第 10 章 泛型算法与 Lambda 表达式
1. 泛型算法
1.1 泛型算法: 可以支持多种类型的算法。
int x[100];
std::sort(std: : begin(x), std : :end(x));
1.11 这里重点讨论 C++ 标准库中定义的算法: <algorithm > <numeric> <ranges>
1.12 为什么要引入泛型算法而不采用方法的形式?
1、 内建数据类型不支持方法
2、计算逻辑存在相似性,避免重复定义
1.13 如何实现支持多种类型:使用迭代器作为算法与数据的桥梁
1.2 泛型算法通常来说都不复杂,但优化足够好
1.3 一些泛型算法与方法同名,实现功能类似,此时建议调用特定方法而非算法:
– std::find() V.S. std::map::find()
1.4 泛型算法的分类
– 读算法:给定迭代区间,读取其中的元素并进行计算 :accumulate() / find() / count()
//版本一
template<class InputIt, class T>
constexpr // sinceC++20
T accumulate( InputIt first, InputIt last,T init)
{
for (; first != last; ++first) {
init= std ::move(init) + *first; // std::move since C++20
}
return init;
}
//版本二:
templatecclass InputIt, class T, class BinaryOperation>
constexpr // since C++20
T accumulate(InputIt first, InputIt last,T init, BinaryOperation op)
{
for (; first != last; ++first) {
init = op(std : : move(init),*first); // std : :move since C++20
}
return init;
}
– 写算法:向一个迭代区间中写入元素: 单纯写操作: fill() / fill_n()
– 读 + 写操作: transform() / copy()
template<class InputIt,class 0utputIt,class Unary0peration>
outputIt transform(InputIt firstl,InputIt last1,outputIt d_first, Unary0peration unary_op)
while (first1 != last1) {
*d_first++ = unary_op(*first1++);
}
return d_first;
}
● 注意:写算法一定要保证目标区间足够大!
std: :vector<int> x(10);
std:: fill_n(x.begin(), 100,3); //越界未定义
– 排序算法:改变输入序列中元素的顺序 sor()) / unique()(获取有序区间,只保留一个重复元素)
template<class ForwardIt>
ForwardIt unique( ForwardIt first,ForwardIt last)
{
if (first == last)
return last;
ForwardIt result = first;
while (++first != last) {
if( ! (*result == *first) && ++result != first) {
*result = std ::move(*first);
}
}
return ++result;
}
结果:
加入删除重复后的代码:
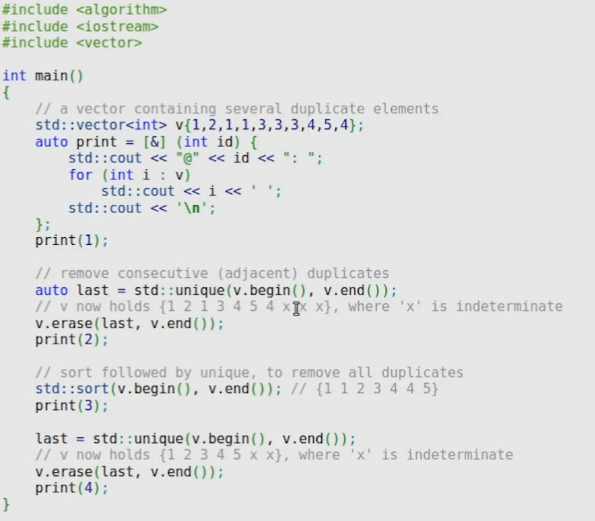
结果:
1.5 泛型算法使用迭代器实现元素访问
1.6 迭代器的分类:
– 输入迭代器:可读,可递增 典型应用为 —— find() 算法,用于在一个容器中查找指定值的元素:
template <class InputIt, class T>
InputIt find(InputIt first, InputIt last, const T& value);
– 输出迭代器:可写,可递增 典型应用为 —— copy()算法:用于将一个容器中的元素复制到另一个容器中。
template <class InputIt, class OutputIt>
OutputIt copy(InputIt first, InputIt last, OutputIt d_first);
– 前向迭代器:可读写,可递增 典型应用为 —— replace() 算法,用于在一个容器中将指定值的元素替换为新的值:
template <class ForwardIt, class T>
void replace(ForwardIt first, ForwardIt last, const T& old_value, const T& new_value);
– 双向迭代器:可读写,可递增递减 典型应用为 —— reverse() 算法,用于反转容器中元素的顺序:
template <class BidirectionalIt>
void reverse(BidirectionalIt first, BidirectionalIt last);
