文章目录
- 什么是图像嵌入?
- 来自 Kaggle 的狗品种图像数据集
- 从狗品种图像数据集生成图像嵌入
- 参考
什么是图像嵌入?
图像嵌入是图像的低维表示。换句话说,它是图像的密集向量表示,可用于分类等许多任务。
例如,这些深度学习表示有时用于创建搜索引擎,因为它依赖于图像相似性。事实上,要找到一类图像(例如狗),我们只需要找到最接近狗图像向量的嵌入向量。
找到这些的一个好方法是计算嵌入之间的余弦相似度。相似的图像在嵌入之间将具有较高的余弦相似度。
来自 Kaggle 的狗品种图像数据集
对于这个例子,我们将使用我最喜欢的数据集之一:Kaggle Dog Breed Images 🐶
首先,我们需要下载这个数据集:
!export KAGGLE_USERNAME="xxxx" && export KAGGLE_KEY="xxxx" && mkdir -p data && cd data
&& kaggle datasets download -d eward96/dog-breed-images
&& unzip -n dog-breed-images.zip && rm dog-breed-images.zip
让我们看看这个数据文件夹中有什么:

这里我们有 10 种不同品种的狗:bernese_mountain_dog、chihuahua、dachshund、jack_russell、pug、border_collie、corgi、golden_retriever、labrador、siberian_husky。
import glob
data_dir = 'data'
list_imgs = glob.glob(data_dir + "/**/*.jpg")
print(f"There are {len(list_imgs)} images in the dataset {data_dir}")
=> 数据集中有918张图像。
以下示例展示了如何从狗品种文件夹创建 Deep Lake 数据集并将其存储在 Deep Lake 云中。
为了创建数据集,我们使用了 torchvision 模块:数据集和转换,以及 torch.utils.data.DataLoader:
from torchvision import datasets, transforms
import torch
# create dataloader with required transforms
tc = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor()
])
image_datasets = datasets.ImageFolder(data_dir, transform=tc)
dloader = torch.utils.data.DataLoader(image_datasets, batch_size=10, shuffle=False)
print(len(image_datasets)) # returns 918
我们有一个调整大小和批处理的数据集加载器可供使用。
注意:Pytorch 默认的图像后端是 Pillow,当您使用 ToTensor() 类时,PyTorch 会自动将所有图像转换为 [0,1],因此无需在此处标准化图像。
如果我们想要可视化该数据集中的第一张图像:
for img, label in dloader:
print(np.transpose(img[0], (1,2,0)).shape)
print(img[i])
plt.imshow((img[i].detach().numpy().transpose(1, 2, 0)*255).astype(np.uint8))
plt.show()
i = i + 1
break

从狗品种图像数据集生成图像嵌入
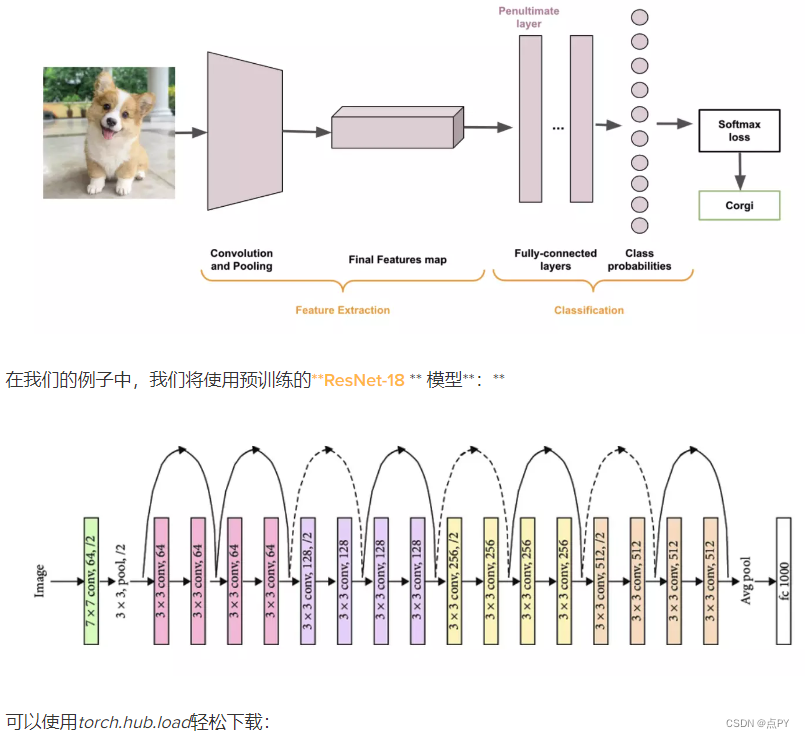
为了生成图像嵌入,我们将使用预训练的模型直到分类前的最后一层,也称为倒数第二层。
CNN(卷积神经网络)的第一层提取输入图像的特征,然后全连接层处理分类并返回类别概率,然后将其传递给 softmax 损失,例如,它将确定哪个类别具有最高的概率概率得分:
# fetch pretrained model
model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet18', pretrained=True)
现在我们需要选择要从中提取特征的层。如果我们再看一下 ResNet-18 的架构:

我们可以看到最后一层是 fc 层(全连接),其中对特征进行分类。我们想要CNN 分类部分之前的特征,因此,我们想要第一个全连接层,即 fc 之前的层:avgpool层。
我们可以使用模型对象选择该层:
# Select the desired layer
layer = model._modules.get('avgpool')
然后,我们使用register_forward_hook模块来获取嵌入:
def copy_embeddings(m, i, o):
"""Copy embeddings from the penultimate layer.
"""
o = o[:, :, 0, 0].detach().numpy().tolist()
outputs.append(o)
outputs = []
# attach hook to the penulimate layer
_ = layer.register_forward_hook(copy_embeddings)
注意:每次forward()计算出输出后都会调用函数copy_embeddings并将其保存在列表ouputs中。
然后,我们需要建模为推理模式:
model.eval() # Inference mode
让我们使用这个模型为我们的狗品种图像生成嵌入:
# Generate image's embeddings for all images in dloader and saves
# them in the list outputs
for X, y in dloader:
_ = model(X)
print(len(outputs)) #returns 92
由于dloader是批处理的,我们需要展平输出:
# flatten list of embeddings to remove batches
list_embeddings = [item for sublist in outputs for item in sublist]
print(len(list_embeddings)) # returns 918
print(np.array(list_embeddings[0]).shape)) #returns (512,)
正如预期的那样,新的展平列表 list_embeddings 的长度等于 918,这是我们在此狗品种数据集中拥有的图像数量。另外,列表 list_embeddings 中第一项的形状是 (512,),它对应于 avgpool 层输出的形状。
参考
https://www.activeloop.ai/resources/generate-image-embeddings-using-a-pre-trained-cnn-and-store-them-in-hub/