ETL是英文Extract-Transform-Load的缩写,用来描述将数据从源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,它能够对各种分布的、异构的源数据(如关系数据)进行抽取,按照预先设计的规则将不完整数据、重复数据以及错误数据等“脏"数据内容进行清洗,得到符合要求的“干净”数据,并加载到数据仓库中进行存储,这些“干净”数据就成为了数据分析、数据挖掘的基石。
ETL是实现商务智能(Business Intelligence,BI)的核心。一般情况下,ETL会花费整个BI项目三分之一的时间,因此ETL设计得好坏直接影响BI项目的成败。
企业中常用的ETL实现有多种方式,常见的方式如下。
(1)借助ETL工具(如Pentaho Kettle、Informatic等)。
(2)编写SQL语句。
(3)将ETL工具和SQL语句结合起来使用。
上述3种实现方式各有利弊,其中第1种方式可以快速建立ETL工程,屏蔽复杂的编码任务、加快速度和降低难度,但是缺少灵活性:第2种方式使用编写SQL语句的方式优占是灵活,可以提高ETL的运行效率,但是编码复杂,对技术要求比较高;第3种方式综合了前面两种方法的优点,可以极大地提高ETL的开发速度和效率。
ETL体系结构
ETL主要是用来实现异构数据源数据集成的。多种数据源的所有原始数据大部分未作修改就被载人ETL,因而,无论数据源在关系型数据库、非关系型数据库,还是在外部文件.集成后的数据都将被置于数据库的数据表或数据仓库的维度表中,以便在数据库内或数据仓库中作进一步转换(因此,一般会将最终的数据存储到数据库或者数据仓库中)。ETL的体系结构如图下所示。
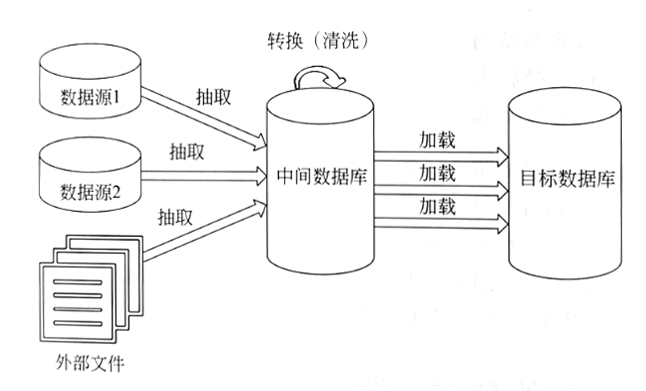
ETL体系结构
在上图中,若数据源1和数据源2均为功能较强大的DBMS(数据库管理系统),则可以使用SQL语句完成一部分数据清洗工作。但是,如果数据源为外部文件,就无法使用SQL语句进行数据清洗工作了,只能直接从数据源中抽取出来,然后在数据转换的时候进行数据清洗的工作。因此,数据仓库中的数据清洗工作主要还是在数据转换的时候进行。清洗好的数据将保存到目标数据库中,用于后续的数据分析、数据挖掘以及商业智能。
怎样学习ETL
为了让你了解ETL开发,同时使用Python语言来完成ETL任务,综合运用Python高级和MySQL数据库,黑马程序员推出了免费的Python+ETL课程。在下面的路线图中,你不仅能学到ETL,还能学到更多的大数据知识。