– 随机访问迭代器:可读写,可增减一个整数 典型应用为 —— sort()算法
● 一些算法会根据迭代器类型的不同引入相应的优化:如 distance 算法,用于计算两个迭代器之间的距离(元素个数),返回迭代器 first 和 last 之间的距离(last 减去 first 的差值):
template <class InputIt>
typename iterator_traits<InputIt>::difference_type distance(InputIt first, InputIt last);
1.7 一些特殊的迭代器:
– 插入迭代器: back_insert_iterator() / front_insert_iterator() / insert_iterator()
– 流迭代器: istream_iterator()输入 / ostream_iterator()输出
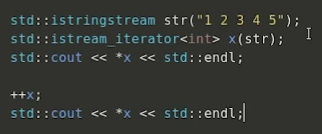
结果:
1
2
– 反向迭代器:rbegin() / rend()
示意图 :
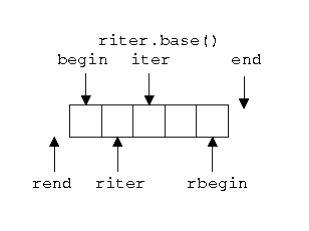
反向迭代器+输出流迭代器:

输出:

– 移动迭代器: move_iterator()

会读一次,但是容器中的元素还会被移动掉(没了)。
1.8 迭代器与哨兵( Sentinel )
在C++中,迭代器和哨兵是用于在容器中访问元素的两种不同方式。
迭代器是一种对象,它允许你在容器中遍历和访问元素。你可以将迭代器视为指向容器元素的指针。迭代器可以用于遍历容器中的元素,执行插入、删除和修改等操作。
哨兵是一种特殊的迭代器值,它并不指向容器中的任何元素,而是用于表示遍历的结束。当你使用迭代器遍历容器时,你可以将哨兵作为终止条件来判断是否到达了容器的末尾。
迭代器和哨兵在C++标准库中被广泛使用,尤其是在容器类(例如vector、list、set等)中。通过使用迭代器和哨兵,你可以以一种通用的方式对不同类型的容器进行遍历和操作,而不需要关心底层容器的具体实现细节。
下面是一个使用迭代器和哨兵遍历vector容器的简单示例:
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
// 使用迭代器遍历容器
for (std::vector<int>::iterator it = vec.begin(); it != vec.end(); ++it) {
std::cout << *it << " ";
}
return 0;
}
在上面的示例中,vec.begin()返回一个指向vector容器第一个元素的迭代器,vec.end() 返回一个指向vector容器最后一个元素之后的位置的迭代器(即哨兵)。 通过使用迭代器遍历容器,我们可以输出vector中的所有元素。
需要注意的是,C++11引入了更方便的迭代器语法,即使用范围-based for循环。可以简化上面示例中的迭代器遍历部分:
for (const auto& element : vec) {
std::cout << element << " ";
}
这样可以更简洁地遍历容器中的元素,而不需要显式使用迭代器和哨兵。
1.9 并发算法( C++17 / C++20 )
std::execution::seq、std::execution::par、std::execution::par_unseq和std::execution::unseq是C++17中引入的四种执行策略,用于指定算法的执行方式。它们与并行算法和顺序算法有关。
-
std::execution::seq(顺序执行策略):该策略指定算法在单个线程上按顺序执行。它适用于不需要并行化的算法,或者在某些情况下,使用并行化可能会导致错误或性能下降。 -
std::execution::par(并行执行策略):该策略指定算法在多个线程上并行执行。算法可以尝试并行化操作以提高性能。使用此策略时,算法应该是无副作用的(没有竞争条件或依赖关系),以确保并行执行的正确性。 -
std::execution::par_unseq(并行非顺序执行策略):该策略指定算法在多个线程上并行执行,并且可以使用非顺序执行(例如乱序执行)。这意味着算法可以在并行执行的同时,无需保持原始的顺序。这对于可以并行化且不依赖顺序的算法是有益的,但需要注意的是,结果的顺序可能与输入不同。 -
std::execution::unseq(非顺序执行策略):该策略指定算法可以以非顺序方式执行,但不一定并行化。这个策略通常适用于那些可以在单个线程上进行向量化或优化的算法。
这些执行策略可以在支持并行算法的标准库算法中使用,例如std::for_each、std::transform、std::reduce等。通过指定适当的执行策略,可以根据算法的要求选择适当的并行性和顺序性,以达到最佳性能。
以下是一个简单的示例,展示了使用std::execution::par和std::execution::seq执行策略的区别:
#include <iostream>
#include <algorithm>
#include <vector>
#include <execution>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
// 使用 std::execution::par 并行执行算法
std::for_each(std::execution::par, numbers.begin(), numbers.end(), [](int num) {
