目录
前言:
1 认识lambda
2 lambda语法
3 lambda的类型
4 lambda的底层
前言:
本篇讲解了C++11当中新添加的lambda语法,以及lambda的底层
1 认识lambda
lambda的出现方便了很多我们写程序的地方,例如下面这个样例,我们对一个自定义类型进行排序,如果没有lambda,我们就只能通过传入函数指针或则是仿函数的方式,如下:
struct Goods
{
string _name;
double _price;
int _evaluate;
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
void print()
{
cout << "name:" << _name << " price: " << _price << " evaluate:" << _evaluate << endl;
}
};
struct ComparePriceLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price;
}
};
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
void printGoods(vector<Goods>& v)
{
for (auto& e : v)
{
e.print();
}
}
void test1()
{
ComparePriceGreater compg;
ComparePriceLess compgl;
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };
//通过仿函数能够达到我们期望的比较方式
sort(v.begin(), v.end(), compg);
cout << "价格降序" << endl;
printGoods(v);
sort(v.begin(), v.end(), compgl);
cout << "价格升序" << endl;
printGoods(v);
}输出如下:

上述代码我们描述了一个商品,其中有价格也有评价以及商品名字,用于模拟我们平时看到的电商平台里面的商品,我相信大家脑海中是有相应的样式的,所以大伙一定是知道对于这些商品我们可以通过不同的方式来排序的,上面代码就实现了这个功能。
我这里采用的是仿函数的方式,可以看到,不管是升序排序还是降序排序我们都分别写了一个仿函数,有时候这个仿函数有很简单,写出这个仿函数感觉有点没有必要,而且有时我们是不想要额外想一个名字的,想名字太痛苦了。所以这个时候就能够用lambda来实现了(注意!我这里只是表示了lambda的场景,并不是说lambda比仿函数更好,实际上它们是同一个级别的东西,后续我会为大家体现的)。
所以根据上面的代码,我们将仿函数修改成为lambda:
struct Goods
{
string _name;
double _price;
int _evaluate;
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
void print()
{
cout << "name:" << _name << " price: " << _price << " evaluate:" << _evaluate << endl;
}
};
void printGoods(vector<Goods>& v)
{
for (auto& e : v)
{
e.print();
}
cout << "*************************************" << endl;
}
void test1()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,3 }, { "菠萝", 1.5, 4 } };
//通过lambda语法也能帮助我们完成这个功能
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool { return g1._price < g2._price; });
printGoods(v);
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool { return g1._price > g2._price; });
printGoods(v);
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool { return g1._evaluate < g2._evaluate; });
printGoods(v);
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool { return g1._evaluate > g2._evaluate; });
printGoods(v);
}
输出如下:
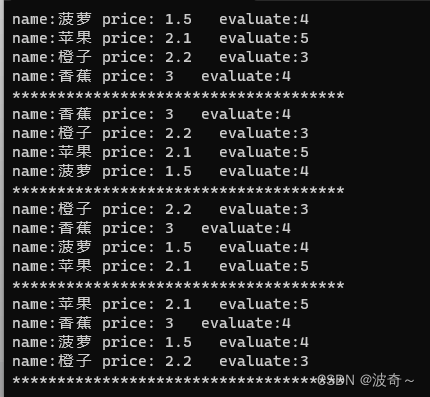
如上代码所示,我们的代码整体上看起来是不是更加轻松了?直接把lambda作为了sort的比较方式,然后传入。通过这样的方式相信大家也能看出来lambda实际上就是一个匿名函数。
2 lambda语法
通过上面的介绍,相信大家也见识到了lambda,接下来就来为大家展示一下lambda的语法格式,lambda由如下几个部分组成:
[]:捕捉列表,在lambda函数的最开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,并且这个列表回去捕捉上下文中的变量,然后用于lambda使用。
():参数列表,与函数的参数列表相同,有一点比较特别,那就是如果不需要传递参数,那么不仅不需要写参数如:int x,甚至()都可以不用写。
->returntype:返回值类型,如函数相同,当没有返回值可以不写,当返回值类型非常明确,也可以不写,编译器会推导。
{}:函数体,也就是我们写函数时需要用{}包起来的部分。
mutable:默认条件下,lambda总是有一个const特性,我们可以通过mutable取消掉它的这个特性,并且加上mutable时,()不能省略。
相信大家看完上面的概念基本上是懵逼的,倒不是说不能理解,而是自己写不出来lambda,接下来就由博主带大家学习。
根据上面的概念,我们可以得知一个lambda有两个部分必须持有,那就是捕捉列表还有函数体,其余的都可以省略掉,那么我们就可以写下如下的一个最简单的lambda表达式:

