Java性能权威指南-总结22
- 对象序列化
- 追踪对象复制
- Java EE网络API
- 小结
对象序列化
追踪对象复制
先介绍一个示例,如何不对对象引用进行序列化,以避免在反序列化时处理对象引用。然而,writeobject()中最有力的优化是不重复输出对象引用。 在StockPriceHistoryImpl中,这意味着不重复输出prices map。因为示例采用标准JDK中的map,JDK的类已经对数据的序列化进行了优化,所以不用担心。不过,了解这些类如何进行优化、理解哪些可能的优化都是有益处的。
StockPriceHistoryImpl中的关键结构是TreeMap。下图是一个简化版本的map。JVM默认先序列化Node A的原生数据字段,然后递归调用Node B的writeobject()(接着是Node C)。Node B也会序列化它自己的原生数据字段,然后递归序列化它上级Node的字段。
但是请注意——Node B上级节点Node A已经被序列化,怎么办?对象序列化的代码很智能:它会意识到这一点,并且不会再次序列化Node A的数据。相反,它只会在先前序列化的数据中添加一个对象引用。追踪上一级对象从而递归所有对象,会对序列化的性能有少许影响。 但正如Point数组的例子所示,这是无法避免的:必须追踪上一级序列化的对象以便正确恢复对象引用。不过,可以通过压缩对象引用来进行智能优化,从而在对象反序列化时易于重建。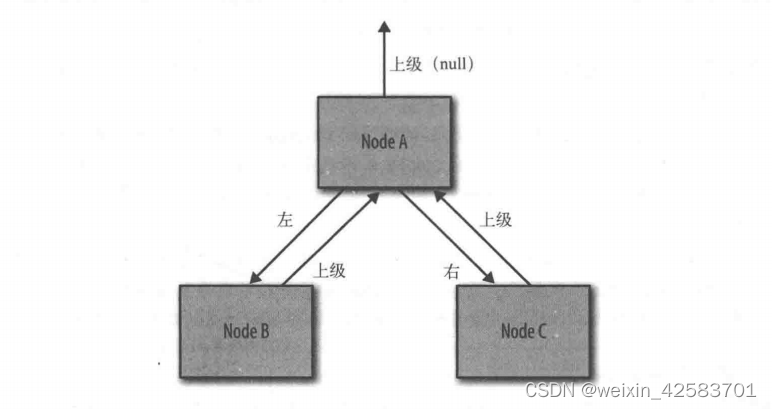
不同的集类处理这个问题的方式有所不同。比如TreeMap,它只是遍历树然后序列化键值,丢弃了键之间的所有关系(也就是它们的排列顺序)。在反序列化时,readobject()会重新排列数据并生成树。虽然排序对象听起来代价很昂贵,但实际并非如此:对10000只股票而言,整个过程要比默认的序列化快20%,默认机制需要追踪所有的对象引用。
需要序列化的对象减少了,因此TreeMap也能从优化中获益。map中的Node(在JDK中为Entry)包含两个对象:键和值。由于map不会包含两个相同的Node,所以序列化保留Node的对象引用时不用担心。在这种情况下,它不会序列化Node对象本身,而是直接序列化键和值。所以最终的writeObject()看起来像这样(为便于阅读,代码作了调整):
private void writeobject(ObjectoutputStream oos) throws IOException {
for (Map.Entry<K,V>e : entrySet()) {
oos.writeobject(e.getKey());
oos.writeObject(e.getValue());
}
}
这段代码看起来与Point示例中的那段不能正常工作的代码非常像。差别在于该段代码会序列化相同的对象。TreeMap不会有两个相同的Node,所以没有必要序列化Node引用。TreeMap可以有相同的值,所以值必须序列化成对象引用。这就回到了起点:正确优化对象序列化非常困难。但当对象序列化成为应用的主要瓶颈时,恰当地进行优化可以带来很大的益处。
关于Externalizable接口
这两个接口的差别在于它们如何处理非transient字段。当writeObject()调用defaultMriteObject()时,Serializable会序列化非transient字段。但Externa-lizable没有这样的方法。
Externalizable类必须显式序列化所有关注的字段,无论transient与否。
即便一个对象中的所有字段都是transient,也最好实现Serializable接口,并调用defaultMriteObject()方法。这使得代码在添加(移除)字段时更容易维护。从性能的角度来看,
Externalizable并没有特别的优点:最终影响性能的是数据量的大小。
快速小结
- 数据的序列化,特别是Java EE中的序列化,有可能是很大的性能瓶颈。
- 将变量标记为transient可以加快序列化,并减少传输的数据量。这些做法都可以极大地提高性能,除非接收方重建数据需要花费很长时间。
- 其他