std::cout << num << " ";
});
std::cout << std::endl;
// 使用 std::execution::seq 顺序执行算法
std::for_each(std::execution::seq, numbers.begin(), numbers.end(), [](int num) {
std::cout << num << " ";
});
std::cout << std::endl;
return 0;
}
在上面的示例中,std::for_each算法用于遍历容器中的元素,并对每个元素执行lambda函数。通过指定不同的执行策略,可以选择并行执行或顺序执行。
使用std::execution::par并行执行策略时,输出的结果可能是无序的,因为算法在多个线程上并行执行,输出顺序不确定。例如,可能的输出为:
Copy code
3 5 1 2 4
使用std::execution::seq顺序执行策略时,输出的结果是有序的,因为算法在单个线程上按顺序执行。输出的顺序与容器中元素的顺序一致。例如,可能的输出为:
Copy code
1 2 3 4 5
2. bind 与 lambda 表达式
● 很多算法允许通过可调用对象自定义计算逻辑的细节
– transform / copy/copy_if / sort…
● 如何定义可调用对象
– 函数指针: 概念直观,但定义位置受限,函数内部无法定义函数
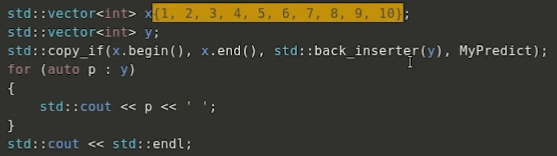
输出: 4 5 6 7 8 9 10
– 类: 功能强大,但书写麻烦
– bind :
基于已有的逻辑灵活适配,但描述复杂逻辑时语法可能会比较复杂难懂, 主要是通过绑定的方式修改可以调用的方式
● 早期的 bind 雏形: std::bind1st / std::bind2nd, 用于绑定第一/第二个参数,具有了 bind 的基本思想,但功能有限,
●std::bind ( C++11 引入):用于修改可调用对象的调用方式
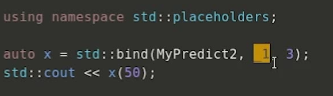
注释:50 作为可调用对象的MyPredict()函数的第为一个参数调用,依据_1或_2
确定此参数的位置
– 调用 std::bind 时,传入的参数会被复制,这可能会产生一些调用风险,可以尝试智能指针
– 可以使用 std::ref() 或 std::cref() 避免复制的行为
● std::bind_front ( C++20 引入): std::bind 的简化形式
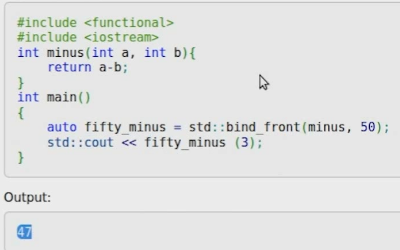
– lambda 表达式: 小巧灵活,功能强大
●lambda 表达式:
– 为了更灵活地实现可调用对象而引入
– C++11 ~ C++20 持续更新
● C++11 引入 lambda 表达式
● C++14 支持初始化捕获、泛型 lambda
● C++17 引入 constexpr lambda , *this 捕获
● C++20 引入 concepts ,模板 lambda
●lambda 表达式会被编译器翻译成类进行处理
●lambda 表达式的基本组成部分:
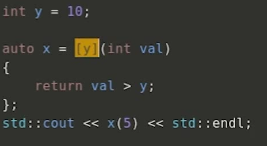
auto x = [](int val) { return val > 3; }; //注意末尾分号;
std::cout << x(5) << std::endl;
– 参数与函数体
– 返回类型:如有多分支return,类型需要一致,不然那auto推导不出来返回值类型
– 捕获:针对函数体中使用的局部自动对象进行捕获
● 值捕获、引用捕获与混合捕获
● this 捕获
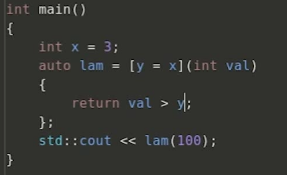
● 初始化捕获( C++14 )
●*this 捕获( C++17 )
捕获: 在内部修改不会改变外部值,属于值传递
this: 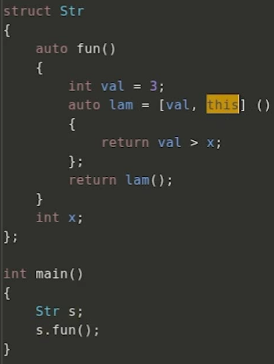
C++17:
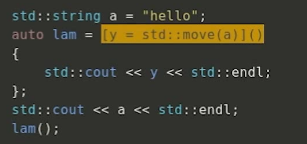
– 说明符
● mutable (可变)/ constexpr (C++17) / consteval (C++20)……
– 模板形参( C++20 )
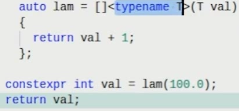
●lambda 表达式的深入应用
– 即调用函数表达式( Immediately-Invoked Function Expression, IIFE )
– 捕获时计算( C++14 )
– 使用 auto 避免复制( C++14 )
– Lifting ( C++14 )
– 递归调用( C++14 )
3. 泛型算法的改进——ranges
需要头文件 #include <ranges>( c++20)
std::vector<int> x{1, 2, 3, 4, 5};
auto it = std::ranges::find(x,3);
std::cout <*it<< std::endl;
● 可以使用容器而非迭代器作为输入
– 通过 std::ranges::dangling 避免返回无效的迭代器
● 引入映射概念,简化代码编写
● 引入 view ,灵活组织程序逻辑
● 从类型上区分迭代器与哨兵