当然这个玩意没啥实际意义,只是博主为了表示lambda最不可或缺的部分。接下来就是lambda的实际使用了,首先我们来实现一个Add函数:


大家先别管我为什么要用auto来接收lambda,只需要知道lambda是可以通过这种方式被接收的,相当于函数指针typedef一样,使用方式也是如此。只是单纯的看到这一份代码实际上它是没有什么难度的,只要掌握了lambda的写法捕捉列表,参数列表,返回值类型,函数体这样的顺序就行了。
add函数能够通过这样的方式实现,但是交换函数呢?还能这么写吗?请看代码:

这样的写法有问题吗?lambda接收x和y的值,然后通过临时对象帮助交换,看起来没有问题,那么输出一下请看?
![]()
看来有问题,lambda好像找不到我们lambda域外面的变量欸,事实上确实是这样,我们可以理解为lambda开辟了一个新的作用域,并且与写它的作用域区分开了,并且我们的传参方式是传参方式,也就是写函数时常见的形参的改变不影响实参,所以有一个很简单的解决方式,如下:

也就是传引用传参,答案也显而易见,那就是一定能够改变我们的x和y,如下:
![]()
但是除了这样还有什么别的方法吗?还有就是概念当中不是有提到过捕捉列表能够去查找上级作用域的变量供自己使用的吗?这又是怎么用的?别急,代码如下:
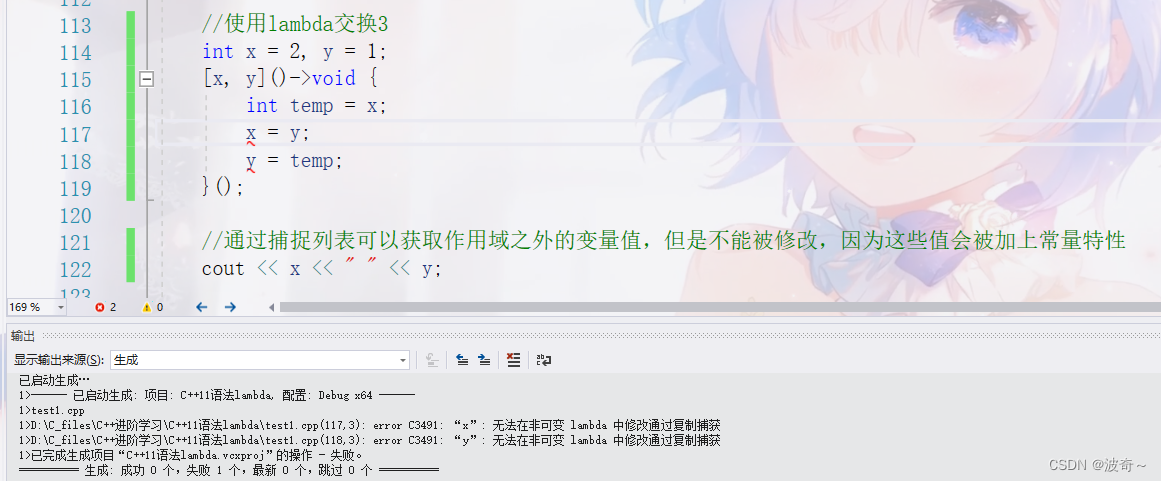
g,这下好咯,不仅x和y不能交换,甚至程序还出现问题了,那么这是什么原因呢?其实原因在输出里面已经为我们提示了,这个lambda是不可以修改的,也就表示了从上级作用域当中找到的变量只有可读的权限,不能修改,这下知道原因了,概念当中的mutable关键字的作用也出来了,那就是让我们的x和y能够被修改,代码如下:

