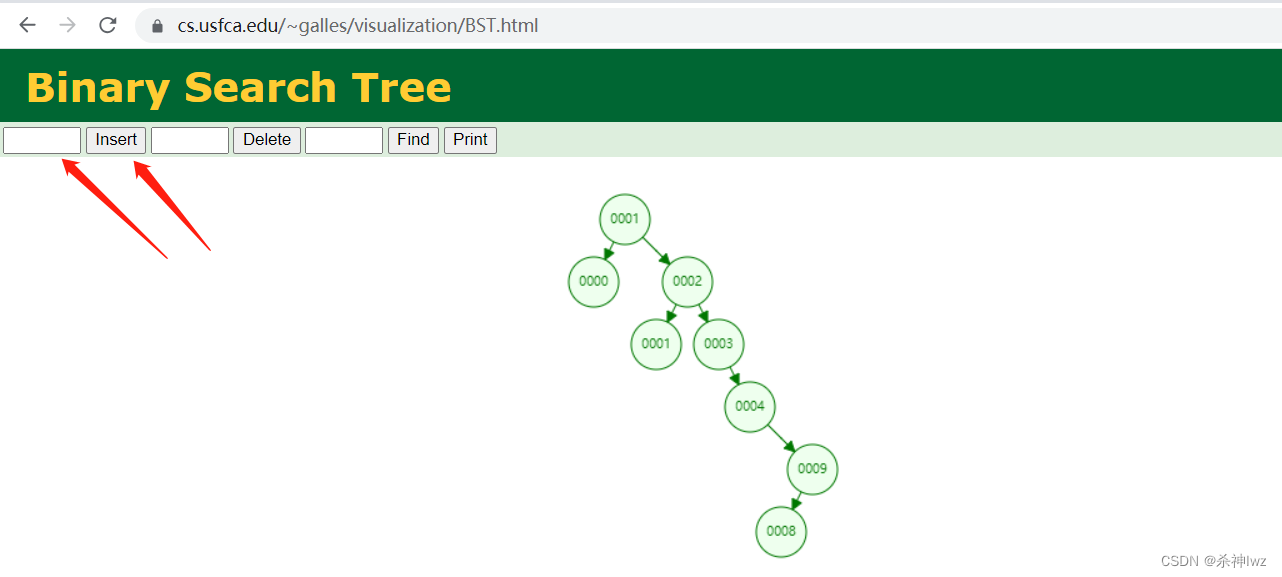
AVL Tree

Red/Black Tree

--MYISAM存储引擎数据和引用分开存储
DROP TABLE IF EXISTS `t_test`;
CREATE TABLE `t_test` (
`id` int(11) NOT NULL,
`test` varchar(9) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MYISAM;
--InnoDB
DROP TABLE IF EXISTS `t_test2`;
CREATE TABLE `t_test2` (
`id` int(11) NOT NULL,
`test` varchar(9) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
--查看数据存储路径
show variables like '%datadir%';
mysql> show variables like '%datadir%';
+---------------+---------------------------------------------+
| Variable_name | Value |
+---------------+---------------------------------------------+
| datadir | C:\ProgramData\MySQL\MySQL Server 8.0\Data\ |
+---------------+---------------------------------------------+
1 row in set, 1 warning (0.00 sec)
--MYISAM存储引擎有如下2个文件
t_test.MYD
t_test.MYI
--InnoDB存储引擎有如下1个文件
t_test2.ibd1、索引基本知识
索引的优点
1、大大减少了服务器需要扫描的数据量
2、帮助服务器避免排序和临时表
3、将随机io变成顺序io
索引的用处
1、快速查找匹配WHERE子句的行
2、从consideration中消除行,如果可以在多个索引之间进行选择,mysql通常会使用找到最少行的索引
3、如果表具有多列索引,则优化器可以使用索引的任何最左前缀来查找行
4、当有表连接的时候,从其他表检索行数据
5、查找特定索引列的min或max值
6、如果排序或分组时在可用索引的最左前缀上完成的,则对表进行排序和分组
7、在某些情况下,可以优化查询以检索值而无需查询数据行
索引的分类
主键索引
唯一索引
普通索引
全文索引
组合索引
技术名词
回表
覆盖索引
最左匹配
索引下推
索引采用的数据结构
哈希表
B+树
索引匹配方式
CREATE TABLE staffs (
id INT PRIMARY KEY auto_increment,
NAME VARCHAR ( 24 ) NOT NULL DEFAULT '' COMMENT '姓名',
age INT NOT NULL DEFAULT 0 COMMENT '年龄',
pos VARCHAR ( 20 ) NOT NULL DEFAULT '' COMMENT '职位',
add_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间'
) charset utf8 COMMENT '员工记录表';
ALTER TABLE staffs ADD INDEX idx_nap ( NAME, age, pos );
INSERT INTO staffs VALUES ('1', 'zhangsan', 30,'dev',now());
INSERT INTO staffs VALUES ('2', 'lisi', 36,'dev',now());
INSERT INTO staffs VALUES ('3', 'July', 23,'dev',now());
INSERT INTO staffs VALUES ('4', 'Mary', 30,'dev',now());
INSERT INTO staffs VALUES ('6', 'Maryz', 30,'dev',now());
INSERT INTO staffs VALUES ('7', 'July', 25,'dev',now());
INSERT INTO staffs VALUES ('8', 'July', 30,'dev',now());
mysql> show index from staffs;
+--------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+--------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| staffs | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | YES | NULL |