writeobject()和readobject()方法的优化也可以显著加快序列化。但这容易出错,而且不留神就会引入不易察觉的bug。 - 通常在序列化时进行压缩都有益处,即便数据不在慢速网络上传输。
Java EE网络API
前面介绍过的几种数据交换技术——XML解析、JSON处理和对象序列化——可以在不同的应用中使用,但主要是在JAX-WS、JAX-RS和ⅡOP/RMI这三个Java EE网络API中使用。
这些API的协议差别很大,特性也有很大的不同。在决定为何使用它们以及何时使用它们时,考虑的首要因素就是它们的特性。关于它们有许多争论,比如JAX-RS是否比JAX-WS快,不过这些争论都假设有这样一个通用型应用,这个应用可以用两种框架编写。如果确定需要安全特性,那就应该选择JAX-WS,而不管它与JAX-RS相比性能如何。如果应用必须和已有的输出ⅡOP接口的服务器通信,那么选择也就显而易见了。但对于这几种网络API来说,它们需要克服的性能问题类似。这部分将讨论其中的一些困难以及如何处理这些困难。
调整传输数据的大小
影响这些技术性能的首要因素是数据交换。传输的数据量应该尽量小,无论是压缩或去冗,或者其他技术。另一方面,发起一次网络调用会有很显著的网络开销。 设计网络API时,应该设计成“粗粒度”的——也就是说,最好一次调用返回大量数据,使得客户端发起的网络调用总数最小。这个原则与减少数据交换量相违背,所以必须做些权衡。
可以在前面股票RESTful Web服务平均响应时间的测试中观察到这种平衡。可以将服务设计成只返回一段时期内的基本数据(最高价、最低价、平均价和标准差),也可以设计成在返回这些基本数据的同时再加上这期间每天的日数据。
如果预先知道客户端要如何使用数据,就能很容易且精确地知道会返回哪些数据。但是,实际情况并不总是这样。在这个例子中,比如说客户端请求某只股票5年的历史数据,那开始时客户端应用只会向用户展示概要数据。如果用户想深入了解数据,查看单个股票的日数据,那会发生什么?是否所有数据都应该在第一次调用中返回给客户端,使得查看详情时无需再次发起网络调用?是否应该只返回概要数据,而在用户想要了解某年详情时,程序才再次发起调用获得那年的日数据?是否第二次调用应该获取整个5年的历史数据,即便此时用户只想看第三年的数据?
为了确定此处该用哪种策略,可以比较一下返回全部数据的时间和多次网络调用的时间。下表显示了在不同场景下获取数据的平均响应时间。
- 客户端请求1年的数据。
- 客户端请求1年的概要数据。
- 客户端请求5年的数据。
- 客户端发起2次请求:先请求概要数据,然后进一步请求特定时间的详细数据。
- 客户端发起10个请求:1个概要请求,加上9个特定时间详细数据的请求。
这些测试是在宽带连接下进行的。毫无疑问,网络速度对报告的时间有巨大影响。
各种场景下RESTful的平均响应时间
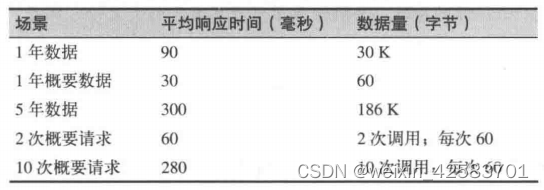
获取一整年完整数据的时间并不比只获取概要数据长太多,所以如果用户只需要获取其中的三个数据片段,那一次性返回整个数据集总是更好的选择。不过5年的概要数据有点不同:数据编组和发送所需的时间要长得多,所以在总时间达到平等前,用户需要发起11个获取详情的请求。
本例中的时间包括将RESTful服务返回的JSON数据编组的时间,这个时间取决于数据有多少年。但是多个客户端可能会请求相同的数据集,这种情况可以重用之前编好组的数据。如果编好组的数据已经计算好,响应时间的拐点就会有很大的不同,如下表所示:
各种场景下(响应有缓存)RESTful的平均响应时间

由于调用一次概要数据的开销基本不变,所以概要数据的响应时间差别很小。而获取1年和5年完整数据的时间只是在传输数据上,明显少于之前数据需要计算和编组的情况。一般来说,可以返回给客户端大量可能并不需要的数据,而没有太多性能上的损耗。
小结
Java EE应用的性能依赖于好几个因素。其中应用代码的质量永远是最主要的。而且,因为用到了许多外部资源,所以应用服务器的性能瓶颈通常并不在Java层。
许多影响应用服务器性能的因素并不只是针对Java EE——尤其是线程的性能、对象池和网络性能。对应用服务器而言,最重要的影响因素是它传输或处理的数据量——无论是简单的HTML,还是XML、序列化对象状态或JSON等。