如上代码,添加了mutable关键字之后,生成可执行程序是不会出错了,那么运行结果会是正确的吗?如下:
![]()
???,为什么呢?他不是已经找到了那个变量了吗?并且我也添加上了mutable关键字了哇?这怕不是玩我呢?这就涉及到捕捉列表比较特别的部分知识了,那就是捕捉列表当中获取到的数据也是原变量的一个拷贝,如果要使用原数据就需要在这个变量前面添加上&符号,注意这不是取地址的意思,而是引用这个变量,如下:

输出如下:
![]()
真是不容易,为了搞这么个玩意,不过为了知识,我忍了。
一下是关于捕捉列表的写法:
[=]() {}; //全部变量传值传参
[&]() mutable {}; //全部变量传引用传参
[=, &x]()mutable {};//接收所有变量,但只有x是引用传参
[&, x]() mutable {};//接收所有变量,单只有x是传值传参this不能直接写,需要在类里面才能使用
//[this]() {}; //在类里可以通过this,获取到this指针
class testclass
{
public:
void test100()
{
[this]() {
cout << this << endl;
}();
}
};
3 lambda的类型
学习了上面的lambda相信大家对于它的使用基本上是没有问题了,那么有个疑问,那就是为什么我的lambda函数要通过auto接收,它的类型是什么样子的?

请看到如下的代码,明明是两个完全相同的lambda,为什么二者却不能相互赋值呢?事实上,任何一个lambda的类型都不相同,请看如下代码以及输出:


相信这样的方式,大家就能理解为什么两个代码完全相同的lambda不能相互赋值了,毕竟两个的类型是不同的,我们的lambda有没有支持它们两个的转换,当然就不能够相互转换了。
但是虽然我们不能通过赋值的方式,但是却可以通过一个lambda去拷贝构造另外一个lambda,如下:


可以看到,f3是f1的拷贝,它们两个的类型也是一摸一样的,那么这是不是就意味着我们就可以赋值了?

并不行,而且通过上面的操作,我们也能猜出来lambda底层实现其实就是一个类,因为只有类有拷贝构造以及删除默认函数的操作。
并且就lambda而言他是可以通过函数指针的方式去接收的,但是由于这种方式在捕捉列表有参数时,是写不出来的,而且通过函数指针的方式接收破坏了lambda的特性我也就不为大家展示了,没有实际的意义。
4 lambda的底层
讲了这么多,那么lambda到底是怎么实现的?其实很简单,lambda的实现就像是范围for底层实际是迭代器一样,它的底层就是仿函数,别不行,咱现在就给你证明:
class Rate
{
public:
Rate(double rate) : _rate(rate)
{}
double operator()(double money, int year)
{
return money * year * _rate;
}
private:
double _rate;
};
void test5()
{
//对象
double rate = 0.49;
Rate r1(rate);
r1(100000, 5);
//lambda
auto r2 = [rate](double money, int year)->double {return money * year * rate; };
r2(100000, 5);
//不管是对象还是lambda,在底层上面都是先call一个对象,然后再call仿函数,也就是
//实际上lambda和范围for一样,实际只是底层封装了之后的产物
}这份代码我写了一个仿函数还有一个lambda,它们两个实现的是一摸一样的功能,大家学了lambda相信也不需要我解释了,那么我们 调试~ 启动!
仿函数的汇编代码:

lambda的汇编代码:

请看!有什么区别?唯一的区别那就是仿函数还有lambda的名字不同,其它的都是一模一样的,这下相信了吧。所以说其实lambda其实一点也不难,只要我们知道仿函数,那么一定能理解lambda。
以上就是博主对于lambda的全部理解了,希望能够帮助到大家。











![[RoarCTF 2019]Easy Calc1](https://img-blog.csdnimg.cn/img_convert/f1da9ac470e344d6a16bd357bc190052.png)