| staffs | 1 | idx_nap | 1 | NAME | A | 5 | NULL | NULL | | BTREE | | | YES | NULL |
| staffs | 1 | idx_nap | 2 | age | A | 7 | NULL | NULL | | BTREE | | | YES | NULL |
| staffs | 1 | idx_nap | 3 | pos | A | 7 | NULL | NULL | | BTREE | | | YES | NULL |
+--------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
4 rows in set (0.02 sec)全值匹配
--全值匹配指的是和索引中的所有列进行匹配
explain select * from staffs where name = 'July' and age = '23' and pos = 'dev';
mysql> explain select * from staffs where name = 'July' and age = '23' and pos = 'dev';
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 140 | const,const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)匹配最左前缀
--只匹配前面的几列
explain select * from staffs where name = 'July' and age = '23';
explain select * from staffs where name = 'July';
mysql> explain select * from staffs where name = 'July' and age = '23';
+----+-------------+--------+------------+------+---------------+---------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 78 | const,const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from staffs where name = 'July';
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 74 | const | 3 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)匹配列前缀
--可以匹配某一列的值的开头部分
explain select * from staffs where name like 'J%';
explain select * from staffs where name like '%y';
mysql> explain select * from staffs where name like 'J%';
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | range | idx_nap | idx_nap | 74 | NULL | 3 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from staffs where name like '%y';
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ALL | NULL | NULL | NULL | NULL | 7 | 14.29 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)匹配范围值
--可以查找某一个范围的数据
explain select * from staffs where name > 'Mary';
mysql> explain select * from staffs where name > 'Mary';
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | range | idx_nap | idx_nap | 74 | NULL | 2 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)精确匹配某一列并范围匹配另外一列
--可以查询第一列的全部和第二列的部分
explain select * from staffs where name = 'July' and age > 25;
