以下说明:其中比喻都是以mysql为模板进行比较说明
一.lucene
1.jar包环境准备
<!-- 引入Lucene核心包及分词器包 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>4.10.3</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>4.10.3</version>
</dependency>
<!-- IK中文分词器 -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
3.
将项⽬⾃动⽣成的
application.properties
⽂件后缀改为
yml
类型。并添加数据库连接配置。
server:
port: 9000
Spring:
application:
name: yx-lucene
datasource:
# driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/es_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC
username: root
password: 123
# 开启驼峰命名匹配映射
mybatis:
configuration:
map-underscore-to-camel-case: true二。代码如下
package com.example.demo.test;
import com.example.demo.pojo.JobInfo;
import com.example.demo.sercice.JobInfoService;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.*;
import org.apache.lucene.index.*;
import org.apache.lucene.search.*;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
import java.io.IOException;
import java.util.List;
@SpringBootTest
public class LuceneTests {
@Autowired
private JobInfoService jobInfoService;
@Test
public void createIndex() throws IOException {
// 1.指定索引⽂件存储的位置
Directory directory = FSDirectory.open(new File("C:\\Users\\Lenovo\\Desktop\\java的复习\\四阶段\\Elasticsearch课前资料\\文档"));
// 2.配置版本和分词器
// Analyzer analyzer = new StandardAnalyzer(); // 标准分词器默认提供的
IKAnalyzer analyzer = new IKAnalyzer(); //中文的Ik分词器
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST,analyzer);
// 3.创建⼀个⽤来创建索引的对象IndexWriter
//参数1:表示索引文件的目标位置,参数2表示按哪个分词器写出数据
IndexWriter indexWriter = new IndexWriter(directory,config);
indexWriter.deleteAll(); // 先删除索引
// 4.获取原始数据
List<JobInfo> jobInfoList = jobInfoService.selectAll();
// 有多少的数据就应该构建多少lucene的⽂档对象document
for (JobInfo jobInfo : jobInfoList) {
Document document = new Document();
// 域名、值、源数据是否存储 Yes表示永久在索引库中存储,No:表示不永久保存
document.add(new LongField("id", jobInfo.getId(), Field.Store.YES));
document.add(new TextField("companyName", jobInfo.getCompanyName(), Field.Store.YES));
document.add(new TextField("companyAddr", jobInfo.getCompanyAddr(), Field.Store.YES));
document.add(new TextField("companyInfo", jobInfo.getCompanyInfo(), Field.Store.YES));
document.add(new TextField("jobName", jobInfo.getJobName(), Field.Store.YES));
document.add(new TextField("jobAddr", jobInfo.getJobAddr(), Field.Store.YES));
document.add(new TextField("jobInfo", jobInfo.getJobInfo(), Field.Store.YES));
document.add(new IntField("salaryMin", jobInfo.getSalaryMin(), Field.Store.YES));
document.add(new IntField("salaryMax", jobInfo.getSalaryMax(), Field.Store.YES));
document.add(new StringField("url", jobInfo.getUrl(), Field.Store.YES));
document.add(new StringField("time", jobInfo.getTime(), Field.Store.YES));
// StringField不需要分词时使⽤,举例:url、电话号码、身份证号
indexWriter.addDocument(document);
}
// 必须要关闭资源
indexWriter.close();
}
@Test
public void queryIndex() throws IOException {
// 1.指定索引⽂件存储的位置
Directory directory = FSDirectory.open(new File("C:\\Users\\Lenovo\\Desktop\\java的复习\\四阶段\\Elasticsearch课前资料\\文档"));
// 2.创建⼀个⽤来读取索引的对象IndexReader
IndexReader indexReader = DirectoryReader.open(directory);
// 3.创建⼀个⽤来查询索引的对象IndexSearcher
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 使⽤term查询:指定查询的域名和关键字
// 使⽤"北京"关键词搜索没有符合的结果
Query query = new TermQuery(new Term("companyName", "北京"));
// Query query = new TermQuery(new Term("companyName", "北"));
// 第⼆个参数:最多显示多少条数据
TopDocs topDocs = indexSearcher.search(query, 100);
int totalHits = topDocs.totalHits;
// 查询的总数量
System.out.println("符合条件的总数:" + totalHits);
System.out.println("maxScore="+topDocs.getMaxScore());
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
// 获取命中的⽂档,存储的是⽂档的id
for (ScoreDoc scoreDoc : scoreDocs) {
int docID = scoreDoc.doc; // 根据id查询⽂档
Document document = indexSearcher.doc(docID);
System.out.println( "id: " + document.get("id"));
System.out.println( "companyName: " + document.get("companyName"));
System.out.println( "companyAddr: " + document.get("companyAddr"));
System.out.println( "jobName: " + document.get("jobName"));
System.out.println("----------------------------------------------");
}
}
}三.解析代码


二.Kibana(重点)
使⽤Kibana对索引库操作
所有⽂档在写⼊索引前都将被分析,⽤户可以设置⼀些参数,决定如何将输⼊⽂本分割为词条,哪些词条应该被过滤掉,或哪些附加处理有必要被调⽤(⽐如移除HTML标签)。这就是映射扮演的⻆⾊,存储分析链所需的所有信息。Elasticsearch也是基于Lucene的全⽂检索库,本质也是存储数据,很多概念与MySQL类似的。对⽐关系:



settings:就是索引库设置,其中可以定义索引库的各种属性,⽬前我们可以不设置,都⾛默认。
索引库可以理解为mysql的数据库
1.使⽤Kibana创建索引库
PUT / 索引库名
查看索引库
GET请求可以帮我们查看索引信息,语法格式:
GET / 索引库名
查询
my_ip_addr
索引库中的数据。
GET /库名 / _search
删除索引库
删除索引使⽤
DELETE
请求。语法格式
DELETE / 索引库名
2.类型及映射操作(相当于对数据库中表的操作)
创建字段映射(创建表)