mysql> explain select * from staffs where name = 'July' and age > 25;
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | range | idx_nap | idx_nap | 78 | NULL | 1 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)只访问索引的查询:也叫索引覆盖 Extra:Using index
--查询的时候只需要访问索引,不需要访问数据行,本质上就是覆盖索引
explain select name,age,pos from staffs where name = 'July' and age = 25 and pos = 'dev';
mysql> explain select name,age,pos from staffs where name = 'July' and age = 25 and pos = 'dev';
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------------+
| 1 | SIMPLE | staffs | NULL | ref | idx_nap | idx_nap | 140 | const,const,const | 1 | 100.00 | Using index |
+----+-------------+--------+------------+------+---------------+---------+---------+-------------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)MySQL官网提供数据结构案例
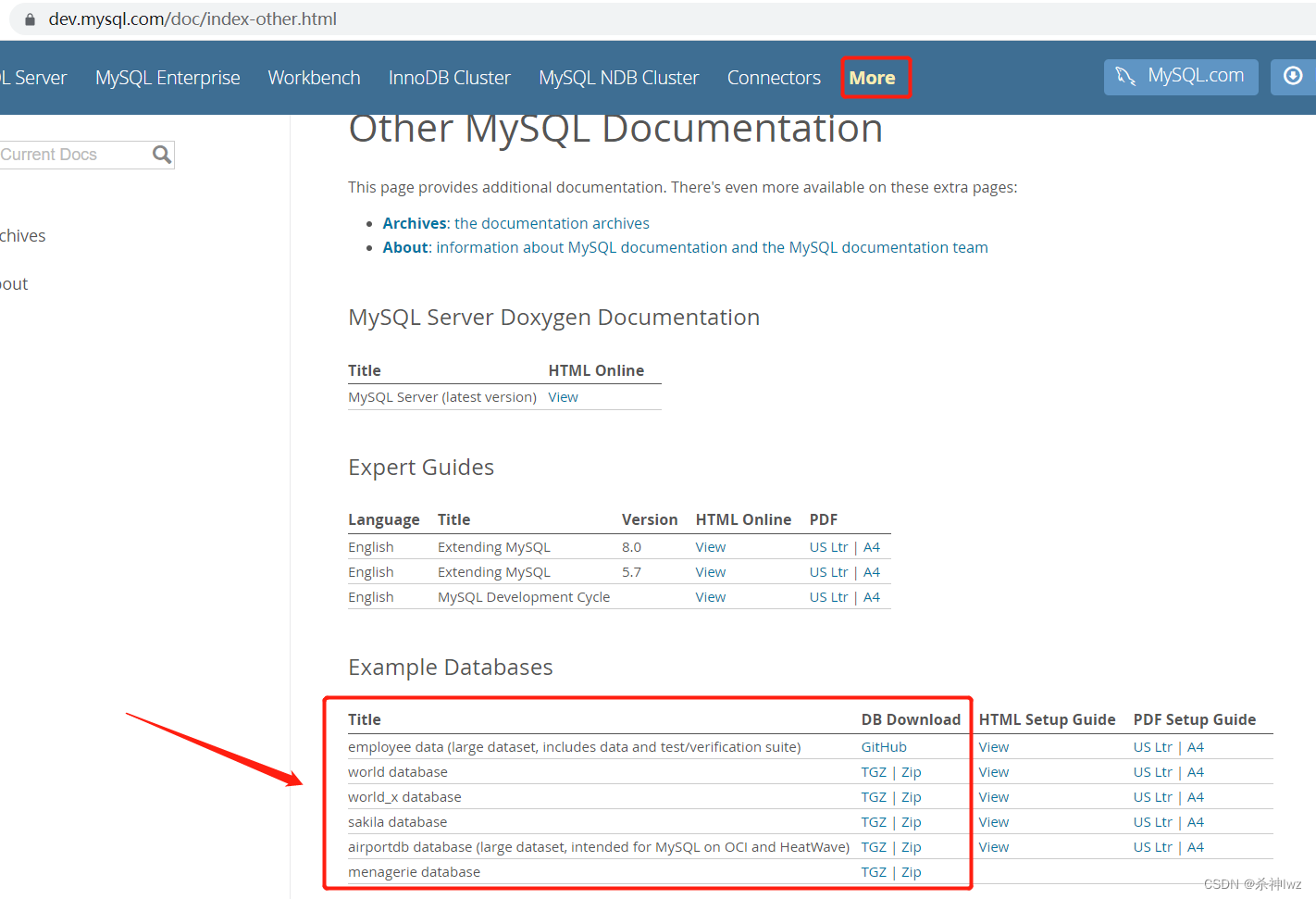
下载sakila database,执行SQL语句
--导入DB结构
mysql> source D:\.m2\sakila-db\sakila-schema.sql
Query OK, 0 rows affected (0.01 sec)
.....
--导入数据
mysql> source D:\.m2\sakila-db\sakila-data.sql
Query OK, 0 rows affected (0.00 sec)
Database changed
Query OK, 0 rows affected (0.00 sec)
...2、哈希索引
基于哈希表的实现,只有精确匹配索引所有列的查询才有效
在mysql中,只有memory的存储引擎显式支持哈希索引
哈希索引自身只需存储对应的hash值,所以索引的结构十分紧凑,这让哈希索引查找的速度非常快
哈希索引的限制
1、哈希索引只包含哈希值和行指针,而不存储字段值,索引不能使用索引中的值来避免读取行
2、哈希索引数据并不是按照索引值顺序存储的,所以无法进行排序
3、哈希索引不支持部分列匹配查找,哈希索引是使用索引列的全部内容来计算哈希值
4、哈希索引支持等值比较查询,也不支持任何范围查询
5、访问哈希索引的数据非常快,除非有很多哈希冲突,当出现哈希冲突的时候,存储引擎必须遍历链表中的所有行指针,逐行进行比较,直到找到所有符合条件的行
6、哈希冲突比较多的话,维护的代价也会很高
案例
当需要存储大量的URL,并且根据URL进行搜索查找,如果使用B+树,存储的内容就会很大
select id from url where url=""
也可以利用将url使用CRC32做哈希,可以使用以下查询方式:
select id fom url where url="" and url_crc=CRC32("")
此查询性能较高原因是使用体积很小的索引来完成查找
CRC(Cyclic Redundancy Check)校验实用程序库在数据存储和数据通讯领域,为了保证数据的正确,就不得不采用检错的手段。在诸多检错手段中,CRC是最著名的一种。CRC的全称是循环冗余校验。
CRC的本质
是模-2除法的余数,采用的除数不同,CRC的类型也就不一样。通常,CRC的除数用生成多项式来表示。最常用的CRC码的生成多项式如表1所示。最常用的CRC码及生成多项式名称生成多项式
CRC-12CRC-16
CRC-CCITT
CRC-32
由于CRC在通讯和数据处理软件中经常采用,笔者在实际工作中对其算法进行了研究和比较,总结并编写了一个具有最高效率的CRC通用程序库。该程序采用查表法计算CRC,在速度上优于一般的直接模仿硬件的算法,可以应用于通讯和数据压缩程序。
MySQL Optimization Learning(一)
MySQL Optimization Learning(二)
不断学习才能不断提高!
生如蝼蚁,当立鸿鹄之志,命比纸薄,应有不屈之心。
乾坤未定,你我皆是黑马,若乾坤已定,谁敢说我不能逆转乾坤?
努力吧,机会永远是留给那些有准备的人,否则,机会来了,没有实力,只能眼睁睁地看着机会溜走。