属性描述如下
查看映射关系 (换成mysql相当于获取到库里面所有表的字段信息)
GET / 索引库名 / _mapping
查看某个索引库中的所有类型的映射(相当于查询具体表的字段信息)
GET / 索引库名 / _mapping / 类型名
一次性创建索引库和类型
1.直接制定索引库中的类型, 基本语法⻅下:

新增⽂档(表数据)
1.新增⽂档(表数据)并随机⽣成id

2. 新增⽂档(表数据)并⾃定义id

3.1查看文档(表数据)
GET /索引名(数据库名) /表名 /数据Id
3.2查看文档(表)所有数据
GET /索引名(数据库名)/表名/_source
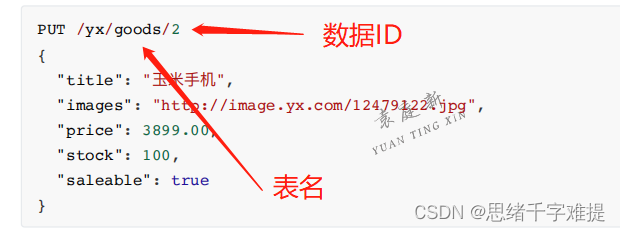
4.修改数据
PUT
表示修改⽂档。不过修改必须指定
id
。分为以下两种情况:
如果
id
对应的⽂档存在,则修改。
如果
id
对应的⽂档不存在,则新增。
(这里想吐槽下,如果你不是随机生成ID的画直接用put来新增和修改,put岂不是能代替post)
5.删除数据
删除使⽤
DELETE
请求,同样需要根据
id
进⾏删除。语法格式:
DELETE / 索引库名 / 类型名 / id 值
删除数据出错问题
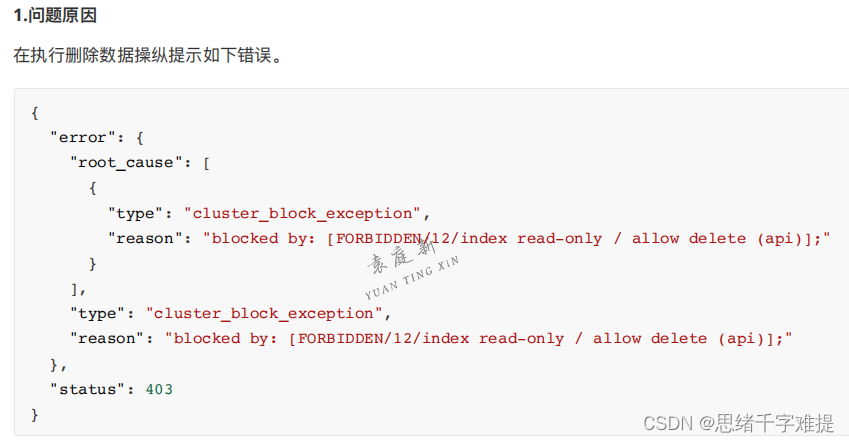
经查阅资料发现,此问题是由于ES数据存储磁盘剩余空间过少导致的。即ES存在⼀种flood_stage的机制。默认的 磁盘空间设置为95%,当磁盘占⽤超过此值阈值时,将会触发flood_stage机制,ES强制将各索引
index.blocks.read_only_allow_delete设置为true,即ES索引均被设置为仅允许只读只删,不允许新增。
2.
解决⽅法
1.在kibana中执⾏以下命令。
PUT / yx / _settings{"index.blocks.read_only_allow_delete" : null}
说明:执⾏完以后,⽆需重启
2.
或者主机上直接执⾏如下命令。
curl -XPUT -H "Content-Type: application/json" http://localhost:9200/_all/_settings -d'{"index.blocks.read_only_allow_delete": null}'
curl - X PUT "localhost:9200/twitter/_settings?pretty" - H 'Content-Type:application/json' - d '{"index.blocks.read_only_allow_delete" : null}'
说明:以上两种⽅式⼆选其⼀。
6.智能判断
刚刚我们在新增数据时,添加的字段都是提前在类型中定义过的,如果我们添加的字段并没有提前定义过,能够成 功吗?
事实上
Elasticsearch
⾮常智能,你不需要给索引库设置任何
mapping
映射,它也可以根据你输⼊的数据来判断类型,动态添加数据映射
在对
subTitle
字段做数据初始化的时候,设置的是字符串类型数据,
ES
⽆法智能判断,它就会存⼊两种字段类型。
例如:
subtitle
:
text
类型
subtitle.keyword
:
keyword
类型
这种智能映射,底层原理是动态模板映射,如果我们想修改这种智能映射的规则,其实只要修改动态模板即可
7.动态模板
动态模板允许您更好地控制
Elasticsearch
如何在默认动态字段映射规则之外映射数据。通过将动态参数设置为
true 或runtime
,可以启⽤动态映射。然后,您可以使⽤动态模板定义⾃定义映射,这些映射可以应⽤于基于匹配条件 动态添加的字段
举例,我们可以把所有未映射的
string
类型数据⾃动映射为
keyword
类型

这样,未知的
string
类型数据就不会被映射为
text
和
keyword
并存,⽽是统⼀以
keyword
来处理
附上以上代码
PUT ytr
{
"mappings": {
"goods": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
}
},
"dynamic_templates": [
{
"strings": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword",
"index": false,
"store": true
}
}
}
]
}
}
}